SCI论文(www.lunwensci.com):
摘 要:计算机围棋软件一直是人机对抗的研究热点,自从 2016 年谷歌旗下研发的阿尔法围棋软件击败围棋世界冠军, 阿尔法围棋软件背后采用的深度学习技术使得人工智能技术的潜力和价值被世人得以重新认识。本文通过介绍基于 Keras 深度 学习软件如何快速搭建一个围棋机器人,使其经过卷积神经网络的训练后带到一定的围棋水平,探讨了卷积神经网络的一些实 践过程。
关键词:深度学习;卷积神经网络;Keras;激活函数;损失函数
Research on Computer Go Robot Based on Deep Learning
PENG Zhijun
(Guangdong Vocational College of Post and Telecom, Guangzhou Guangdong 510630)
【Abstract】: Computer Go software has always been a research hotspot in human-computer confrontation. Since 2016, the Alpha Go software developed by Google defeated the world champion of Go. The deep learning technology behind the Alpha Go software has made the potential and value of artificial intelligence technology renewed by the world know. This article introduces how to quickly build a Go robot based on the Keras deep learning software, which will be trained by the convolutional neural network to bring it to a certain level of Go, and discuss some practical processes of the convolutional neural network.
【Key words】: deep learning;convolutional neural network;Keras;activation function;loss function
0 引言
在谷歌旗下 DeepMind 公司的阿尔法围棋(Alpha- Go)软件与围棋世界冠军、韩国围棋九段李世石对局之 前,围棋曾被认为是棋类游戏中人机对抗的最后一道堡 垒。2016 年 3 月 ,AlphaGo 以 4:1 的 比 分 战 胜 李 世 石 九段, 在全世界引起巨大的震动。本文主要介绍使用深度 学习技术框架开发围棋定式机器人的基本流程。主要结构 如:首先介绍神经网络和深度学习的基本概念,然后介绍 围棋机器人开发的主要流程和步骤。并重点介绍深度学 习算法在围棋程序的常见应用,最后做出总结与评价。
1 研究概述
游戏是一直以来都是人工智能一个重要的试验场。 最新最前沿的技术都首先在游戏中应用和验证,这些新 技术被证明其有效性后推广到人类的生产活动中。基于深度学习技术和蒙特卡洛树搜索的 Alpha Go 使用机器 学习来大大增强了传统的经典 AI 算法,特别是使用了 深度学习技术,使围棋 AI 能快速学习并超越人类上千 年的经验积累。本文介绍基于开源深度学习框架 Keras 来实现围棋定式解答机器人,从而向大家介绍深度学习 在实践中模型的建立、参数调校的一些方法和实践。
2 神经网络
人类大脑的工作机制是科学家研究人工智能最主要的 研究对象。20 世纪 50 年代,罗森布拉特首先提出了基于 MCP 神经元模型的感知器学习规则概念。根据这个感知规则, 罗森布拉特提出了算法, 它能自动学习最优权重系 数,乘以输入特征,得到神经元是否触发的结果 [1]。
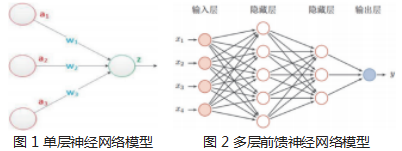
2.1 单层神经网络
基于人工神经元算法,科学家设计出了单层神经网络(图 1 所示)。以用来分类的自适应神经元算法 (Adaline)为例,采用一种称为梯度下降算法来学习模 型的权重系数。采用以下公式的更新规则在训练集的每 次迭代中更新其权重向量 w:
w:=w+∆w, 其中∆w=-η∆J(w)
该公式的含义是计算基于整个训练集的梯度,并通 过相反方向的梯度来更新梯度的权重。此外将优化定义 为误差平方和的目标函数 J(w) 从而找到该模型的最优权重系数,并且要把梯度值乘以学习率 η,用来平衡学 习速度与全局最小成本函数过度产生的风险。
2.2 多层前馈神经网络
单层神经网络简单高效,但是对于多层网络无法有 效处理。将多个单神经元连接到多层前馈神经网络,这 个网络被称为多层神经网络。多层前馈神经网络模型如 图 2 所示。
图 2 表示的是一个包含 3 层的普通前馈神经网络。 另外我们应用一个激活函数 sigmoid 函数 y=σ(z)来 获得输出神经元 y。应用 σ 的结果可以调整 y 的激活 程度。给定权重矩阵 W 和偏差项 b, 应用仿射线性变 换 z=Wx+b 可以构成神经网络的一层 , 通常称之为稠密 层。稠密层和激活函数构成了前馈神经网络。它的定义 公式如下 , 分为两步:
(1)从输入向量 x 开始,计算 z
1=w
1x+b
1 ;(2) 根 据中间结果 z ,计算最后输出结果。y=w
12z
1+b
2, 上标表 示向量的层。
2.3 损失函数及其优化
上节定义了前馈神经网络, 接下来要定义一个标准去 评估预测结果与实际结果的接近度。由此引入损失函数, 又称为目标函数。均方误差(Mean Square Error,MSE) 是一个使用较为广泛的损失函数,它使用真实值与样本 距离的平方表示测试预测值与实际值的接近程度。MSE函数定义公式如下:
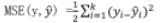
常见的优化算法为随机梯度下降(Stochastic Gradient Descent,SGD)算法。同时遗传算法、粒子群优化算法 等也可以应用,但应用不如梯度下降算法广泛。
2.4 超参数
超参数表示用户可自主选择,并会影响系统性能的一些配置选项设置。超参数包含几类:(1)层级的数量; (2) 量级(动量、学习率);(3) 正则化(Dropout、一 级正则化、二级正则化) ;(4)激活函数;(5)权重初 始化策略;(6) 损失函数;(7) 训练轮数的设置;(8) 向量化方案。
3 卷积神经网络
卷积神经网络是一种前馈神经网络,它的人工神经 元可以响应一部分覆盖范围内的周围单元,特别适合图像处理场景。卷积神经网络提供了一种端到端的学习模 型,模型中的参数可以通过传统的梯度下降方法进行训 练,经过训练的卷积神经网络能够学习到图像中的特 征,并且完成对图像特征的提取和分类 [2]。卷积神经网 络对于有规范的数据结构的数据处理比较擅长,而计算 机围棋棋局使用一种称为 SGF 格式的规范数据集。这 使得使用神经网络训练围棋机器人变得较为容易。
4 围棋数据编码
目前有很多较为成熟的开源围棋对弈软件。我们只 需要解决如何处理数据输入到神经网络中。为了预测下 一步的落子,首先定义一个围棋棋局的编码器。如图 3 所示的简化 5×5 路的棋局为例。这里空位用 0 表示, 黑为 -1,白为 1, 经过编码器之后,转换成为如下的编 码格式。
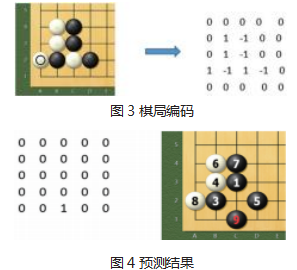
然后将以上编码后的棋局输入到神经网络中,将神 经网络的输出作为预测下一步的动作。如图 4 所示生成 的黑子下一步结果为 C1 点,为图 4 第 9 手。
5 使用 Keras 深度学习库训练模型
深度学习比较成熟的软件有 TensorFlow、Theano 等框架,而 Keras 则是建立在这些框架之上的工具。使 用 Keras 开发深度学习模型需要遵循如下 4 步 [3]。
(1)对数据进行预处理;(2)定义模型;(3)使用 优化器以及损失函数和其他评估指标编译模型;(4)训
练和评估模型。
在 keras 中可以定义顺序模型和非顺序模型两种数 据。本案例第一部分样本数据采用参考文献 2 的 dlgo 开源工具软件,该数据集采用蒙特卡洛树搜索算法生 成,对弈水平仅为业余水平。后续可以采用从开源的围 棋服务器上下载的职业九段(人类最高级别)棋手对弈 的棋局数据集 , 经过处理后得到更高质量的样本数据。
5.1 初步设立模型
代码清单如: 首先设置当前棋盘尺寸为 9 路棋盘。共有 81 个落子点。预测围棋的下一步动作,就是有 81 个分类,那么每个落子点准确率率为 1.23%(1/81)。 希望通过深度学习模型能显著高于 1.23%。
# 部分代码,省略导入数据过程
board_size = 9 * 9
model = Sequential()
model.add(Dense(1000, activation=sigmoid, input_shape=(board_size,)))
model.add(Dense(500, activation=sigmoid))
model.add(Dense(board_size, activation= sigmoid))
model.summary()
model.compile(loss=mean_squared_error, optimizer=sgd, metrics=[accuracy])
model.fit(X_train, Y_train,
batch_size=64, epochs=15,
verbose=1, validation_data=(X_test, Y_test)) score=model.evaluate(X_test, Y_test, verbose=0)
以上代码段定义了一个简单的多层感知机,包含 了 3 个稠密层, 采用了 sigmoid 激活函数采用 MSE 为 损失函数,优化器采用随机梯度下降进行编译,采用了 15 个迭代周期的训练,最后的输出的预测精度大约为 2.6% 左右。为了提高预测精度,引入卷积神经网络以 及相应的参数调优方法,以下介绍相关方法。
5.2 使用卷积神经网络
采用 Keras 框架构建卷积神经网络, 使用一种叫做 Conv2D 的层,它可以对二维数据执行卷积操作。卷积 是一种适用于图像转换的方法。对于尺寸相同的两个矩 阵,首先相同位置的元素逐一相乘,然后将结果矩阵的 所有元素值相加得到一个值。过程如图 5 所示。
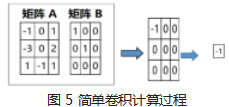
这个简单卷积实际用途不大, 在图像处理中, 经常要进行特征提取,提取过程也是两个矩阵计算的过程。 计算过程和结果如图 6 所示。
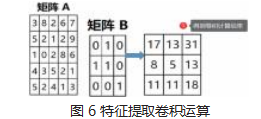
在 keras 中添加卷积层的语句为 model.add(Conv2D,filters=(3,3))。
5.3 卷积神经网络的优化
为了减少计算量,一般采用聚集技术。聚集的方式有 最大聚集、平均聚集等。在 keras 中添加最大聚集的语句 为 model.add(MaxPooling2D(pool_size=(2,2))。
在之前的模型中,激活函数主要采用的是 sigmoid 函数,为了适应围棋定式下一步的预测概率模型,改成 使用 softmax 激活函数。它的定义如下:
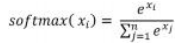
模型添加激活函数语句为 model.add(Dense(9*9 ,activation=’softmax’))。另外线性整流单元激活函数 (ReLU) , 根据相关研究表明这个函数的结果比其他激 活函数更好一些 [4]。
关于均方误差损失函数在此模型中经过分析并不 合适,改用分类交叉熵损失函数。它在随机梯度下降 中,当接近更高的预测值时,依然会有比较大的梯度, 而 MSE 的梯度更新会越来越小。分类交叉熵在这个场 景学习速度表现会优于 MSE。为了防止过拟合,一般 采用正则化技术。深度神经网络采用一种简单有效的技 术: 丢弃。在每一层网络中随机选择丢弃一定比例的 神经元可以有效的防止过拟合。在模型中添加语句为 model.add(Dropou(rate=0.5))。
经过以上的参数调整,模型构建后代码如下:
# 省略导入数据
model = Sequential()
model.add(Conv2D(48, kernel_size=(3,3), activation=relu,
padding=same, input_shape=input_shape))
model.add(Dropout(rate=0.5))
model.add(Conv2D(48, kernel_size=(3, 3),
activation=relu, padding=same))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(rate=0.5))
model.add(Flatten())
model.add(Dense(512, activation=relu))
model.add(Dropout(rate=0.5))
model.add(Dense(size * size, activation= softmax))
model.summary()
model.compile(loss=categorical_crossentropy,
optimizer=sgd, metrics=[accuracy])
model.fit(X_train, Y_train,
batch_size=64, epochs=100, verbose=1,
validation_data=(X_test, Y_test))
score = model.evaluate(X_test, Y_test, verbose=0)
模型经过测试,测试准确度为 8% 以上,本模型训 练迭代周期为 100 次。对比之前准确率提高了 300% 以 上。虽然相比 AlphaGo 高达 55.7% 的预测准确率相差 很远,但是本实验基于普通 pc 机,采用 intel i7 第 10 代 4 核 cpu 1.8GHz,内存 16g,100 次迭代。相比 AlphaGo单机版配置48个CPU和8个GPU, 能达到8%的准 确率表现也可以接受。
6 总结
使用深度学习中的卷积神经网络可以有效地提高训 练精确度,并且参考 AlphaGo 的神经网络层数设置,采 用 15 层 设 置, 卷 积 核 的 个 数 可 以 采 用 128, 192, 256,通过实验可以发现, 192 个卷积核可以达到网络 的训练效果较好率和网络调用速度较快兼顾的效果。 AlphaGo 是基于深度卷积神经网络的策略网络和价值 网络,减小了搜索空间,并且在训练过程中创新性地结 合了监督学习和强化学习,最后成功地整合蒙特卡罗树 搜索算法,达到了人类顶级棋手的水平。后续将在训练 模型中引入深度强化学习和价值网络评估,也将会有效 地提高预测准确度的方法。
参考文献
[1] [美]塞巴斯蒂安·拉施卡(Sebastian Raschka),瓦希德·米尔 贾利利,著.陈斌,译.Python机器学习(原书第2版)[M].北京:机 械工业出版社,2018.
[2] 李彦冬,郝宗波,雷航.卷积神经网络研究综述[J].计算机应用,2016,36(09):2508-2515+2565.
[3] [美]马克斯·帕佩拉,凯文·费格森,著.赵普明,译.深度学习与 围棋[M].北京:人民邮电出版社,2021.
[4] 曲之琳,胡晓飞.基于改进激活函数的卷积神经网络研究[J]. 计算机技术与发展,2017,27(12):77-80.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/34313.html







