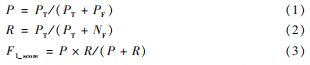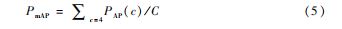SCI论文(www.lunwensci.com)
摘要:道路在长期使用情况下易产生路面损伤,进而降低交通效率,严重时甚至会危及人身和财产安全。为此设计了一种基于YOLO 目标检测算法的边缘到终端的道路损伤检测系统。系统包括路侧信息采集平台、边缘计算设备、云传输系统、客户使用终端。首先设计了一个轨道式巡检机器人作为持续的信息采集平台完成道路损坏检测任务;该机器人沿路侧轨道移动进行巡检,配备光学摄像头、Jetson NX、4G 无线路由器用于信息采集、边缘计算和通信;云服务器用于临时存储和传输机器人平台收集的信息;最终将信息发送给客户端,用于道路损坏检测的可视化显示;路面损伤检测算法基于YOLOv5 框架训练得到,在RDD2020 数据集 上对比了YOLOv5、YOLOv4 和YOLOv4-tiny 的效果,并基于NVIDIA Jetson NX 平台实现了模型部署和模型优化。实验结果表明, 该系统可以实现道路损伤检测的实时显示,具有一定的工程应用价值。
Design of Edge-to-client Real-time Road Damage
Detection System Based on YOLO Object Detection Algorithm
Li Mingjue,Zhang Gaoxing
( Kunming Shipborne Equipment Research &Test Center,Kunming 650051.China )
Abstract:Road are prone to damage under long-term use,which reduces traffic efficiency,and even endangers personal and property safety in serious cases.Therefore,an edge-to-client road damage detection system based on YOLO object detection algorithm is designed.The system includes roadside information collection platform,edge computing equipment,cloud transmission system,and client terminal.Firstly,a track- mounted inspection robot is designed as a continuous information collection platform to complete the road damage detection task.The robot moves along roadside tracks for inspection,and is equipped with optical cameras,Jetson NX,and 4G wireless routers for information collection, edge computing and communications.Cloud server is used to temporarily store and transmit the information collected by the robot platform.The information is finally sent to the client terminal for visual display of road damage detection.Road damage detection algorithm trained based on YOLOv5 framework.The effects of YOLOv5.YOLOv4.and YOLOv4-tiny on the RDD2020 data set are compared,and model deployment and model optimization are implemented based on the NVIDIA Jetson NX platform.Experimental results show that the system can realize real-time display of road damage detection and has certain engineering application value.
Key words:object detection;road damage detection;YOLO network;edge computing;robot
0 引言
很多因素(如雨水、道路老化)都会造成道路损 坏,例如道路裂缝和坑洼等,影响道路使用效率,甚至 人身和财产安全,此外,缺乏及时的维护也会导致道路 寿命的减少。因此,大范围的道路损坏的早期发现和处 理可以带来可观的社会和经济效益[1]。
传统的道路检测方法需要人工记录具体特征,例如损伤位置和损坏程度。这些方法依赖于检查人员的经验和知识,感知误差大,检测效率低,不适合大规模的道 路损坏检测。近年来,半自动检测技术成为主流,在一定程度上解决了交通拥堵问题。但存在后处理工作量大、 功能单一、依赖人工等问题[2]。因此,研究人员努力解决如何实现道路损坏自动检 测的问题,而图像处理方法由于其廉价和易用性而具有更广泛的应用。
利用图像处理方式实现道路损坏检测的方法可分为传统图像处理方法和基于机器学习的处理方法。对于传统方法,Oliveira 和Lobato Correia[3]提出了一种通过设置全局或局部阈值来查找裂缝的阈值算法。Nisanth Mathew 提出使用边缘检测器来检测道路裂缝的边缘,但 缺乏检测完整裂缝轮廓的能力[4]。机器学习为解决此类 问题提供了一条新途径,该方法已成功应用于交通领域,如交通标志分类任务。随着样本数据的扩大和计算性能的提高,机器学习的一个分支深度卷积神经网络( CNN) 已经证明它在大规模对象识别问题上的成功[5]。特别是,YOLO ( You Only Look Once ) 是一种实时深度CNN 方法,旨在从图像中检测对象[6-8] 。该方法鲁棒性强,兼顾准确性和实时性,广泛应用于交通领域,即可以快速完成车辆检测任务。此外,物体检测模型在移动终端上的应用也存在模型文件大、缺乏车载终端部署能力、帧率低等困难。例如,YOLOv4 作为一种先进的实 时目标检测模型,仍然有高达200 MB 的大小,难以部 署到移动端[9]。相应地,越来越多的轻量型网络和模 型压缩方法被提出,以实现在移动嵌入式系统上的 部署[10-14 ] 。
本文设计了一种道路损坏检测系统,该系统包括路 边巡检机器人(信息采集、边缘计算和远程通信平台)、 信息传输云服务器和客户端。首先,基于YOLOv5 s [ 15 ] 训 练道路损伤检测模型;然后,使用NVIDIA TensorRT 和DeepStream 工具包完成RDD 模型到NVIDIA Jetson NX 的边缘部署;最后,将边缘计算结果与云系统连接,构建 边缘到客户端终端的通信管道。实验结果表明,该系统可以实现道路损伤检测的实时显示。
1 道路损伤检测系统
1.1 任务描述和系统构成
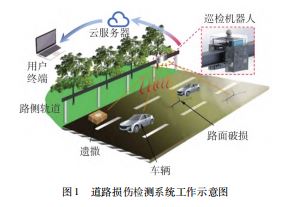
本文设计了一个安全、稳定、高效、持续的信息采集系统来完成道路损坏检测任务。如图1所示,基于轨 道的道路损坏检测系统,包括路边道路、道路巡检机器人、云服务器和客户端终端。该机器人可沿路边轨道移动进行巡检,配备光学摄像头、Jetson NX、4G 无线路由器用于信息采集、边缘计算和通信;云服务器用于临时存储和传输机器人平台收集的信息;最终将信息发送给客户端,用于道路损坏检测的可视化显示。
1.2 道路损坏检测系统工作流程
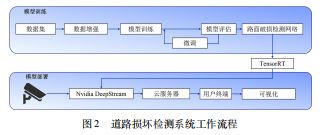
为了在移动端实现对道路损坏的快速准确检测,如 图2所示,本研究的工作流程可以分为模型训练和模型 部署两部分,分别在不同平台上完成。
模型训练:基于道路损坏数据集和目标检测网络,在通用计算机上通过迁移学习训练道路损伤检测网络。通过评估和微调的迭代,最终生成了一个效果更好的道 路损伤检测网络进行检测,同时保证网络体积小,易于部署。
模型部署:训练网络通过TensorRT 优化部署在边缘 设备(机器人平台上的Jetson NX) 上。结合车载摄像头 拍摄的视频,DeepStream 工具包可以整合检测结果和视 频,然后推送到云端服务器,最后在客户端显示检测结果。
2 研究方法
2.1 模型训练
2.1.1 数据集
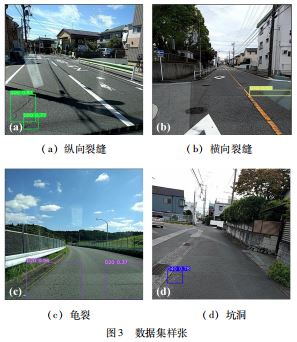
本文使用了一个专用于道路检测的开放数据集( RDD2020[ 10] )。基于日本东京大学的数据集,扩展添加 了来自印度和捷克共和国的数据,最终包含了26 620 张 图像。数据分为3 部分:Train、Test1 和Test2.原始数 据集共包含8 类数据。考虑到本研究的实际使用情况, 选取了4种常见的道路损坏类型:纵向裂缝(D00 )、横 向裂缝(D10)、龟裂(D20) 和坑洞(D40 ),具体如图3 所示。
2.1.2 数据增强方法
为了提高模型的泛化能力,防止网络在训练过程中 的欠拟合,通常需要补充数据量。本研究采用马赛克数据增强方法解决多尺度目标识别和不同场景的适应性问题[7]。通过水平翻转和随机缩放(在小范围内)等操作,将4张原始图像组合为一张图像作为训练数据,丰富了图像的背景,并引入了不同尺度的对象,以实现模型识别小于正常尺寸的物体。另一方面,由于网络的批量归一化(BN) 是从4张图片中计算出来的,这种方法可以减少对mini -batch 的依赖。此外,它打乱了检测对象在图像中的分布,进一步提高了模型的适应性。
2.1.3 基于YOLO 的道路损伤检测网络
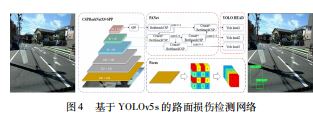
YOLOv5 网络是YOLO 系列的新架构,检测精度高, 推理速度快[15] 。YOLOv5 的权重文件较小,比YOLOv4 小近90%,说明YOLOv5 适合部署在嵌入式设备上实现实时检测。考虑到本研究检测模型对实时性和轻量级敏感,采用YOLOv5s 架构作为道路损伤检测网络框架。YOLOv5 s 网络由骨干网络、颈部网络和检测头网络组成。输入图像尺寸为640 pixel × 640 pixel,主干网络使用CSPDarkNet53 进行特征提取;然后颈部分选择主干网络的最后三级特征,并使用FPN + PAN 结构进 行特征融合,以增强网络的学习能力;3 个头部检测网络分别用于实现对大中小尺寸物体的物体检测。如图4 所示。
2.1.4 评估指标和模型参数
为了评估模型检测性能的准确性,本研究使用了4个指标,即准确度、召回率、mAP (平均精度)和F1-score。模型的性能与这4 个参数正相关,即4个参数越大,性能越好。参数可以表示如下:
式中:PT 为正类并被判定成正类;PF 为假类但判定为正类;NF 为正类但判定为假类;P 为准确度;R 为召回率。
AP 以及mAP 融合了精确度与召回率两个评价指标, 可以较为综合的对模型的性能进行评价,具体计算可以 表示如下:
式中:P (k ) 为阈值k处的准确度;r ( k ) 为k处召回率的变化量;C 为检测类别的个数。
在本研究中,IOU 阈值为0.5.相应地,mAP 记为 mAP@ 0.5.此外,为了评估模型的实时性能,本研究使用了体积、模型参数量、推理时间、GFLOPs、FPS 等指标,分别代表了模型的大小、模型参数的数量、模型 推理时间、模型所需的每秒千兆浮点运算,以及每秒的帧数。
2.2 模型优化和模型部署
2.2.1 基于TensorRT 的网络优化考虑到边缘计算设备通常存在计算能力的局限,本文使用NVIDIA 推出的高性能深度学习推理工具TensorRT,帮助优化模型结构,为深度学习应用提供低延迟、高吞吐量的服务。
2.2.2 使用DeepStream 完成模型部署
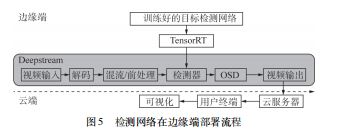
DeepStream 是一个流式分析工具包,用于构建人工智能驱动的应用程序。图5展示了道路损伤检测网络在 计算边缘的部署方法和基于DeepStream 工具包的边缘到 客户端终端的工作流程。
在边缘端,工作流的输入来源可以是来自摄像机的视频、文件或RTSP 流;然后在解码模块中对输入视频( H.264 或H.265 ) 进行解码;可以在混流/前处理模块 中合并来自不同来源的视频;之后,推理模块将对 TensorRT 生成的引擎文件进行链接,实现检测网络与视频流的融合;最终检测结果将显示在屏幕显示模块( OSD) 中;最后,可以在视频输出模块中设置视频的不同输出模式,如mp4 或RTSP 流。
对于云端和客户端,可以通过云服务器接收边缘输 出的检测结果,并将检测结果放到客户端进行可视化,从而完成边缘到客户端模型的部署。
3 实验和结果分析
3.1 使用YOLOv5s 训练基础模型
3.1.1 数据准备
该数据集共包含21 041 张带标签的图像。考虑到数据集中背景图片过多,删除了多余的背景图片(只保留了大 约1% 的背景图片),采用了12 195 张图片。这些图像按照 9∶ 0.5∶ 0.5 的比例随机分为训练集、验证集和测试集。
3.1.2 训练参数
使用上一步划分的训练集进行基于YOLOv5 s 的模型 训练。输入批量大小设置为8;训练轮次为300;输入图 像尺寸为640 pixel × 640 pixel;使用SGD +动量方式优化器;使用多尺度训练;使用马赛克数据增强。
3.1.3 训练结果
YOLOv5 s 模型的损失可以分为3部分:box -loss、cls -loss 和obj -loss。这三种类型的损失具有相似的下降曲线。在网络训练的前50 个轮次中,损失迅速下降,经过250 个轮次,损失值基本稳定。因此,确定300 个轮次训练后的模型作为道路损伤检测模型输出。
3.1.4 训练后模型评估
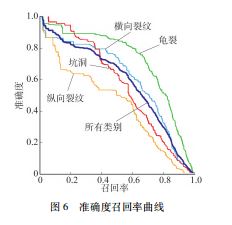
使用之前划分的测试集来验证训练好的道路损伤检测网络的准确性。如图6所示,所有类别的mAP@ 0.5为0.584.横向裂缝的mAP@ 0.5 最低,为0.440.龟裂的mAP@ 0.5 最高,为0.722.
3.1.5 性能及效率对比
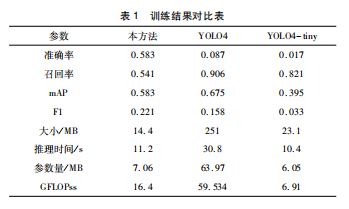
指标主要分为两个主要级别:性能( 准确率、召回率、mAP、F1 -score ) 和效率( 文件大小、推理时间、参数量、GFLOPS) 。如表1所示,从本研究提出的方法可以看出,该方法具有良好的准确性,并且可以保证实时性,而后者对于模型部署可能更为重要。
3.2 基于Jetson NX 的模型推理
NVIDIA Jetson NX 是一款带有GPU 的高性能边缘计算设备,包含用于加速计算和人工智能应用程序开发的工具和库,使其能够处理复杂的数据设备并实现快速准确的推理。
3.2.1 多种模型间的实时性参数比较
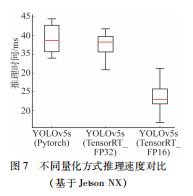
图7所示为不同精度模型推理所需推理时间对比。在推理阶段,TensorRT 支持float16( FP16 ) 甚至INT8 的计算。训练深度学习网络时,通常使用32 位或16位数据。TensorRT 在网络推理中选择不那么高精度图7 不同量化方式推理速度对比来达到加速推理的目的。 ( 基于Jetson NX)基于YOLOv5 s 模型网络的实时对比实验在Jetson NX 平台上进行。没有TensorRT 加速的Pytorch 版本道路损伤检测网络的推理时间约为35 ~ 45 ms;使用FP32进行模型优化后,推理时间约为32 ~ 42 ms,具有一定的优化效果;进一步,使用FP16 进行模型优化,推理时间约为16 ~ 30 ms,相比不使用TensorRT 工具包有很大的提升效果。
3.2.2 实验结论
为了验证边缘到终端的道路损伤检测系统的功能,使用未经训练的视频作为相机源来模拟真实场景。推理模型为基于YOLOv5 s TensorRT-FP16 的道路损伤检测模型,视频为1080p 和H.264 编码。
在NVIDIA Jetson NX 端执行在线道路损坏检测实验,将检测结果通过RTMP 流推送到云端服务器,最后在客户端显示检测结果,如图8所示,两个视频中的检测帧:
分别检测到纵向裂纹和龟裂,FPS 约为50.满足边缘到终端的道路损伤检测系统在线检测的需要。
4 结束语
在这项研究中,提出了一种边缘到客户端的自动化道路损坏检测方法,并通过实验进行了验证。基于RDD2020 数据集,在NVIDIA Jetson NX 移动平台上进行了YOLOv5 s、YOLOv4 和YOLOv4 -tiny 目标检测模型的精度和实时性能对比实验。结果表明,基于YOLOv5 s 的道路损伤检测网络性能优于其他两种,可用于模型部署。
此外还探讨了TensorRT 优化和训练后量化对模型推理速度的影响。FP16 量化比FP32 有更大的提升。最后结合NVIDIA DeepStream 工具包和云服务器,进行边缘到客户端的视频流传输,客户端显示的视频表明道路损坏检测系统具备实时路损检测能力。
参考文献:
[1]交通运输部.2022 年交通运输行业发展统计公报[N]. 中国交通报,2023-06-16( 002).
[ 2 ] 王志锦.机器人技术在高速公路运营中的应用[J ].2020( 19 ):98 -100.
[ 3 ] OLIVEIRA H,CORREIA P L. Automatic road cracksegmentation using entropy and image dynamic thresholding[ C ]//17 th European Signal Processing C onference,2009:622 -626.
[ 4 ] NISANTH A,MATHEW A. Automated visual inspection onpavement crack detection and characterization [ J ].InternationalJournal of Technology and Engineering System ( IJTES ),2014.6( 1 ):14-20.
[ 5 ] LECUN Y,BENGIO Y,HINTON G.Deep learning [ J ].Nature,2015.521 ( 7553 ):436-444.
[ 6 ] REDMON J,DIVVALA S,GIRSHICK R,et al. You only lookonce:unified,real -time object detection [ C ]// Proceedings ofthe IEEE Conference on Computer Vision and Pattern Recognition,2016:779-788.
[ 7 ] REDMON J,FARHADI A. YOLO9000:better,faster,stronger[ J ]. Proceedings of the IEEE C onference on C omputer Visionand Pattern Recognition,2017:7263-7271.
[ 8 ] REDMON J,FARHADI A.Yolov3:an incremental improvement[ EB/OL ].arXiv Preprint.arXiv1804.02767.2018 . [9 ] BOCHKOVSKIY A,WANG C Y,LIAO H Y M.Yolov4:optimalspeed and accuracy of object detection [ EB/OL ]. arXivPreprint.arXiv2004.10934.2020.
[ 10 ] ARYA D,MAEDA H,GHOSH S. K,et al. RDD2020:Anannotated image dataset for automatic road damage detectionusing deep learning [ J ]..Data in Brief,2021.36 ( 1 ):107133.
[ 11 ] DU Y,PAN N,XU Z,et al. Pavement distress detection andclassification based on YOLO network [ J ].. InternationalJournal of Pavement Engineering,2020 ( 1 ):1 -14.
[ 12 ] MEHTA R,OZTURK C. Object detection at 200 frames persecond [ C ]// Proceedings of the European C onference onC omputer Vision ( ECCV ) Workshops,2018.
[ 13 ] TAN M,PANG R,LE Q V.Efficient DET:Scalable and efficientobject detection [ C ]// Proceedings of the IEEE/CVFC onference on C omputer Vision and Pattern Recognition,2020:10781 -10790.
[ 14 ] MOLCHANOV P,TYREE S,KARRAS T,et al. Pruningconvolutional neural networks for resource efficient inference[ EB/OL ].https://arxiv.org/abs/1611.06440v1.
[ 15 ] Glenn-jocher.ultralytics/yolov5:v5. 0 -YOLOv5 -P6 1280 models,AWS,Supervise.ly and YouTube integrations [ EB/OL ]. https://github.com/ultralytics/yolov5/releases/tag/v5.0.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/ligonglunwen/65180.html