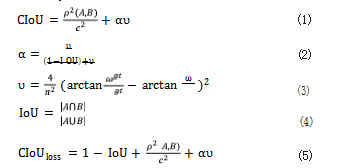SCI论文(www.lunwensci.com)
摘 要: 现有的 YOLOv5 模型无法精确检测出进入复杂施工现场内的人员佩戴安全帽问题,本文提出了一种基于 YOLOv5 的安全帽检测算法。模型的具体改进方法为 :在主干网络中新增了一个小目标层 P2 和 3-D 注意力机制 SimAM, 提 升算法的特征提取能力便于能够更容易检测出小目标 ;将边框损失函数 CIoU_Loss 改为 SIoU_Loss,以提升对小目标检测的 训练速度与精度,从而得到一种新的安全帽佩戴检测模型。实验结果显示,修改后的 YOLOv5s 算法大大提高了复杂工程现场 安全帽检测的准确率,较原有的算法提高了 1.4 个百分点,mAP 值达到了 95.5%。
Lmproved YOLOv5 in Safety Helmet Wearing Detection Algorithm
LI Weina, LI Shuang
(School of Statistics,Xi'an University of Finance and Economics, Xi'an Shaanxi 710100)
【Abstract】:Existing YOLOv5 models do not accurately detect the wearing of helmets by personnel entering complex construction sites. This study proposes a helmet detection algorithm based on YOLOv5. The specific improvement methods of the model include, in the backbone network, a small target layer P2 and 3-D attention mechanism SimAM are added to improve the feature extraction ability of the algorithm to make it easier to detect small targets. SIoU_Loss was used to replace the CIoU_Loss, to improve the recognition accuracy and speed of small target detection, so as to obtain a new helmet wearing detection model. Experimental results show that the modified YOLOv5s algorithm greatly improves the accuracy of safety helmet detection in complex engineering sites, which is 1.4 percentage points higher than the original algorithm, and the mAP value reaches 95.5 %.
【Key words】:YOLOv5;small object detection;attention mechanism;deep learning
0 引言
安全帽是一种重要的个人防护设备,它在不同的行 业中得到了广泛的应用,例如 :机械,建筑,矿山,化 工,交通,冶金,电力等 [1]。当头部受到打击、碰撞或 遭遇高空抛物时安全帽能够有效安全的保护头部,保护 工作人员的人身安全,所以在生产现场对安全头盔的佩 戴状况进行实时监测是非常重要的。
随着图像处理和深度学习的发展,基于目标检测 算法的安全帽佩戴检测可以分为两类,一类是以 CNN, FasterR-CNN,Mask RCNN 等算法为代表的两目标检 测算法,另一类是以 SSD 和 YOLO 系列为代表的单目标 检测算法。YOLO 模型于 2016 年由Joseph Redmon 等人提出,该模型可以将目标检测问题转化为回归问题, 可以从输入图像直接预测 Bounding box 和类别,显著 提升了模型的检测效率 [2]。2017 年提出了 YOLOv2 模 型,相对于 YOLO 构建新的主干网络 Darknet-19. 优化 了对物体的定位,从而在保证检测速度的情况下进一步 提升了目标检测的精度。2018 年提出了 YOLOv3 模型, 相比于 YOLOv2 增加了 10 多倍的预测框,提高了检测 的精度和对小目标的检测准确率。2020 年 Bochkovskiy 提出了 YOLOv4 模型选用 CSPDarknet-53 为骨干网络, 用 PANet 替代 YOLOv3 模型中的 FPN 算法,使算法检 测准确率得到了极大的改善 [2]。2020 年 Glenn Jocher 提出了 YOLOv5 模型,与 YOLOv4 模型的基本结构近似,依据模型的宽度和深度构建了 YOLOv5-N/S/M/L/ X 5 种模型 [2]。在 YOLO 系列模型的基础上,很多学 者对小目标检测问题进行了深入探讨,宋晓凤等人基 于 YOLOv5s 网络模型, 将 Backbone 中的残差块替换 成 Res2NetBlock 结构中的残差块,并引入 CA 坐标注 意力机制,得到了准确性更强检测速度更快的安全帽佩 戴检测算法 [3]。 吕宗喆 (2022) 基于 YOLOv5m 算法, 用 CIoU_Loss 代 替 GIoU_Loss, 用 BCE With Logits Loss 代替 Cross Entropy Loss, 将输入网络的图片进 行重叠切片,提升了密集场景下小目标检测识别的精度 和置信度 [4]。

本文提出了改进 YOLOv5s 的安全帽佩戴检测算法, 首先将坐标注意力机制 (Coordinate Attention) 加入 YOLOv5s 模型的骨干网络中,获得空间方向和空间角 度的权重,使目标检测定位更加精确,其次,为了能够 获得更好的预测框回归效果,将 CIoU 损失函数改进为 SIoU。
1 YOLOv5 模型
2020 年 Ultralytics 公司发布了以 Pytorch 框架为 基础的轻量级检测模型 YOLOv5 目标检测算法,该算法 有根据权重,模型的宽度和深度依次增加的 YOLOv5n、 YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x 这 5 个版本。 YOLOv5 将整个网络结构分成输入端 (input)、骨干网 路 (Backbone)、颈部 (Neck) 和输出层 (Head) 四个部 分。结合实际需求,平衡检测准确度和检测速度,最终 选用 YOLOv5s 作为基础检测模型。
1.1 输入端
在 YOLOv5s 模型中, 采用 640×640 大小的输入 数据,当输入图像尺寸越大,其包含的信息量就越多, 在掌握更多信息的前提下,可以更容易定位到目标,尤 其是对小目标的检出。同时,为了进一步强化模型的检 验精度, YOLOv5 在输入端添加了 Mosaic 数据增强机 制、自适应锚框计算和图片的自适应缩放等操作。
1.2 骨干网络
Backbone 中 包 括 Focus 结 构、Conv 模 块、C3 模块和 SPPF 模块。Focus 结构的核心是切片,将的图 像输入 Focus 中,经过切片操作后得到的特征图,将 其进行拼接后再经过一次卷积操作,形成最终的特征 图。Conv 模块封装了三个功能,包括卷积 (Conv2d)、 BN 和 Activate 函数。C3 模块是通过多次的 C3 结构 堆叠来达到特征维度降低的目的,使得图像的输入由变 成。SPPF 表示空间金字塔池化,该模块可以将任意尺 寸的特征图转化为一个固定尺寸的特征向量。
1.3 颈部
Neck 位于 Backbone 的后面,主要在上采样与下 采样的过程中达到深层次特征融合的效果, Neck 网络 采用特征金字塔 (FPN) 和路径聚合网络 (PAN) 相结合 的结构。其中 FPN 结构选择了自上向下的路径,将高 层语义特征与低层语义特征融合,而 PAN 结构选择了 完全相反的路径, FPN 结构中忽视掉的定位信息自底向 上的反补给 PAN 结构,有效解决了多尺度融合的问题。
1.4 输出层
在 YOLOv5 模 型 中,Bounding box 的损 失 函数 使用 CIoU_Loss,即预测框与真实框之间的误差损失, CIoU 在 IoU 的基础上计算预测框与真实框之间的欧氏 距离作为惩罚项,通过最小化欧氏距离的方式为预测框 提供移动方向,加快模型收敛 ;同时,增加了检测框尺 度损失,解决了预测框与真实中心重合时梯度无法有效 回传的弊端,其公式为 :
其中 A 为预测框, B 为目标框, ρ2 (A, B) 表示 A 与 B 之间的欧氏距离, c 为最小外接边界框对角线长度 ( 包 含 A、B 的最小矩形的对角线长度 ), ω 和 h 为预测框 的宽和高, ωgt 和 hgt 为目标框的宽和高, v 为衡量长宽 比一致性参数, α 为权重参数。
2 改进的 YOLOv5 小目标检测算法
2.1 增加小目标检测层
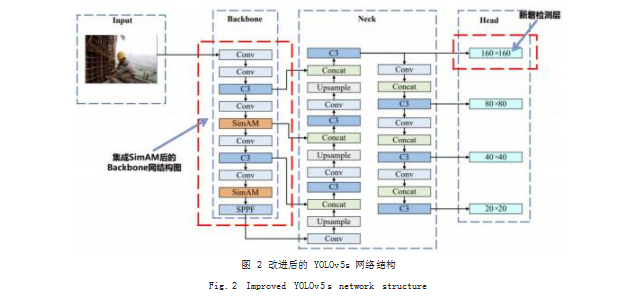
YOLOv5 小目标检测效果不好主要原因为小目标 尺寸问题,对于安全帽数据集来说,其目标较小,容易 漏检,因此在 YOLOv5 模型的基础上增加一个小目标 检测层。特征图尺度越大,检测小目标的能力越强,以 输入图像尺寸为 640×640 为例, 原 YOLOv5s 模型有 3 种不同尺度,输出的特征图尺寸分别为 80×80.用 于检测大小在 8×8 以上的小目标 ;40×40. 用于检测 尺寸大小在 16×16 以上的中等目标 ;20×20.用于检 测大小在 32×32 以上的大目标。针对小目标检测,本 文引入一个新的检测层 P2. 输出尺寸为 160×160 的 特征图,用于检测大小在 4×4 以上的小目标。最终改 进后的 YOLOv5s 模型有 4 种不同的检测尺度,分别为 (160×160),(80×80),(40×40),(20×20)。
2.2 添加注意力机制 (SimAM)
研究发现由于现有的注意力机制只能沿着通道或空 间维度细化特征,极大的限制了学习注意力权重的灵活 性, 并且结构过于复杂。Lingxiao Yang 等人在 2021 年提出了更加灵活并且保持轻量级模块化的 SimAM 注 意力机制 [5]。该机制不需要添加额外参数,从当前神经 元中直接推断同时考虑空间和通道维度的 3-D 权重,使 网络学习更具辨别力的神经元。
基于神经科学发现, SimAM 注意力机制为每个神 经元定义了动量函数 :
2.3 改进损失函数 (SIoU)
目标检测的有效性在很大程度上会受到损失函数的 影响, GIoU、CIoU、ICIoU 等损失函数仅考虑了预测 框和真实框的距离,未涉及到预测框和真实框不匹配的 方向,导致收敛速度较慢,效率较低。Gevorgyan 在 2022 年提出了 SIoU 损失函数, SIoU_Loss 考虑到期望 回归之间向量的夹角,重新定义了惩罚度量,提高了训 练速度和预测精度 [6],SIoU_Loss 的公式为 :
修改后的 YOLOv5s 模型的结构图如图 2 所示 :
3 实验结果与分析
3.1 数据集
数据集的质量对于深度学习的结果来说至关重要, 本文采用开源项目 Smart Construction 中的安全帽佩 戴检测数据集 SHWD,其中括 7581 个不同场景、天 气、光照条件、人数、拍摄距离的样本图像,其中有 9044 个人体安全头盔佩戴对象 ( 正面 ) 和 111514 个正 常头部对象 ( 未佩戴或负面 )。由于该数据是以 XML 文 档的形式存储的,因此,在使用之前,必须把该标注文 件转化成 YOLO 所要求的 TXT 格式。
3.2 实验设置
本文实验采用 Windows 11 专业版 64 位操作系统, Python3.8.8 开发语言,Pytorch1.12.1 深度学习框架, 所 用显卡为 NVIDIA GeForce RTX 3060 Ti,1TB SSD 硬盘, 64 GB 3200MHz 内存,CUDA 版本为 CUDA 11.6.
鉴于训练的模型既要保证模型的精度,也要保证 模型的大小和训练速度,本文选用 YOLOv5 模型和 YOLOv5s.pt 权重文件进行训练,epoch 设置为 150.Batch size 为 8. lr0 为 0.01. lrf 为 0.07. Mixup 为 0.1. 总共的训练时间大约为 5 个小时。
3.3 评价指标
本文实验结果采用类平均精度 AP(Average Precision)、 平均精度均值 MAP(Mean Average Precision) 和每秒传输 帧数,即每秒内可以处理图片的数量 FPS(Frame Per Second, FPS) 来对不同模型的性能进行评估。当 AP 的值越大时,说明该模型针对某一类数据的检测效果较 好, MAP 为所有类别 AP 值的均值。各评价指标计算 公式如下
:

其中,TP(True Positives) 为正样本且被识别为正 样本的数量,FP(False Positives) 为负样本被识别成正 样本的数量,FN(False Negative) 为正样本被是被成负 样本的数量。
3.4 消融实验
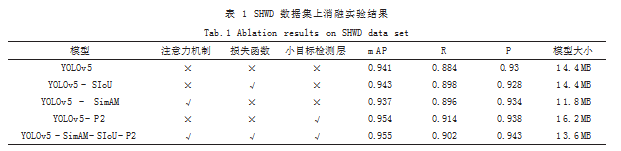
为了验证更改损失函数为 SIoU,增加小目标检测 层,以及增加注意力机制 SimAM 对于 SHWD 数据集 的提升效果,本文做了消融对比实验,实验结果下表 1 所示。
由表 1 可知,相对于其他的改进方法,添加小目 标检测层 (P2) 对于原 YOLOv5s 模型的改进较为明显, 平均精确度 (mAP) 提升了 1.3%,说明增加更小的检 测层能够更加清晰的分辨出较小的目标。将损失函数 更改为 SIoU,对于模型的提升较为一般,平均精确度 (mAP) 提升了 0.2%,召回率 R 提升了 1.4%。在增添 了 SimAM 注意力机制后,平均精确度 (mAP) 下降了 0.4%, 但模型大小从 14.4MB 降低至 11.8MB, 减少了 18.06%,减少了 GPU 的资源占用,减少了移动端硬件 部署的限制,更符合施工现场的实际要求。
同时增加三个模块后,平均精确度 (mAP) 和召回
率分别提升了 1.4% 和 1.8%,准确率提升了 1.3%,模 型大小降低至 13.6MB,减少了 5.6%,在提升精度的 同时,保持了 YOLOv5s 模型轻量化的优点。
3.5 对比实验
为了能够更清晰的体现改进后 YOLOv5s 模型的检 测效果,将其与原始的 YOLOv5s 模型的运行结果进行 比对,并展示对比结果如下表 2 所示。
由表 2 可知,改进的 YOLOv5s 模型的准确率比原 模型提高了 1.3%,召回率提高了 1.8%,平均精确度提 高了 1.4%,达到了提升模型检测精确度的目的。
3.6 结果分析
为了进一步验证改进后的 YOLOv5s 模型相比于原 有 YOLOv5s 模型在检测性能上有所提高,选取测试集 中不同场景的图片进行检测,并给出相应的检测结果, 如图 3 所示。(a) 为在复杂施工场景中的目标检测结果, 可以看出原 YOLOv5s 模型无法将处于复杂施工环境中 的 4 位佩戴安全帽的工人检出,而改进后的算法检测无 误 ;(b) 为被安全帽遮挡的目标检测结果,原 YOLOv5s 模型对被遮挡的施工作业人员产生漏检的情况,改进后 的算法检测效果较好 ;(c) 为复杂光线条件下的目标检 测结果,由于施工人员处于弱光施工场景,但被强光照 射,原 YOLOv5s 模型无法检测此类情况,改进后的算 法表现较好。综上所述,在复杂的施工作业环境中,改 进后的 YOLOv5s 模型对安全帽的检出效果更佳,达到 提升模型检测精度的目的。
4 结语
本文基于 YOLOv5s 模型进行了改进。首先,在原开发平台,采用 UDP 协议及多线程技术实现了测试软 件与下位机之间的双向通信,采用 FIFO 缓冲机制实现 了接收数据的正确解析,使用 FFT 处理、增益计算、 直流偏移计算及噪声计算,实现了对极板工作参数的准 确提取。测试表明,该测试软件通信稳定可靠,计算准 确,可应用于微电阻率成像测井仪极板的测试。
参考文献
[1] 黄建红,王波,衡勇,等.微电阻率扫描成像测井在涩北气田的 应用[J].成都理工大学学报(自然科学版),2015.42(4):444-450.
[2] 赵晓鸿,夏竹君,付琛,等.增强型微电阻率扫描成像测井仪及 其应用[J].石油管材与仪器,2019.5(1):67-70.
[3] 孙阳春.油基泥浆微电阻扫描测井仪极板测试装置设计[D]. 成都:电子科技大学,2016.
[4] 中国石油集团测井有限公司.MCI6570微电阻率成像测井 仪使用维修手册[Z].
[5] 金旭球,金斌英.基于UDP协议的嵌入式系统之间通信的实 现[J].台州学院学报,2008(3):24-27.
[6] 霍亚飞,程梁.Qt 5编程入门[M].北京航空航天大学出版 社,2015.
[7] 杨绪峰,乔斌,凌震莹,等.基于GSL科学计算库的主动定向浮 标信号处理算法实现[J].舰船电子工程,2016.36(7):44-46+164. [8] Gough,Brian.GNU Scientific Library Reference Manual - Third Edition[M].Network Theory Ltd, 2009.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/57964.html