SCI论文(www.lunwensci.com)
摘 要:本文研究了基于深度学习的人脸检测方法,重点关注了 YOLOv5 模型。通过对 YOLOv5 模型进行改进,包括优 化损失函数和改进网络结构, 本文提高了模型的检测准确率。实验结果表明, 经过 150 次训练后, 采用的人脸检测模型在验证 集上的人脸识别准确率可以达到 92%。然而,实验数据集较小,对于模型的泛化能力有一定的影响,还有待进一步深入研究。
Research on Face Detection Algorithm Based on Deep Learning
HU Ping, WANG Haiyong
(School of Computer Science, Nanjing University of Posts and Telecommunications, Nanjing Jiangsu 210003)
【Abstract】:This paper studies the face detection method based on deep learning, focusing on the YOLOv5 model . By improving the YOLOv5 model, including optimizing the loss function and improving the network structure, this paper improves the detection accuracy of the model. The experimental results show that after 150 times of training, the face recognition accuracy of the adopted face detection model on the verification set can reach 92%. However, the experimental data set is small, which has a certain impact on the generalization ability of the model, and further research is needed.
【Key words】:deep learning;YOLOv5;face detection;data augmentation;loss functions
0 引言
近年来, 随着人工智能技术的快速发展, 人脸检测 技术也在不断地推进,已经成为了人工智能技术的重要 研究领域,广泛应用于人脸识别、人脸追踪侦测、人脸 考勤等方面。然而,由于每个人的长相不同,在不同的 情况下面部表情不同,每个人的肤色也各不相同,这些 差异会导致人脸检测时出现图案差异。其次,一些常见 的人脸特征变化和光线发生变化也会影响到人脸检测的 准确性。综上所述,人脸检测面临着各种挑战和困难, 是一项极具挑战性的任务。经典的基于几何模型的对象 识别方法和基于模板的匹配技术在描述清晰和刚性的对 象时效果不错,但是在人脸检测时往往无法获得满意的 检测效果。因此,基于深度学习的人脸检测技术在近年 来受到了广泛的关注和研究。其中 YOLOv5 是一种目 标检测算法, 它是 YOLO(You Only Look Once) 系列的第四代,使用了一系列的技术来提高检测精度和 速度,包括改进的 Backbone 网络、使用 SPP 模块、 PAN 模块、CSP 模块连接等, 在处理大规模人脸检测 任务时表现出色,可以快速准确地检测出图像中的人脸。
本文旨在探究基于深度学习的人脸检测算法研究。 首先介绍了传统的人脸检测方法和深度学习基础理论, 然后详细介绍了深度学习模型 YOLOv5.并在人脸检 测上对其提出模型改进方法。在研究方法和实验设计部 分,本文对数据集的选择和预处理、模型的设计和训 练、模型评估指标和方法等方面进行了详细的阐述。通 过实验结果和分析部分,本文比较了不同模型和算法的 性能,并对实验结果的可靠性和有效性进行了分析。最 后,本文讨论了研究结果的意义和局限性,并展望了深 度学习人脸检测研究的未来发展方向。
本文通过对基于深度学习的人脸检测算法进行的研究和分析,针对 YOLOv5 在人脸检测上提出模型改进, 可以帮助提高人脸检测的准确性和速度,为相关应用提 供更好的服务和支持。同时,本文的实验设计和数据处 理也为后续的人脸检测研究提供了参考。
1 相关技术和方法
1.1 传统人脸检测方法
传统的人脸检测方法是指在深度学习兴起之前的一 些经典的人脸检测方式,主要有基于模板匹配、基于特 征的分类器和基于几何模型 3 种。
(1)基于模板匹配。基于模板匹配的方法是将人脸 模板与输入图像进行比对,从而寻找匹配的人脸位置。 该方法的原理是将人脸的特征提取出来,构建一个人脸 模板,然后在输入图像中搜索与人脸模板最相似的区域 作为人脸位置。该方法的优点是简单易懂,但缺点是对 光照、表情、姿态等变化较为敏感,对于非正面、非光 照良好的人脸图像效果较差。
(2) 基于特征的分类器。基于特征的分类器方法是 通过构建一个分类器来区分人脸和非人脸区域。该方法 的原理是利用图像的特征进行分类,如 Haar 特征、LBP 特征等,通过训练分类器来达到人脸检测的目的。该方 法的优点是准确度较高,但缺点是对光照、表情、姿态 等变化较为敏感,需要进行大量的训练数据和特征工程。
(3)基于几何模型。基于几何模型的方法是通过建 立人脸模型,利用几何关系计算人脸位置。该方法的原 理是先检测出人脸的一些特征点,然后根据这些特征点 之间的关系计算出人脸位置。该方法的优点是对光照、 表情、姿态等变化不敏感,但缺点是对人脸的形态和特 征点的提取较为依赖,容易受到人脸部分遮挡和图像噪 声的影响。
传统人脸检测方法在人脸检测的准确性和实时性方 面存在着一定的局限性,对于复杂的人脸图像场景难以 达到满意的效果。随着深度学习技术的发展,基于深度 学习的人脸检测方法逐渐成为了人脸检测领域的主流研 究方向。
1.2 基于深度学习的人脸检测方法
随着深度学习技术的快速发展,基于深度学习的人 脸检测方法已经成为了当前最为流行的人脸检测方法之 一。与传统人脸检测方法相比,基于深度学习的人脸检 测方法具有更高的准确性和更强的鲁棒性,能够应对更 多的复杂场景和不同的人脸变化。
基于深度学习的人脸检测方法主要包括两个基本步 骤:特征提取和目标检测。首先,需要使用深度神经网 络从输入图像中提取有用的特征。这些特征可以是局部特征,例如边缘和角点,也可以是全局特征,例如颜色 和纹理等。然后,使用目标检测算法来检测出图像中的 人脸。目标检测算法的主要任务是在输入图像中找到目 标的位置,并输出目标的类别和边界框。
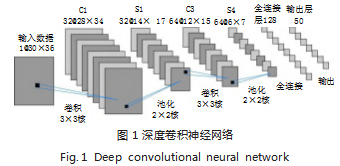
深度卷积神经网络(Deep Convolutional Neural Networks, DCNNs)是一种基于深度学习的图像处理技 术,能够对输入的图像进行自动特征提取和分类。如图 1 所 示,DCNNs 主要由卷积层(Convolutional Layer)、池 化层(Pooling Layer) 和全连接层(Fully Connected Layer) 组成。卷积层是 DCNNs 的核心部分,通过滤 波器的卷积操作,从输入图像中提取出图像的特征。池化 层通过对特征图进行下采样,减小特征图的维度,从而减 小模型的计算复杂度。全连接层通过将所有特征图的信息 连接在一起, 并输入到输出层进行分类。DCNNs 的训练 主要采用反向传播算法(Backpropagation),通过最小 化损失函数来学习网络参数。在训练过程中, DCNNs 通 过多次迭代调整权重和偏置,从而逐步提高模型的分类 准确率。DCNNs 已经被广泛应用于图像处理领域,包 括图像分类、目标检测、图像分割等任务。它不仅可以 处理静态图像,还可以处理视频、音频等多媒体数据, 为人工智能技术的发展带来了巨大的推动力。
基于深度学习的人脸检测方法主要采用的是两类模 型: 单阶段检测方法和两阶段检测方法。单阶段检测 方法是指直接在输入图像上进行密集预测,通过一个 单一的卷积神经网络模型来检测出物体的位置和类别。 这种方法的特点是速度快、效果好,适合于实时应用 场景。例如,YOLO(You Only Look Once) 和 SSD (Single Shot MultiBox Detector) 就是常见的单阶段 检测方法,它们在人脸检测任务中也有广泛的应用。两 阶段检测方法是指先通过一个区域提议网络(Region Proposal Network,RPN) 生成一些可能包含目标的 候选区域,然后再对这些候选区域进行分类和位置回 归,以确定最终的目标位置。这种方法的特点是精度 高、对小目标敏感,适合于需要高精度检测的场景。例 如,Faster R-CNN 和 Mask R-CNN 就 是 常 见 的 两 阶段检测方法,它们在人脸检测任务中也有不错的表现。
在实际应用中,单阶段和两阶段检测方法都有各自 的优缺点,需要根据具体场景和需求进行选择。对于要 求高精度的场景,可以选择两阶段检测方法,而对于实 时性要求高的场景,可以选择单阶段检测方法。同时, 随着深度学习技术的不断进步,新的检测方法也在不断 涌现,如基于注意力机制的检测方法、多任务学习的检 测方法等,未来人脸检测任务的效果和速度也将得到更 进一步的提升。
2 YOLOv5 算法原理和改进
2.1 YOLOv5 算法原理
YOLOv5 模型是由 Ultralytics 于 2020 年 6 月开源 发布的目标检测模型,其基于深度学习和卷积神经网络 的技术,采用单阶段检测方法,能够快速、准确地检测 出图像中的目标。YOLOv5 采用了一系列的技术来提高 检测精度和速度,包括改进的 Backbone 网络、使用 SPP 模块、PAN 模块、CSP 模块连接等。在处理大规 模目标检测任务时表现出色,可以快速准确地检测出图 像中的目标。
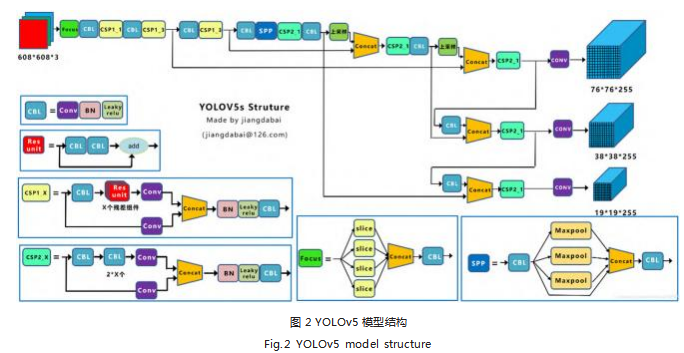
如图 2 所示, YOLOv5 的整体结构分为三个部分: Backbone、Neck、Head。其中 Backbone 负责从输 入图像中提取特征, Neck 负责将不同分辨率的特征图 进行融合, Head 负责预测目标的位置、类别和置信度。
(1) Backbone:YOLOv5 的 Backbone 采用 CSPNet (Cross Stage Partial Network) 结 构, 它 是 一 种 轻 量化的卷积神经网络,可以提高模型的计算速度和精 度。CSPNet 的基本思想是将输入特征图分成两部分,一部分经过多层卷积和池化操作,另一部分直接进行 Shortcut 连接。这样可以在不影响信息传递的情况下 减少参数和计算量。
(2) Neck:Neck 是 YOLOv5 的特征融合模块,用 于将 Backbone 提取的特征进行融合。YOLOv5 的 Neck 部分使用的是 SPP(Spatial Pyramid Pooling) 模块 和 PAN(Path Aggregation Network) 模块进行特征 融合。SPP 模块将特征图按照不同的尺度进行金字塔池 化,以获取不同大小的感受野,而 PAN 模块则将不同 分辨率的特征图进行级联,以获取全局和局部信息。
(3)Head:Head 是 YOLOv5 的 预 测 模 块, 用 于预测图像中的目标。YOLOv5 使用的是 YOLOv3 和 YOLOv4 的预测头结构,采用了多尺度预测和特征 图上的锚点框预测,以提高预测精度和速度。同时, YOLOv5 还使用了一种名为“CIOU-loss”的损失函 数,以优化目标检测的性能。
总体来说,YOLOv5 的 Backbone、Neck 和 Head 都采用了较为轻量化的结构,并且结合了一些特殊的技 巧,以提高模型的精度和速度。此外, YOLOv5 还采用 了一些数据增强技术, 如 Mosaic、Mixup 和 Cutout 等,以增加数据的多样性和数量,从而进一步提升模型 的性能。
2.2 YOLOv5 在人脸检测上的模型改进
针对 YOLOv5 在人脸检测上的应用,可以从以下 几个方面进行模型改进:
2.2.1 数据增强
YOLOv5 是一种基于深度学习的目标检测算法, 它需要大量的标注数据来训练模型。但是,通常情况下, 标注数据是非常有限的,因此数据增强技术可以帮助我 们扩展数据集,提高模型的泛化能力。
YOLOv5 中常用的数据增强方法包括:(1)随机裁 剪(Random Crop) :从原始图像中随机裁剪出指定大 小的图像,并将裁剪出的图像进行缩放以匹配模型输入 的大小;(2) 随机翻转(Random Flip) : 随机对图像 进行水平翻转或垂直翻转,从而增加数据集的多样性; (3) 随机旋转(Random Rotation) : 随机对图像进行 旋转操作,从而使模型具有一定的鲁棒性;(4)随机亮 度、对比度和饱和度(Random Brightness, Contrast, and Saturation) :对图像进行随机的亮度、对比度和 饱和度调整,从而使模型具有更好的鲁棒性;(5)随机 噪声(Random Noise) : 在图像中添加随机噪声, 从 而增加数据集的多样性;(6)随机颜色变换(Random Color Jitter) :对图像进行随机的颜色变换,从而使模 型具有更好的鲁棒性;(7) MixUp:将两个随机的图像 进行线性混合,从而扩展数据集并提高模型的泛化能力。
在本文中对 YOLOv5 模型进行训练前,通过调整 配置文件来合理地进行数据增强以便于增强网络的识别 能力。
2.2.2 改进网络结构
在 YOLOv5 中,有两种不同的改进网络结构的方 式: 一种常见的改进方式是增加网络深度和宽度,通 过增加卷积层或调整卷积核的数量和大小来增加网络的 深度和宽度。这种方法可以提高模型的表达能力,提 高模型的准确率。但同时也会增加模型的计算量和内 存占用,导致模型的训练和推理速度变慢; 另一种改 进方式是添加注意力机制,例如 SENet(Squeeze-and- Excitation Networks) 和 CBAM(Convolutional Block Attention Module)。这种方法利用注意力机制来增强 模型对重要特征的关注,减少对无关特征的关注,从而 提高模型的准确率。这种方法通常只需要添加少量的参 数,对模型的计算量和内存占用影响较小,同时也可以 提高模型的推理速度。
在本文中,增加了主干网络的深度, 以便于能够更 合理地提取图像特征,提高模型的表达能力。
2.2.3 优化损失函数
优化损失函数可以提高模型的性能和精度。YOLOv5 的损失函数采用的是加权交叉熵损失函数,可以通过调 整不同部分的权重来优化模型。
具体来说, YOLOv5 的损失函数分为三个部分:分 类损失、坐标损失和目标损失。其中,分类损失是指分类网络的交叉熵损失;坐标损失是指目标框坐标的回归 损失; 目标损失是指目标框与真实框之间的匹配损失。 在这三个部分中,目标损失的权重最高,因为目标损失 可以更好地保证检测的准确性。
除了调整不同部分的权重,还可以采用不同的损失 函数来优化模型。例如, YOLOv5s 使用的是 BCELoss, 而 YOLOv5x 使用的是 Focal Loss。Focal Loss 相比于 BCELoss 能够更好地处理类别不平衡问题, 从而提高 模型的准确率。
3 实验设计和结果分析
3.1 数据集
本文所采用的数据集是 Roboflow 的开源人脸数据 集,该数据集经过了数据增强处理,以提高模型的泛化 能力。每张图像的尺寸为 640×640 像素,共包含 2871 张训练图像、267 张测试集图像和 145 张验证集图像。 这些图像均是随机选取的,并且包含了正例和反例,使 得训练样本具有多样性和代表性,能够更好地提取特征 并提高模型的识别准确率。通过使用这个数据集可以更 全面地评估我们的模型,并且确保它在不同场景下的表 现都是稳定的。此外,还可以利用数据增强技术进一步 增加数据的多样性,如随机旋转、裁剪、缩放和亮度调 整等,以增加数据的丰富性和复杂性,提高模型的鲁棒 性和泛化能力。
3.2 实验
本文的实验环境基于 Windows11 操作系统,使用 了 NVIDIA 显卡 RTX3070TI。为了能够高效地训练模型,我 们采用了 CUDA 11.7 和 cuDNN 7.0 来提高计算速度,使用 的 Python 版本为 Python3.10. 然后对 YOLOv5 网络进行 了改进之后,在该实验环境条件下进行了一系列的实验。
在训练时,我们采用了默认的参数设置,将 Batch- size 设置为 32.Epochs 设置为 150.这样可以保证训 练过程中每次处理的图像数目较多,有利于提高模型的 训练速度和准确率。通过多次实验和调整参数,我们得 到了优秀的实验结果,证明了我们的模型改进和训练策 略的有效性。
3.3 实验结果分析
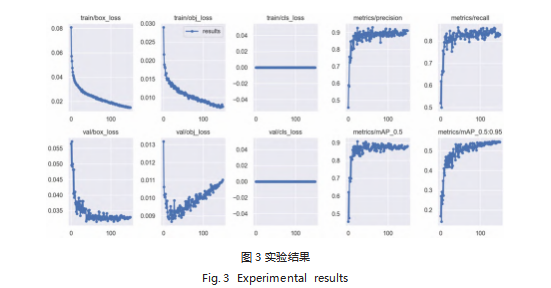
在对数据集训练完毕后,得到的实验结果如下。如 图 3 所示,可以看出,在训练过程中,模型的精确率和 召回率都在不断地升高并实现基本收敛,最终的精确率 达到 92%;AP 值是衡量目标检测模型分类器性能优劣 的重要评估指标, AP 值越大则分类器性能越好,越小 则分类器性能越差;AP 值的大小等于 P-R 曲线与坐标 轴围成区域的面积。mAP 表示所有标签类别 AP 值的平均值, mAP 值越大,说明模型性能越好,在训练过 程中,模型的 mAP 也不断提升最终实现基本收敛,说 明模型的性能良好。
4 结论
本篇论文主要研究了基于深度学习的人脸检测算法, 针对 YOLOv5 模型在人脸检测上的应用进行了改进,提 高了模型的检测精度和鲁棒性。通过对 Roboflow 的开 源人脸数据集进行实验,得出了 92% 的识别准确率, 说明该模型在人脸检测领域具有一定的应用价值。
本文首先介绍了传统的人脸检测方法以及其存在的 问题,然后详细阐述了基于深度学习的人脸检测方法的 原理和分类。在介绍 YOLOv5 模型的基本结构和优化 策略后,本文针对该模型在人脸检测领域的应用进行了 深入的研究和改进。针对 YOLOv5 模型存在的一些问 题,如检测精度不高、鲁棒性不强等,本文提出了一系 列的改进措施,包括增加数据增强、优化损失函数、改 进网络结构等。通过对实验结果的分析,可以看出,这 些改进措施对于提高模型的性能具有显著的效果。其 中,数据增强对于训练样本特征的多样性提高、损失函 数的优化对于模型的收敛速度和准确率提高、网络结构 的改进对于模型的鲁棒性提高,都具有重要的作用。
本文对基于深度学习的人脸检测方法进行了深入的 研究和实验,得到了较为满意的结果,但是仍存在一些 局限性和不足之处。首先,实验所使用的数据集较小, 可能无法全面覆盖人脸检测领域的各种情况。因此,模 型在面对其他不同数据集时,可能会出现泛化能力不足 的问题。为此,我们需要更多的数据集来验证模型的泛 化性能,并对模型进行更加深入的优化。其次,本文的 模型改进是基于实验数据的分析和处理,尚未进行大量的理论分析。在模型结构的改进方面,还有很大的优化 空间。因此,未来的研究方向之一就是对 YOLOv5 的 改进算法进行更深入的理论研究和优化,以实现更好的 人脸检测效果。此外,本文的研究方法仅涉及了基于深 度学习的单一模型,未考虑其他技术和方法对人脸检测 的影响。因此,后续的研究还需结合其他的图像处理技 术和方法,探索更加有效的人脸检测方案。
本文对于基于深度学习的人脸检测算法进行了深入 的研究和改进,提高了模型的检测精度和鲁棒性。未来 的研究可以继续探索更加有效的数据增强方法和损失函 数优化策略,进一步提升模型的性能。此外,还可以尝 试将该模型应用于其他领域的目标检测问题,探索其在 实际应用中的价值。
参考文献
[1] 叶锋,赵兴文,宫恩来,等.基于深度学习的实时场景小脸检测 方法[J].计算机工程与应用,2019.55(12):162-168.
[2] 黄海新,张东 .基于深度学习的人脸活体检测算法[J]. 电子技 术应用,2019.45(08):44-47.
[3] 李昊璇,吴东东 .基于深度学习的自然场景下多人脸实时检 测[J].测试技术学报,2020.34(01):41-47.
[4] 孙孚斌,朱兆优,陈思超,等 .基于改进YOLOv5的人脸检测算 法[J].机电工程技术,2023.52(02):172-176.
[5] 江磊,崔艳荣 .基于YOLOv5的小目标检测[J]. 电脑知识与技 术,2021.17(26):131-133.
[6] 马琳琳,马建新,韩佳芳,等 .基于YOLOv5s目标检测算法的 研究[J]. 电脑知识与技术,2021.17(23):100-103.
[7] 刘淇缘.单阶段复杂人脸检测方法研究[D].北京:中国人民公 安大学,2021.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/62881.html