SCI论文(www.lunwensci.com)
摘要:随着计算机视觉行业的不断发展,基于卷积神经网络的目标检测算法也受到了研究人员的重视。针对传统的YOLOv5目标检测算法中的边界框回归损失函数GIOU存在当检测框与真实框呈包含的状态时会退化到传统IOU损失函数,以及当检测框和真实框相交时在垂直和水平两个方向上存在收敛速度慢的问题,提出一种改进的YOLOv5目标检测算法。在传统YOLOv5的基准网络中添加注意力机制,然后在边界框回归损失函数中引入真实框与预测框中心的欧式距离计算预测损失,并分别计算预测框与真实框之间的纵横比作为惩罚项以达到提高回归精度以及加快收敛速度的目的,最后将改进后的YOLOv5目标检测模型应用于人脸检测进行验证。实验利用wideface人脸数据集训练,训练结果表明改进的YOLOv5目标检测算法训练中的损失只有0.013,较传统的YOLOv5目标检测算法损失减少约13.33%,准确率达到82.28%,较传统的YOLOv5目标检测算法提高2.6%。实验表明该目标检测算法能很好的应用于人脸检测中。
关键词:YOLOv5;目标检测;人脸检测;损失函数;注意力机制
Face Detection Algorithm Based on Improved YOLOv5 Sun Fubin,Zhu Zhaoyou,Chen Sichao,Chen Hongyang
(School of Mechanical and Electronic Engineering,East China Institute of Technology,Nanchang 330013,China)
Abstract:With the continuous development of the computer vision industry,target detection algorithms based on convolutional neural networks have also attracted the attention of researchers.For the bounding box regression loss function GIOU in the traditional YOLOv5 target detection algorithm,when the detection frame and the real frame are contained,it degenerates to the traditional IOU loss function.When the detection frame and the real frame intersect in both vertical and horizontal directions,there is a phenomenon of slow convergence speed.An improved YOLOv5 target detection algorithm was proposed.The attention mechanism was added to the traditional YOLOv5 benchmark network,and then the Euclidean distance between the real box and the center of the prediction box was introduced into the bounding box regression loss function to calculate the prediction loss,and the aspect ratio between the prediction box and the real box was calculated separately as a penalty term.In order to improve the regression accuracy and speed up the convergence speed,the improved YOLOv5 target detection model was finally applied to face detection for verification.The experiment used the wideface face data set for training.The training results show that the training loss of the improved YOLOv5 target detection algorithm is only 0.013,which is about 13.33%less than the traditional YOLOv5 target detection algorithm,and the accuracy rate reaches 82.28%.The experimental results show that the target detection algorithm can be well applied to face detection.
Key words:YOLOv5;target detection;face detection;loss function;attention mechanism
0引言
目标检测算法是目标识别的基础,随着机器视觉行业及相关产业的蓬勃发展,各种检测算法也得到了不同程度的优化和性能提升。
目前比较常见的目标检测算法可以分出两种类型,Two-stage方法和One-stage方法。Two-stage算法就是把检测问题分成两个阶段来处理,在第一个阶段中划出包含目标大致位置信息的候选区域(Region Proposals),然后在第二阶段对候选区域作分类以及位置细修处理。目前比较常用的Two-stage类型的方法有卷积神经网络(R-CNN);由Ren等[1]提出的基于卷积神经网络改进的FasterR-CNN算法,该算法结合特征图共享和边框回归的思想,利用RPN网络提取目标的深层网络特征,运用非极大值抑制(NMS)的方法实现了在GPU上的目标实时检测;通过多次迭代寻找最优分类器的Adaboost人脸检测算法。One-stage目标检测算法,该类算法除去了划分候选区域的步骤,可以通过一个stage直接找出目标的类别和坐标值,目前常见的one-stage算法有SSD,由俞伟聪[2]在ECCV2016提出的一种检测速度比FasterR-CNN快的检测算法;还有Redmon[3]提出的YOLO检测算法。
YOLO检测算法具有泛用性高,检测失误率低且检测速度快等优点,被广泛应用于人脸检测中。初代的YOLO检测算法运用于人脸检测方面由于其单一尺度的网格划分导致对于多尺度的人脸检测实际效果达不到预期,召回率不高。蒋纪威等[4]提出修改内部参数改变神经网络结构的方法,提高了检测的实时性,但是没有改善训练的精度。朱超平等[5]针对卷积层进行改进,在卷积层的后面增加批量归一化的操作,提升了训练速度,但是仍然没有提升训练的精度。本文提出一种改进的YOLOv5检测模型,并应用于人脸检测。首先YOLO的版本选择YOLOv5,较之前的版本增添了许多有效的数据处理方式以达到提高训练模型的精度且减少训练时间的目的,比如用于数据扩增的Mosaic、Cutout,还有改变亮度、图像扰动、加噪声、翻转、随机擦除等方式[6]。但是YOLOv5使用的边界框回归损失函数GIOU存在当检测框与真实框呈现为包含关系时会退化为IOU,无法对其相对位置关系进行区分的问题[7]。在此之上替换YOLOv5的边界框回归损失函数为EIOUloss,即通过预测框与真实框的中心点间标准化距离加速损失的收敛,并分别考虑边界框的纵横比,把纵横比拆开,分别计算真实框和预测框的长和框,进一步提升回归精度。
1 YOLOv5算法
YOLOv5是一种单阶段目标检测算法,其网络结构如图1所示。
YOLOv5目标检测算法由输入端、基准网络(Back‐bone)、Neck网络以及Head输出端四个部分组成[8]。首先是YOLOv5网络的输入端,输入图像大小为608×608×3(RGB3通道)。该阶段存在一个图像预处理步骤,即将输入的图像放缩至输入网络的608×608大小,并对输入的图像进行马赛克(Mosaic)数据增强,通过随机裁剪、随机排布和随机缩放的方式对输入图像进行拼接,不仅能提高对小目标的检测效果,还可以丰富检测目标的背景[9]。其次是基准网络部分主要采用的是Focus结构和CSP(内含残差结构)以及SPP(空间金字塔池化)结构组成。Foucs的主要作用就是切片功能,比如将原始的608×608×3的图像输入Focus结构中,再经过切片的操作之后会得到304×304×12的特征图,接着通过一个32个通道数的Conv层,输出大小为304×304×32的特征映射[10]。图中C3模块内含Bottleneck(瓶颈层),其中n代表模块中瓶颈层的个数,ture/flase代表着是否启用瓶颈层中的残差模块。提取的特征印象经过多重卷积之后送入SPP(空间金字塔池化)模块进行各种尺度的特征图的融合,先通过一个1*1的卷积使输入通道减半,之后做内核大小分别为5、9、13的最大池化,再将最大池化结果与未进行池化的数据进行连接,最后合并[11]。之后送入Neck网络,进一步提升特征的多样性和鲁棒性。最后采用3个尺度进行预测,每一个尺度都具有3个BoundingBox(即界限值),最后根据与实际框的交并比(IOU)最大的界限值来进行物体预测[12]。图像可视化处理过程如图2所示。
2改进的YOLOv5算法
2.1基准网络结构改进
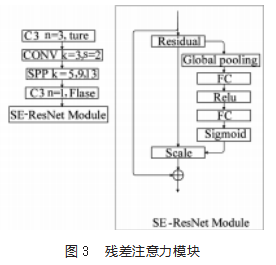
在传统的基准网络结构(Backbone)的最后一层添加一层残差注意力模块(SE-RsNet Module),改进后的基准结构网络如图3所示。
该模块先将输入的特征图通过一次全局平均池化(Global pooling)进行压缩,经过压缩后输出一个1*1*512的特征向量,该特征向量通过激励后进行Scale操作,将1*1*512的特征向量进行通道权重相乘,即将SE模块计算出来的各通道权重值分别和原特征图对应通道的二维矩阵相乘,得到输出结果。该模块虽然加大了总计算量,但是提升了参数量,使检测模型更加关注识别物体,而且因为残差结构的存在,保证了改变后的模型不会相较原来的模型更差。
2.2算法改进
2.2.1 YOLOv5算法存在的缺陷
目标检测任务的损失函数一般由Objectness score损失(置信度损失)、class probability score损失(分类损失)以及bounding box损失(边界框回归损失)3部分组成。YOLOv5算法采用GIOU作为边界框回归损失函数[13]。GIOU损失函数克服了IOU损失函数在预测框与真实框不相交时无法反馈两个框之间的距离远近的问题,并且同时继承了IOU的优点。计算损失公式如下:
其中,B是预测框,Bgt是真实框,C包含预测框和真实框的最小凸闭合框。从GIOU的公式中可以看出GIOU类似IOU采用预测框与真实框之间的距离来度量损失函数,并且对尺度不够敏感IOU∈[0,1],得到GIOU∈[-1,1],所以GIOU不仅仅关注预测框与真实框之间的重叠区域,还关注其他的非重叠区域,能更好地反映预测框与真实框的重合度,当完全重合时IOU=GIOU=1,当预测框与真实框不重合时,不重合的程度越高,GIOU的值则越接近-1。
但是根据式(7)可以看出,当预测框与真实框框呈包含状态时无法获得其相对位置关系。如图4所示。
在这一情况下,3张图的LGIOU是相等的,由于GIOU十分依赖IOU,所以在垂直方向上的误差很大,很难收敛,导致GIOU不够稳定[14]。
2.2.2改进的YOLOv5损失函数
针对上述GIOU存在的问题,提出使用EIOUloss函数替代GIOU。EIOU通过将GIOU中引入最小外接框来最大化重叠面积的方法替换为两个框中心点的标准化距离,并添加一个影响因子和用边长作为惩罚项,该影响因子考虑了预测框纵横比拟合真实框的纵横比。损失公式如下:
该损失函数包含重叠损失LIOU,宽高损失Lasp以及中心距离Ldis损失3个部分,其中bgt是真实框的中心点,b是预测框的中心点,ρ代表两个中心点之间的欧氏距离,c代表包含真实框和预测框的最小闭合框的对角线距离,w和h分别是预测框的宽度和高度,wgt和hgt分别是真实框的宽度和高度,Cw和Ch分别是覆盖真实框和预测框的最小外接边框的宽度和高度。
3实验与结果分析
3.1实验平台
本文搭建的实验环境为:Intel core i7-115200处理器,基准频率2.3 GHz,GPU为RTX 2060,6 GB显存,Windows操作系统。
3.2结果分析
本文采用由香港大学发布的人脸数据集Wide Face,其中包含了各种不同的光照状态、运动状态、姿势、远近、肤色和不同程度遮挡的人脸,从61种人脸分类中各取出20张用作人脸数据集训练,迭代次数为默认的300次,训练集与验证集划分为80%和20%。训练获得的损失函数对比如图5~6所示。通过对比可以看出,改进后的YOLOv5检测模型的损失低于未改进的YOLOv5检测模型,大概提升14.2%,说明改进后的YOLOv5检测模型具有更好的鲁棒性。
改进YOLOv5检测模型训练的PR曲线如图7所示。训练后的mAP 0.5(IOU为0.5时Precision和Recall围成的面积)和mAP 0.5:0.95(IOU从0.5到0.95,步长为0.05,上的平均mAP)的值以及准确率比较如表1所示。可以看到,改进后的YOLOv5目标检测算法较传统的YOLOv5检测算法拥有更高的准确率和精度。
将训练获得的权重文件应用于人脸检测,每一帧图片的处理时间平均只需要0.03 s,实时视频流处理可以保持33的FPS,保证经过算法检测后输出的视频图像的流畅性,效果如图8~10所示。从图中可以看到,改进后的YOLOv5检测算法训练获得的权值文件应用于实际的人脸检测中不仅保持了较高的检测速度,并且拥有较高的准确率,能够忽略小人脸检测、多目标检测和人脸肤色、表情差异产生的影响。
4结束语
本文提出了改进YOLOv5目标检测算法的具体方法,通过在损失函数中引入真实框与预测框中心点间的欧式距离和预测框与真实框的长比及宽比作为损失惩罚项以加快函数收敛速度和提高回归精度,另外在基准网络结构中的最后一层增加一残差注意力模块,提升参数量,使检测模型更加关注识别物体。实验表明改进的YO‐LOv5目标检测算法在wideface数据集上的训练准确率达到88.28%,较传统YOLOv5准确率提升2.6%,训练过程中的损失为0.013,较传统YOLOv5损失减小13.33%,拥有更好的鲁棒性。该目标检测算法解决了传统YOLOv5目标检测算法中当预测框和真实框呈包含状态时无法预测两框之间相对位置关系以及在垂直和水平方向上收敛速度慢的问题,提升了回归精度的同时保证了人脸检测过程中要求的实时性,能够较好地应用于实际人脸检测项目中。
参考文献:
[1]Ren Shaoqing,He Kaiming,Girshick Ross,et al.Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Net‐works.[J].IEEE transactions on pattern analysis and machine in‐telligence,2017,39(6):1137-1149.
[2]俞伟聪,郭显久,刘钰发,等.基于轻量化深度学习Mobilenet-SSD网络模型的海珍品检测方法[J].大连海洋大学学报,2021,36(2):340-346.
[3]Redmon J,Divvalas S,Girshick R,et al.You only look once:Uni‐fied,real-time object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016.
[4]蒋纪威,何明祥,孙凯.基于改进YOLOv3的人脸实时检测方法[J].计算机应用与软件,2020,37(5):200-204.
[5]朱超平,杨艺.基于YOLO2和ResNet算法的监控视频中的人脸检测与识别[J].重庆理工大学学报(自然科学),2018,32(8):170-175.
[6]吕禾丰,陆华才.基于YOLOv5算法的交通标志识别技术研究[J].电子测量与仪器学报,2021,35(10):137-144.
[7]谭显东,彭辉.改进YOLOv5的SAR图像舰船目标检测[J].计算机工程与应用,2022,58(4):247-254.
[8]贺怀清,王进,惠康华,等.基于YOLO的多尺度并行人脸检测算法[J].计算机工程与设计,2020,41(9):2559-2565.
[9]项新建,宋晓敏,郑永平,等.基于MobileNet-YOLO的嵌入式人脸检测研究[J].中国农机化学报,2022,43(4):124-130.
[10]黄绍欣,田秀云.基于深度学习的人脸检测算法研究[J].机电工程技术,2022,358(1):126-129.
[11]赵亮,刘世鹏.全局与局部图像特征自适应融合的小目标检测算法[J/OL].控制与决策:1-9[2023-02-14].https://doi.org/10.13195/j.kzyjc.2021.1800.
[12]吴志洋,卓勇,廖生辉.改进的多目标回归实时人脸检测算法[J].计算机工程与应用,2018,54(11):1-7.
[13]邓珍荣,白善今,马富欣,等.改进YOLO的密集小尺度人脸检测方法[J].计算机工程与设计,2020,41(3):874-879.
[14]吴育武.适应变电站智能安全监控的运动目标检测及人脸快速识别方法[J].机电工程技术,2019,332(11):52-55.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/ligonglunwen/58754.html