SCI论文(www.lunwensci.com):
小编特地整理了 蚂蚁金服人工智能部研究员ICML贡献论文系列 第四篇论文,以下只是改论文摘录出来的部分英文内容和翻译内容,具体论文英文版全文,请在本页面底部自行下载学习研究。
SBEED: Convergent Reinforcement Learning with Nonlinear Function Approximation
SBEED:非线性函数逼近的收敛强化学习
Bo Dai, Albert Shaw, Lihong Li, Lin Xiao, Niao He, Zhen Liu, Jianshu Chen, Le Song
戴波,肖,李力宏,林晓,尼奥赫,甄刘,陈建树,勒松
Georgia Insititute of Technology
格鲁吉亚技术研究所
Google Inc., Microsoft Research, Redmond
谷歌公司,微软研究公司,雷德蒙德
University of Illinois at Urbana Champaign, Tencent AI Lab, Bellevue
伊利诺伊大学香槟分校,腾讯人工智能实验室,贝尔维尤
June 7, 2018
Abstract
When function approximation is used, solving the Bellman optimality equation with stability guarantees has remained a major open problem in reinforcement learning for decades. The fundamental difficulty is that the Bellman operator may become an expansion in general, resulting in oscillating and even divergent behavior of popular algorithms like Q-learning. In this paper, we revisit the Bellman equation,and reformulate it into a novel primal-dual optimization problem using Nesterov’s smoothing technique and the Legendre-Fenchel transformation. We then develop a new algorithm, called Smoothed Bellman Error Embedding, to solve this optimization problem where any differentiable function class may be used. We provide what we believe to be the first convergence guarantee for general nonlinear function approximation, and analyze the algorithm’s sample complexity. Empirically, our algorithm compares favorably to state-of-the-art baselines in several benchmark control problems.
中文翻译:
摘要:
当采用函数逼近时,求解具有稳定性保证的Bellman最优方程一直是强化学习中的一个重要问题。基本艰难 Ty是Bellman算子在一般情况下的扩展,导致Q-学习等流行算法的振荡甚至发散行为。在本文中,我们重新讨论了Bellman方程。 利用Nesterov的平滑技术和Legendre-fen-el变换,将其重新表述为一个新的原对偶优化问题.然后,我们开发了一种新的算法,称为平滑B。 Ellman错误嵌入,解决了这个优化问题,可以使用任何可微函数类。我们给出了一般非线性f的第一个收敛性保证。 函数逼近,并分析了算法的样本复杂度。在经验上,我们的算法在几个基准控制问题上比最先进的基线要好得多.
1 Introduction
In reinforcement learning (RL), the goal of an agent is to learn a policy that maximizes long-term returns by sequentially interacting with an unknown environment (Sutton & Barto, 1998). The dominating framework to model such an interaction is the Markov decision process, or MDP, in which the optimal value function are characterized as a fixed point of the Bellman operator. A fundamental result for MDP is that the Bellman operator is a contraction in the value-function space, so the optimal value function is the unique fixed point.
Furthermore, starting from any initial value function, iterative applications of the Bellman operator ensure convergence to the fixed point. Interested readers are referred to the textbook of Puterman (2014) for details.
Many of the most effective RL algorithms have their root in such a fixed-point view. The most prominent family of algorithms is perhaps the temporal-difference algorithms, including TD(λ) (Sutton, 1988), Q?learning (Watkins, 1989), SARSA (Rummery & Niranjan, 1994; Sutton, 1996), and numerous variants such as the empirically very successful DQN (Mnih et al., 2015) and A3C (Mnih et al., 2016) implementations.
Compared to direct policy search/gradient algorithms like REINFORCE (Williams, 1992), these fixed-point methods make learning more efficient by bootstrapping (a sample-based version of Bellman operator).
When the Bellman operator can be computed exactly (even on average), such as when the MDP has finite state/actions, convergence is guaranteed thanks to the contraction property (Bertsekas & Tsitsiklis, 1996).
Unfortunately, when function approximatiors are used, such fixed-point methods easily become unstable or even divergent (Boyan & Moore, 1995; Baird, 1995; Tsitsiklis & Van Roy, 1997), except in a few special cases.
For example,
• for some rather restrictive function classes, such as those with a non-expansion property, some of the finite-state MDP theory continues to apply with modifications (Gordon, 1995; Ormoneit & Sen, 2002;Antos et al., 2008);
• when linear value function approximation in certain cases, convergence is guaranteed: for evaluating a fixed policy from on-policy samples (Tsitsiklis & Van Roy, 1997), for evaluating the policy using a closed-form solution from off-policy samples (Boyan, 2002; Lagoudakis & Parr, 2003), or for optimizing a policy using samples collected by a stationary policy (Maei et al., 2010).
In recent years, a few authors have made important progress toward finding scalable, convergent TD algorithms,by designing proper objective functions and using stochastic gradient descent (SGD) to optimize them (Suttonet al., 2009; Maei, 2011). Later on, it was realized that several of these gradient-based algorithms can be interpreted as solving a primal-dual problem (Mahadevan et al., 2014; Liu et al., 2015; Macua et al., 2015;
Dai et al., 2016). This insight has led to novel, faster, and more robust algorithms by adopting sophisticated optimization techniques (Du et al., 2017). Unfortunately, to the best of our knowledge, all existing works either assume linear function approximation or are designed for policy evaluation. It remains a major open problem how to find the optimal policy reliably with general nonlinear function approximators such as neural networks, especially in the presence of off-policy data.
Contributions In this work, we take a substantial step towards solving this decades-long open problem,leveraging a powerful saddle-point optimization perspective, to derive a new algorithm called Smoothed Bellman Error Embedding (SBEED) algorithm. Our development hinges upon a novel view of a smoothed Bellman optimality equation, which is then transformed to the final primal-dual optimization problem.
SBEED learns the optimal value function and a stochstic policy in the primal, and the Bellman error (also known as Bellman residual) in the dual. By doing so, it avoids the non-smooth max-operator in the Bellman operator, as well as the double-sample challenge that has plagued RL algorithm designs (Baird, 1995). More specifically,
• SBEED is stable for a broad class of nonlinear function approximators including neural networks, and provably converges to a solution with vanishing gradient. This holds even in the more challenging off-policy case;
• it uses bootstrapping to yield high sample efficiency, as in TD-style methods, and is also generalized to cases of multi-step bootstrapping and eligibility traces;
• it avoids the double-sample issue and directly optimizes the squared Bellman error based on sample trajectories;
• it uses stochastic gradient descent to optimize the objective, thus very efficient and scalable.
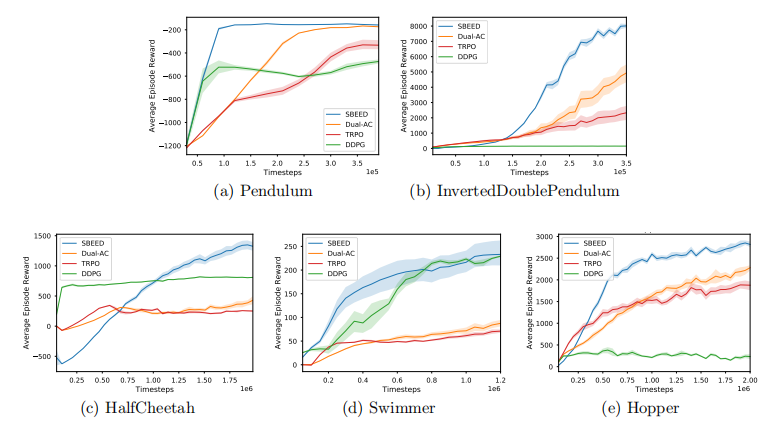
Furthermore, the algorithm handles both the optimal value function estimation and policy optimization in a unified way, and readily applies to both continuous and discrete action spaces. We compare the algorithm with state-of-the-art baselines on several continuous control benchmarks, and obtain excellent results.
1 介绍
在强化学习(RL)中,Agent的目标是学习一种策略,通过与未知环境的顺序交互来最大化长期收益(Sutton&Barto,1998)。支配 这种交互作用的G框架是马尔可夫决策过程,其中最优值函数被刻画为Bellman算子的一个不动点。基本结果 R MDP表示Bellman算子是值函数空间中的一个收缩,因此最优值函数是唯一的不动点。
此外,从任意初值函数出发,Bellman算子的迭代应用保证了收敛到不动点。有兴趣的读者可参阅普特曼的教科书。 (2014年)详情。
许多最有效的RL算法的根都在这样一个固定的视图中。最著名的算法系列可能是时差算法,包括td(λ)(Sutton,198)。 8),Q?Learning(Watkins,1989年),SARSA(Rummery&Niranjan,1994年;Sutton,1996年),以及许多变体,如经验性非常成功的DQN(Mnih等人,2015年)和A3C(Mnih等人,2016年)。 citations引用( citation的名词复数 )
与直接策略搜索/梯度算法相比(williams,1992),这些不动点方法通过引导(一种基于样本的Bellman operato版本)来提高学习效率。 英语字母表的第18个字母).
当Bellman算子可以精确地计算(甚至平均)时,例如当mdp有限的状态/动作时,由于收缩性质(Bertsekas&Tsitsiclis),收敛性得到保证(Bertsekas&Tsitsiclis) , 1996).
不幸的是,当使用函数逼近器时,这种不动点方法很容易变得不稳定甚至发散(Boyan&Moore,1995;Baird,1995;Tsitsiclis&Van Roy,1997),少数方法除外。 特殊情况。
例如
·对于一些限制性较强的函数类,例如那些具有非展开性质的类,一些有限状态mdp理论在修改后继续适用(Gordon,1995;or货币化和Sen,20岁)。 02;Antos等人,2008年);
·当线性值函数在某些情况下近似时,保证收敛性:用于从政策样本中评估固定策略(Tsitsiclis&Van Roy,1997),用于评估策略使用情况。 Ng是来自非政策样本的封闭形式解决方案(Boyan,2002年;Lagoudakis&Parr,2003年),或用于使用平稳策略收集的样本优化策略(MAEI等人,2010年)。
近年来,一些作者通过设计合适的目标函数和使用随机梯度下降(Sgd)来选择,在寻找可扩展的收敛td算法方面取得了重要进展。 模仿他们(Suttonet al.,2009年;MAEI,2011年)。后来,人们认识到这些基于梯度的算法中有几个可以解释为解决了一个原始对偶问题(mahadevan等人,2014;Liu)。 等人,2015年;Macua等人,2015年;
戴等人,2016年)。通过采用复杂的优化技术,这种洞察力带来了新的、更快、更健壮的算法(Du等人,2017年)。不幸的是,据我们所知, 现有的工作要么是线性函数近似,要么是为政策评估而设计的。如何可靠地寻找具有一般非线性功能的最优策略仍然是一个重要的开放问题。 逼近器,如神经网络,尤其是在存在非策略数据的情况下。
在这项工作中,我们为解决这个长达数十年的开放问题迈出了实质性的一步,利用一个强大的鞍点优化视角,导出了一种名为smoo的新算法。 AndBellman误差嵌入(SBEED)算法。我们的发展依赖于光滑Bellman最优性方程的一个新观点,然后将其转化为最终的原始对偶优化问题。 alem[地名] [荷兰] 阿勒姆
SBEDE在原始学习中学习最优值函数和随机策略,并在对偶中学习Belman误差(也称为Belman残差)。通过这样做,避免了非光滑最大算子 BELMAN算子,以及双样本挑战,已经困扰了RL算法设计(贝尔德,1995)。更具体地说,
·SBEED对于包括神经网络在内的一类广义非线性函数逼近器是稳定的,并可证明收敛到具有消失梯度的解。即使是在更具挑战性的情况下也是如此。 非政策性案件;
·采用自举产生高样本效率的方法,如TD型方法,并将其推广到多步自举和资格跟踪的情况;
·避免了双样本问题,直接优化了基于样本轨迹的平方Bellman误差;
·它使用随机梯度下降来优化目标,因此具有很高的效率和可扩展性。
此外,该算法以统一的方式处理最优值函数估计和策略优化,并且容易应用于连续和离散的动作空间。我们比较了 e算法在几个连续的控制基准上具有最新的基线,并获得极好的结果。
以上只摘录了论文一小部分,具体论文全文请点击下方下载,用于研究和学习。
蚂蚁金服人工智能部研究员ICML贡献论文系列 第四篇论文
《
SBEED: Convergent Reinforcement Learning with Nonlinear Function Approximation》
PDF版下载链接:
http://www.lunwensci.com/uploadfile/2018/0716/20180716113645935.pdf
关注SCI论文创作发表,寻求SCI论文修改润色、
SCI论文发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/161.html