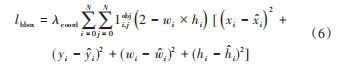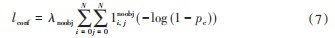SCI论文(www.lunwensci.com):
摘要:烟火图像检测在火灾防控中具有重要的意义,但由于烟雾和火焰成像具有多变性和无规则性,大多数烟雾检测算法在现实场景下往往表现欠佳,漏检情况相对严重。针对于此,通过结合基于深度学习的一阶段回归目标检测模型(YOLOv3)与自注意力机制,提出了一种基于YOLOv3自注意力烟雾和火焰图像检测算法,在优化原有YOLOv3网络模型的基础上,通过结合多尺度的自注意力网络,融合模型上下文信息,引导模型自适应学习提取关键的特征信息,增强了模型的特征表达,可有效提高烟雾和火焰检测的准确率。在测试集上结果表明,相比原有的基准检测算法,该方法烟火检测算法的准确率为92.1%,提高了6.5%;通过主干网络替换对比实验进一步验证了该结构设计的有效性,该算法具备较好的实用性。
关键词:烟火检测;深度学习;自注意力;自适应学习;上下文信息
Self-attention Smoke and Fire Detection Based on YOLOv3
Feng Tingyou1,Cai Chengwei1,Tian Ji1,Jiang Zhihong1,Zhou Junhuang2※,Chen Le2
(1.Huaneng Dongguan Gas Turbine Thermal Power Co.,Ltd.,Dongguan,Guangdong 523000,China;2.Guangzhou Power Electrical Technology Co.,Ltd.,Guangzhou 510700,China)
Abstract:Pyrotechnic image detection has great significance in fire prevention and control.As the variability and irregularity of smoke and fire imaging,most of the detection algorithms perform poorly in real scenes.By combining the one-stage regression object detection based on deep learning(YOLOv3)and the self-attention mechanism,a self-attention smoke and fire detection was proposed based on YOLOv3.With the multi-scale self-attention network,which fusing context guides adaptive learning of the modeland extracts key information from features,model can effectively enhance the feature expressionand improve the accuracy of smoke and flame detection.Results show the accuracy of smoke and fire detection has significantly improved.The accuracy of the fireworks detection method in this paper is 92.1%,which is an increase of 6.5%. The comparison experiment of backbone network replacement further verifies the effectiveness of the structure design,and the algorithm has good practicability.
Key words:smoke and fire detection;deep learning;self-attention;adaptive learning;context
0引言
火灾发生具有可预见性小、蔓延速度快、危害性大的特点,是危害生命安全和企业生产安全的重大事故的因素之一。如何快速并准确的检测识别是安全防控的重要方面。
早期的烟火防控主要依靠人工巡逻查看为主,发现则及时进行扑灭,该方法依赖于大量人工巡逻。随着厂房、器件和设备的增加,导致巡查难度不断增加,大大降低了巡检的效率。
随着传感器和数字化监管技术的发展,针对烟雾和火焰具有的高温特性,逐渐研发了基于红外方式的烟火检测装置[1]。此类装置根据物体随温度所散发的红外线多少来绘制热力图成像,从而达到检测的目的。然而,此类方法无法对高温类别进行甄别和判断,受检测区域
易受到高温设备的干扰和影响而导致误报,虚警率高。红外辐射与监控距离增加成反比,距离越远,成像越差。因此,此类装置覆盖传感监测范围有限,极易出现漏报。
随着计算机图像处理技术不断发展,基于图像处理和识别的方法在逐步发展,通过成像的先验特征,如颜色[2]、纹理[3-4]、梯度[5]等因素进行特征设计,结合霍夫变换、卡尔曼滤波、梯度计算等方式实现对目标区域的特征提取和判断,但受限于人工设计算子的感官偏向性,此类算法易受到外部环境的干扰,鲁棒性不强。近年来,随着计算机性能的不断提升,基于深度学习的图像算法通过自适应的特征信息抽取来实现对物体的识别与检测,具备较好的鲁棒性和广泛的应用性。
现有的深度学习目标图像检测算法主要是通过多层堆叠的卷积层用以实现对图像特征的抽取,本文使用YOLOv3[6](You Only Look Once version 3)检测烟火图像进行实验,由于烟火图像的多变性和无规则性,该算法存在漏检现象,检测效果稳定性不高。
针对此问题,本文提出一种基于自注意力特征的改进YOLOv3烟火检测算法,融合上下文信息的基础上引入自注意力机制,引导模型关注关键性特征,以增强目标检测的性能和稳定性。
1相关工作
1.1深度学习的发展
随着计算机的不断发展和应用,人工智能在无人驾驶、机器翻译、语音识别等领域都有着广泛的应用。与传统的机器学习算法相比,基于深度学习的人工智能算法有着更好的表现效果。2012年,Hinton团队在ILSVRC[7](ImageNet Large-Scale Visual Recognition Challenge)上采用神经网络并一举夺得冠军。2013年,Pierre Sermanet等人提出了OverFeat[8]算法,此算法兼顾了图像分类,检测,定位等多项任务。此后R-CNN[9]与YOLO[10]等系列算法提出,受到目标检测任务研究人员和众多工程应用人员的青睐。目标检测算法可分为基于区域候选的双阶段算法和基于目标回归的单阶段算法,区域候选算法具有精度高,检测速度慢的特点,而目标回归算法检测速度较快,但检测精度较低。2016年,SSD[11]算法在二者之间找了较好的平衡点,此后Mask-RCNN[12]和Retina-Net[13]等算法被相继提出。
1.2注意力机制的发展和应用
注意力机制一直都是计算机视觉中的一个研究热点,其想法来源于人的视觉行为特点,20世纪90年代,研究者们发现人类在图像观察中,并非关注图像的全部信息,而是重点关注感兴趣的区域进行特征提取和判断。
2014年,Mnih等[14]在循环神经网络中引入注意力机制实现图像分类。随后,D Bahdanau等[15]提出了将注意力机制引入自然语言机器翻译任务中用于实现翻译对齐。此后注意力机制在自然语言处理领域大放异彩,并不断进行改进。2017年,Google团队Vaswani等[16]提出了,一种纯注意力特征模块的用于自然语言处理,并刷新多项记录。随后ViT[17]等算法相继被提出,基于自注意力的神经网络算法在图像领域应用广泛。
注意力机制按照编码方式可分为两种:硬注意力机制和软注意力机制。硬注意力方式采用one-hot编码的方式进行设定,在每一组待判定的特征编码中采用概率最高的概率信息,有利于去除噪声。硬编码转换不可微,模型整体优化较难;软注意力方式采用加权的方式将数据映射为0-1之间的概率。此种方式有利于模型的优化,也可兼顾调节不同权重的信息预测[18-19]。
本文为了进一步提升烟火检测的精度,提出了一种基于YOLOv3的自注意力特征烟火检测算法。该自注意力特征模块,融合上下文信息,引导模型关注特征关键信息,提升检测精度。本文提出一种基于YOLOv3的多尺度的自注意力烟火检测算法,多尺度注意力特征检测较好地实现对场景下的烟火监控。
2实验
2.1数据集和预处理
本数据集基于现实场景应用的基础上,收集了4 800张内容包含有烟雾和火焰的数据图像。如图1所示,其中数据集的标注格式采用Pascal VOC[20]进行存储。随机选取4 500张图像作为训练集,剩余图像作为测试集进行模型测试。
图像预处理部分主要包含有数据增广策略,通过图像处理的方式增加图像数据的多样,此种策略有利于增强模型的鲁棒性。常见的增广手段包含有旋转、水平翻转、明暗变换、增加噪声等方式。本文采用旋转、水平翻转和对比度变换3种方式预处理图像,如图2所示。
2.2 YOLOv3算法
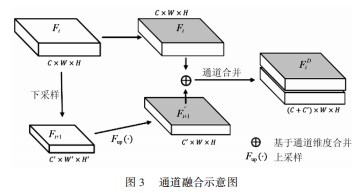
原有的YOLOv3算法是通过卷积神经网络实现端到端的目标回归预测任务。其网络结构见2.3.2节所述。YOLOv3目标检测模型包含3个部分:主干网络、融合层及预测层。YOLOv3算法采用darknet-53网络模型作为模型的主干网络提取原始图像的目标特征。通过通道合并的方式融合主干网络中多尺度特征的信息,将特征输入预测层进行目标边界、类别和置信度的预测。
通道合并的方式实现多尺度特征的上下文信息融合,但无法捕捉特征图内部信息的差异性,其具体操作如图3所示。图中Fi表示高分辨率特征,Fi+1表示低分辨率特征。Fi+1通过Fup(·)实现分辨率大小与Fi保持一致,采用维度叠加以实现特征信息实现融合。
其中Fup(·)表示特征尺寸对齐,其表达式如式(1)所示。尺寸对齐的方式一般包含有转置卷积、线性插值等方式,本文采用双线性插值的方式。Fup(·):FC'×W'×H'→FC'×W×H
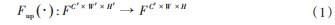
式中:F为特征,C',W',H'分别为特征原有的通道、宽度、高度维度,W、H为特征的对齐后的尺寸。
2.3基于YOLOv3自注意力烟火检测算法
2.3.1自注意力机制
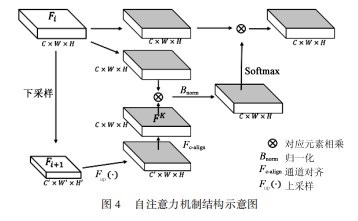
尽管YOLOv3算法利用基于通道合并的方式实现了多尺度信息的融合,但为了进一步排除非关键信息的干扰,引导网络聚焦于特征中的关键特征,本文引入注意力机制。其结构如图4所示。
在自注意力模块中,其输入为来自主干网络的特征图Fi和Fi+1,结构分别为C×W×H和C'×W'×H'。其中,C、C'为特征通道数,W、W'为特征图宽度,H、H'为特征图高度。一般来说,Fi大于Fi+1特征分辨率,在模型的最后一层中,Fi等于Fi+1特征分辨率,因此不需要Fi与Fi+1特征结构对操作。自注意力模块运算的流程如下所示。
(1)将输入特征Fi+1先后经过Fup(·),Fc-align的方式实现特征结构的对齐,其中Fc-align采用1×1的卷积实现特征通道对齐,得到结构为C×W×H特征图FK。
(2)输入特征Fi分别通过两次3×3的卷积转换为特征FV和FQ,特征的尺度大小保持不变。
(3)将步骤(1)中的FK特征与步骤(2)中的FQ逐元素相乘实现上下文信息的融合,经过Bnorm实现对W×H维度标准化得到特征FT,Bnorm降低特征方差防止特征权重两极化严重。其中Bnorm计算如式(2)所示:
式中:F为输入特征矩阵;d为标准化的维度,值为W×H。
(4)将步骤(3)中得到的特征FT在W×H的维度上进行softmax归一化,与步骤(2)得到的FV进行对应元素相乘得到注意力特征FA,完成自注意力模块的计算。
总体的自注意力模块的计算如式(3)所示:
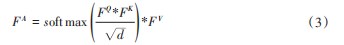
式中:*表式对应元素相乘。
2.3.2网络结构
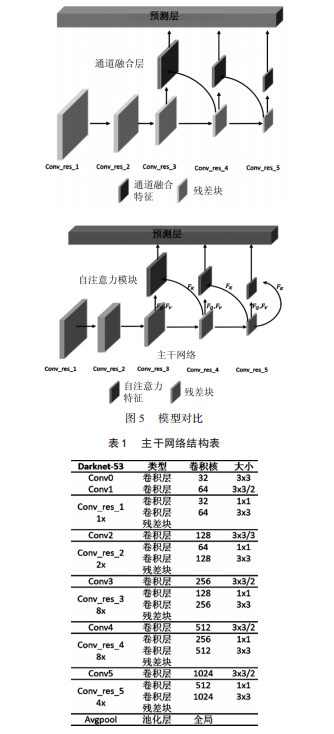
改进后模型仍然包含3个部分:主干网络,自注意力层及预测层,如5所示。主干网络总体结构借鉴了残差神经网络的“short-cut”的思路,有利于梯度在深层网络中的传递和模型的优化,在运算速度和表现精度上不逊色于Resnet101网络,后文也有对比,具备较好的实用性。其基本的结构如表1所示。
在主干网络中,Conv_res_3、Conv_res_4、Conv_res_5位置输出特征后嵌入自注意力模块。融合上下文信息,通过自注意力模块计算,输出特征图内信息的差异性,使网络优化倾向于目标关键特征的提取,提高模型的整体表现性能。
YOLOv3预测层在多尺度的注意力特征上进行预测,通过包含了类别预测,目标置信度预测和位置预测。其优化目标包含有3个方面,如式(4)所示:
式中:l为总损失;lbbox为位置损失;lclass为分类损失;lconf为置信度损失。
其中类别预测采用Sigmoid结合交叉熵损失函数实现多类别的预测,其分类损失计算如式(5)所示:
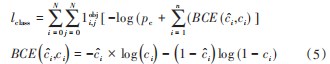
式中:lclass为分类损失;i为预测类别;ci为真实类别;
1oi,如果在i,j表示位置坐标处有物体则为1,反之则为0;pc为置信度概率;BCE为二分类用的交叉熵损失,N为划分网格的数量。
位置损失通过计算预测框和真实框之间的偏移量得出。本次采用平方差的形式予以计算,如式(6)所示:
式中:lbbox为位置损失,i,j为位置坐标,xi为真实框中心行坐标;yi为真实框中心纵坐标;wi为真实框的宽度;hi为真实框的高度;i为预测框中心行坐标;i为预测框中心纵坐标;w者i为预测框的长度;i为预测框的宽度。λcoord为位置损失系数,一般设置为1。
目标置信度为错误预测目标的概率之差,其总体的损失计算如式(7)所示:
式中:λnoobj为置信度损失系数;1表示在i,j坐标处没有物体为1,反之为0;pc为预测的置信度概率;N为划分网格的数量。
3实验结果
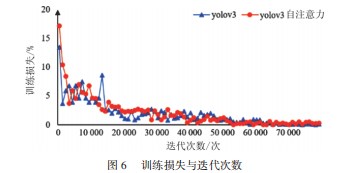
3.1 YOLOv3与YOLOv3自注意力对比
YOLOv3与基于YOLOv3的自注意力网络算法的对比如图6所示。经过80 000次的迭代训练。模型基本处于稳定且收敛的状态。
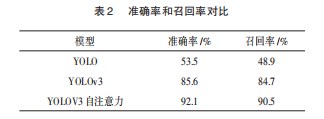
本文在测试集上验证算法,基于YOLOv3的目标检测算法在准确率和召回率上都取得一定提升。其对比如表2,基于YOLOv3的模型在测试集上的准确率达到了92.1%,召回率达到了90.5%。
3.2主干网络对比
为了进一步提升精度,本文尝试将主干网络替换为Resnet101网络。为方便对比,本文在Resnet101中也采用后3个残差块输出特征作为注意力模型的输入,如表3所示。基于Resnet101的YOLOv3方法在准确率上与YOLOv3算法相当。基于YOLOv3自注意力网络在不同的主干网络中仍然具有较好的表现。
3.3效果图展示
本文在基于YOLOV3的目标检测算法上引入自注意力机制,用于烟火图像检测,其效果如图7所示,检测效果较好。
4结束语
本文提出了一种基于YOLOv3的自注意力烟火检测算法,通过融合模型上下文信息,引入自注意力模块,引导模型自适应学习,提取关键的特征信息,从而有效地提升了模型的特征表达和检测精度。本文还通过不同模型方法的结果对比发现此结构同样有效。然而,尽管如此,研究中也发现,采用矩形框的目标检测标注框在非刚性物体的检测中具备较大的难度和缺点,矩形框无法较好地框住形态多变的目标。因此,在今后的研究中,一方面将继续研究自注意力机制在神经网络算法中的深层次扩展和应用,另一方面,也将探索目标标记检测框的设计和改进方式,以方便更好地实现对目标的检测,提升模型的表现性能。
参考文献:
[1]陈欣,施林苏,丁洪涛,等.图像识别技术在林草火灾预警中的应用及优化[J].广东通信技术,2020,40(8):61-65.
[2]黄杰,巢夏晨语,董翔宇,等.基于Faster R-CNN的颜色导向火焰检测[J].计算机应用,2020,40(5):1470-1475.
[3]李巨虎,范睿先,陈志泊.基于颜色和纹理特征的森林火灾图像识别[J].华南理工大学学报:自然科学版,2020(1):70-83.
[4]徐宏宇,续婷.一种基于颜色和纹理的优化SVM火灾识别方法[J].沈阳航空航天大学学报,2021,38(4):54-60.
[5]张伟,张先鹤.基于梯度算法边缘检测原理对火焰长度的测量[J].湖北师范大学学报(自然科学版),2020,40(1):32-36.
[6]Redmon J,Farhadi A.YOLOv3:An Incremental Improvement[J].arXiv preprint arXiv:1804.02767,2018.
[7]Olga Russakovsky,JiaDeng,HaoSu,et al.ImageNet Large Scale Visual Recognition Challenge[J].International Journal of Com‐puter Vision,2015,115(3):211-252
[8]Sermanet P,Eigen D,Zhang X,et al.Overfeat:Integrated recog‐nition,localization and detection using convolutional networks[J].arXiv preprint arXiv:1312.6229,2013.
[9]Girshick R,Donahue J,Darrell T,et al.Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Pro‐ceedings of the IEEE conference on computer vision and pattern recognition.2014:580-587.
[10]Redmon J,Divvala S,Girshick R,et al.You only look once:Unified,real-time object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition.2016:779-788.
[11]Liu W,Anguelov D,Erhan D,et al.SSD:Single Shot Multi-Box Detector[C]//European Conference on Computer Vision.Spring‐er,Cham,2016.
[12]He K,Gkioxari G,P Dollár,et al.Mask R-CNN[J].IEEE Trans‐actions on Pattern Analysis&Machine Intelligence,2017.2961-2969
[13]Lin T Y,Goyal P,Girshick R,et al.Focal Loss for Dense Ob‐ject Detection[J].IEEE Transactions on Pattern Analysis&Ma‐chine Intelligence,2017:2999-3007.
[14]Mnih V,Heess N,Graves A.Recurrent models of visual atten‐tion[C]//Advances in neural information processing systems.2014:2204-2212.
[15]Bahdanau D,Cho K,Bengio Y.Neural machine translation by jointly learning to align and translate[J].arXiv preprint arXiv:1409.0473,2014.
[16]Vaswani A,Shazeer N,Parmar N,et al.Attention is all you need[C]//Advances in Neural Information Processing Systems.2017:5998-6008.
[17]Dosovitskiy A,Beyer L,Kolesnikov A,et al.An image is worth 16x16 words:Transformers for image recognition at scale[J].arXiv preprint arXiv:2010.11929,2020.
[18]尹航,范文婷.基于Transformer目标检测研究综述[J].现代信息科技,2021,5(7):4.
[19]李昕,赵猛,董修武,等.基于改进YOLOV3算法的遥感图像油罐检测[J].中国科技论文,2020,15(3):267-273.
[20]Everingham M R,Eslami S,Gool L J,et al.The Pascal Visu‐al Object Classes Challenge[J].International Journal of Comput‐er Vision,2015(1):98-136.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/ligonglunwen/45554.html