SCI论文(www.lunwensci.com)
摘 要 :分析中小企业在面临日常分布式系统运维过程中,遇到的维保难和成本高的痛点。基于分布式系统跟踪规范 OpenTracing,提出了轻量级的分布式系统日志跟踪设计方案。并根据 Spring 框架代码开发出设计方案,分别对方案的核心 代码逻辑、单元测试、集成测试、性能测试进行详细介绍与分析,证实方案在分布式系统的生产环境的可行性。业界 APM 产 品并非企业的唯一选择,还可以自定义实现低成本低侵入轻量级的分布式跟踪。此方案可支撑中小企 IT 运维人员快速精准定 位分布式系统的异常。
Design and Implementation of Distributed Log Tracing Based on OpenTracing
ZENG Yingqing1. TANG Hui2. XU Lijuan1
(1.School of Data Science, Guangzhou Huashang College, Guangzhou Guangdong 511320;
2.GAC-Toyota Motor Co., Ltd., Guangzhou Guangdong 510000)
【Abstract】:This paper analyzes the difficulties and high costs encountered by small and medium-sized enterprises in the process of daily distributed system operation and maintenance. Based on the distributed system tracing specification OpenTracing, a lightweight distributed system log tracing scheme is proposed . The design scheme is developed according to the Spring framework code, and the core code logic, unit testing, integration testing and performance testing of the scheme are introduced and analyzed in detail, which proves the feasibility of the scheme in the production environment of distributed system. Industry APM products are not the only choice for enterprises, but can also be customized to achieve low-cost, low-intrusion, lightweight distributed tracking. This solution can support IT operation and maintenance personnel of small and medium-sized enterprises to quickly and accurately locate anomalies in distributed systems.
【Key words】:distributed;tracing;log
0 引言
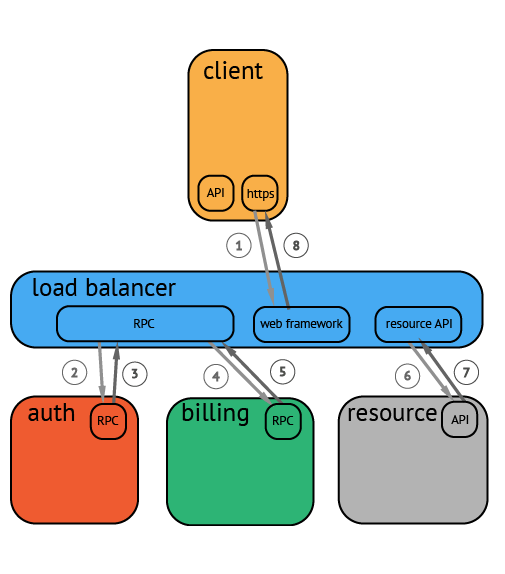
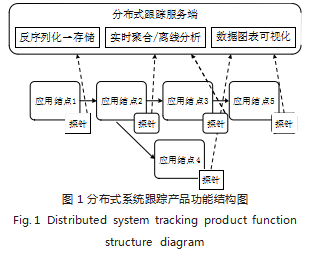
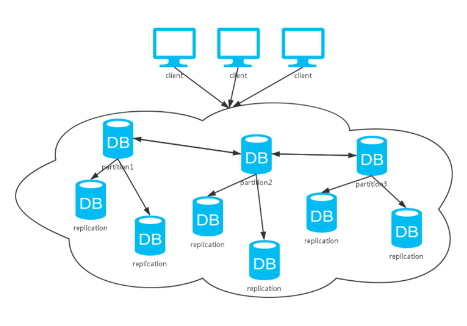
分布式跟踪技术主要用于日常运维工作,它是一种 系统内与系统间的业务数据流追踪方案。用途是让运维 人员在复杂长链路系统中快速定位异常问题。2016 年 “OpenTracing Specification Council( 开源跟踪规范委 员会 )”成立,目的是统一异构系统之间系统全链路跟 踪规范。国外基于此规范实践的追踪方案数不胜数,如: AWS 的 DataDog 服务用于很多车联网系统追踪、也有Uber 自研的 Jaeger、我国华为公司吴晟先生自研的开 源项目 SkyWalking 等 [1]。它们使用 C/S 架构,向每个 分布式结点上部署旁路“探针”客户端, “探针”不停地 收集应用程序的观测数据;并周期性地向服务端发送大 量数据 [2.3] ,服务端通过大数据聚合计算,生成可视化的 图表(如图 1 所示),支撑运维人员全局把握分布式系统 的异常情况。但是在实际分布式系统运维保障中,企业 需要购入这些基于 OpenTracing 的产品或者自行构建部署开源产品,其一,要求企业准备配置较高的服务器 部署产品以及较高的内网带宽,可能为企业带来较高的 基础设施成本;其二,需要在应用系统上部署“探针”, 探针本身也是程序,将消耗占用一部分应用系统既有的 资源。本案将提出一种基于 OpenTracing 思想, 使用 Java 语言定制跟踪小插件,利用系统日志将跟踪信息可 视化,达到最轻量级跟踪可用。适合一些中小型企业低 成本地实现分布式系统链路追踪。
1 OpenTracing 介绍
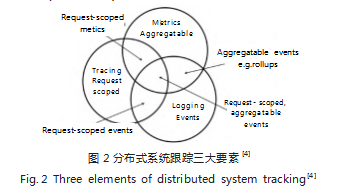
2017 年德国柏林 go 语言微服务框架作者 Peter Bourgon 提出了分布式跟踪的创世论文,他认为针对 分布式系统跟踪关键要素有三点: 度量、跟踪、日志 (如图 2 所示)。这三项要素就好比,一个病人到医院求 医,医生通过问诊病人的经历 ( 日志 ) 了解病症,通过 影响检查 ( 跟踪 ) 定位问题发现病因,通过化验不断获 取指标 ( 类比度量 ) 协查疾病变化的过程。
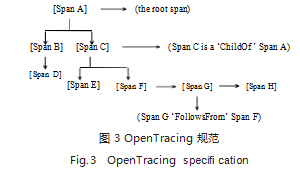
跟踪的生命周期是请求级别的。一个 HTTP 请求从 客户端到达服务器,经过的 web 容器、任意一段程序 代码、到达数据库、响应返回到客户端都可能成为跟踪 点。OpenTracing 规范把跟踪点称为 Span, 意为一个 时间跨度的调用。Span 之间的关系,分为 ChildOf 和 FollowsFrom。ChildOf 存在父子 Span, 父调用里面包含子调用,父调用的过程结果强依赖于所有子调用过 程结果。而 FollowsFrom 也存在父子 Span,但并非 强依赖关系,场景可以是主线程和子线程的关系,下游 系统通过消息队列发送异步消息给上游系统。如图 3 所 示, 一个父 SpanA 发起调用, 整个过程里面包括 B 和 C,且强依赖于 B 和 C 的结果。所以 BC 与 A 之间是 ChildOf 的关系。同理,C 又强依赖于 EF, 但是 F 与 G 与 H 之间则可能是子线程或异步队列任务。所以 A 的调用关系到达 DEF 为终结调用结点 [5]。
在 Google 内部的非开源分布式跟踪系统 Dapper 论 文中, 提及到 ParentID 的概念, 即为每一个上游 Span 必须包含所有下游 Span 的 ID[6]。如此一来,从请求生成 到响应返回,每一跟踪点都贯穿着分布式系统的上下文。
除了 Span 关系之外,OpenTracing 还要求 Span 在上下文中携带时间、源调用者和被调用者等信息。回 归到 Google 论文,如果把这么多信息从根 Span 一直 传递到终结 Span 结点将会为分布式系统带来严重的内 存空间开销。根据 Peter Bourgon 的理论,利用程序 日志上下文已经携带的信息替代 Span 上下文传递即可 解决资源消耗问题。
2 跟踪点设计
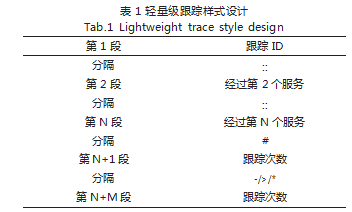
2.1 样式设计
Span 样式设计如表 1 所示,第 1 段为父 Span 本 身,由于它必须在业务集群全局内保证唯一,本案使用 雪花 ID 作为生成基础,配合远端的缓存锁实现分布式 集群内“生成时唯一”[7];第 2 段至第 N 段属于跨系统 履历,通过记录跨过第几个系统,保证了 Span 在业务 集群内“运行时唯一”,当 A 服务向 B 服务发起请求, 然后 A 服务继续执行自己的任务 X, B 服务分别接收到 请求并记录的跟踪点会与任务 X 的跟踪点重复,产生 Span 的碰撞,造成大量的运维歧义; 第 N+1 段至第 N+M 段属于系统内跟踪次数的记录,为了和日志上下 文联动,那么当应用程序发生 1 次日志打印时,即会发 生 1 次记录跟踪,记录的数值是跟踪总次数,如果发生 了系统内跨层 (“- ”)、跨系统 (“>”)、跨线程 (“*”),将用不同分隔符区分并重新记录跟踪次数 [8]。
举例,一个 Span 样式为 153511943042446
9504::1#2-1*2>2-2. 意思为分布式系统第一个结点 服务生成了 1535119430424469504 作为父 Span,并在 程序控制层内打印了 2 条日志,进入了服务层,又打印 了 1 条 日 志, 此 时 Span 为 1535119430424469504#2- 1;之后,程序在服务层执行了一个异步任务,并在异步 任务内发生了 2 次日志打印, Spa 为 153511943042446 9504#2-1*2; 此后,第一个结点服务发起了一次跨系 统的远程调用,并在第二个结点服务的控制层和服务层 都留下了日志记录, 终结 Span 为 153511943042446 9504::1#2-1*2>2-2.
2.2 程序设计
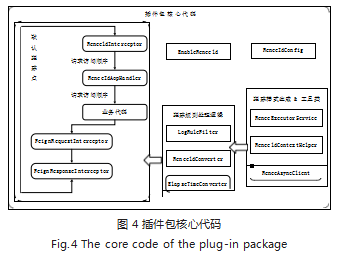
低侵入地实现将跟踪点嵌入到每一个分布式系统中 是设计的核心原则,以插件包的形式实现程序代码的打 包和部署 [9]。插件包核心代码如图 4 所示,主要分为 4 部分。第 1 部分是在业务代码的入口和出口位置静默 嵌入跟踪点。第 2 部分是跟踪点整合日志打印时候的 规则逻辑。第 3 部分是日志规则委托生成跟踪点样式。 第 4 部分为插件开关以及前 3 部分定义如何自动注入 Spring 容器。
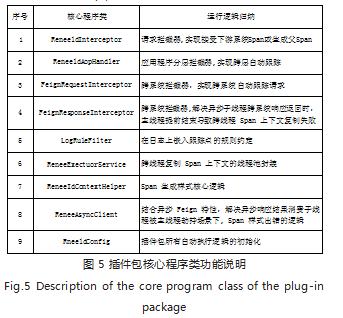
分布式系统的请求首先会被插件包 ReneeIdInter ceptor 拦截,主要用于判断是否有来自于下游系统的 Span 上下 文,并在请求线程本地变量里缓存 Span 上下文信息。其 后就会被 ReneeIdAopHandler 拦截,主要用于判断请求 准备进入程序的逻辑层 / 服务层 / 数据访问层,并进行相 应的跟踪记录。若业务代码中,需要发生跨系统访问,就 会触发 FeignRequestInter-ceptor 和 FeignResponse Interceptor 的跟踪嵌入。另外,业务代码使用到多线 程异步任务,可以直接使用已自动注入到 Spring 托管 的 ReneeExecutorService 跨线程跟踪线程池。上述所 有静默拦截跟踪都与日志记录有关,一旦发生日志打印, LogRuleFilter 通过日志上下文以及规则逻辑自动判断, 是否需要结合 ReneeIdContextHelper 缓存 Span 上下 文进行跟踪。如图 5 所示区分各部分程序功能。
3 测试
3.1 单元测试
由 于 ReneeIdContextHelper 是 解 耦 独 立 运 行, 且插件大部分工作类都要调用它,所以针对其完成单元 测试。如图 6 所示单元测试代码片段所示,需要验证样 式生成逻辑是否能按如期设计一致。
步骤 1 显示声明一个 ReneeIdContext-
Helper 的 Spy 对象,并将与生成样式逻辑无关的 部分进行 Mock 化。
步骤 2 对 ReneeIdContextHelper 中 Mock 部分逻 辑做桩,给定固定结果。
步骤 3 遍历调用 ReneeIdContextHelper 的所有 样式生成函数逻辑,如系统内同层、跨层、异步任务、 跨系统。
步骤 4 预言 ReneeIdContextHelper 的式样生成 结果。
步骤 5 使用 maven 工具对单元测试案例进行测试, 得到结论显示预言结果为真。可证实样式生成逻辑正确。
3.2 集成测试
除了样式生成逻辑以外的 8 个核心程序类, 都属于 无法独立运行的代码。所以执行集成测试才能验证其逻 辑正确。如图 7 所示集成测试核心代码片段所示,通过 伪造请求访问案例,贯穿整个插件剩余逻辑测试。
前置条件 A 给定一个 SpringMVC 案例,包含同层、 跨层、跨系统、跨系统响应异步处理 4 个场景。
前置条件 B 给定一个配置类,负责将插件包里的核 心程序 Bean 化,注册到 Spring 环境里。
步骤 1 设定一个锁存器,为了后续测试异步场景 时,防止父线程退出后连带子线程退出。
步骤 2 模拟 Spring 环境将 SpringMVC 相关对象 Mock 化,并在 Mock 中增加插件包里的请求拦截器类、 前置条件 A 的请求控制类。
步骤 3 使用 Mock 对象伪造一个 Http Post 请求 X1. 测试同层、跨层访问场景。
步骤 4 根据请求 X1 的响应结果,模拟作为跨系统 请求 X2 的请求输入,即下游系统的 Span 上下文传递 到上游系统场景。
步骤 5 使用 Mock 对象伪造一个 Http Post 请求 X2.测试跨系统、异步处理响应场景。
步骤 6 检验 X2 响应结果是否与预言值一致。
步骤 7 使用 maven 工具对集成测试案例进行测试, 得到结论显示预言结果为真。可证实插件包整体处理 逻辑正确,如图 8 所示,每一个 Span 都是一条日志记 录,插件已经天然地把它们集成在一起。日志上下文的 信息不需要存储到 Span 上下文, Span 只需关注跟踪 上下游关系、与时间消耗。不同的跟踪操作, Span 将根据设计样式发生不同的变化。结合日志的异常函数调 用栈,可以快速从数以千万计的日志中检索出,调用栈 关联的请求上下文信息。
3.3 性能测试
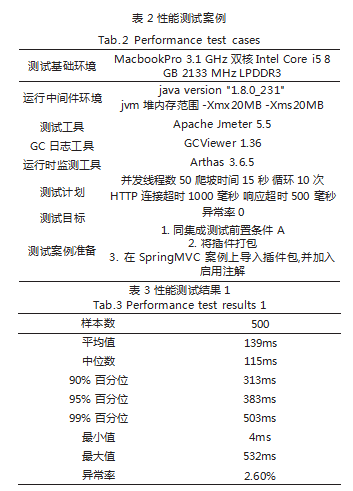
将插件包运行在生产环境上,必须经历性能测试。 测试环境、计划和目标如表 2 所示。
性能测试步骤分为如下几个步骤:
步骤 1:用 Java 命令并指定 PrintGCDetails 等参数, 以便在程序发生 GC 时查看 GC 日志;
步骤 2: 使用 Jmeter 参照测试计划配置, 向案例 发起一个 Post 类型的 Http 请求;
步骤 3: 观察 Jmeter 按测试计划执行完毕后的结果, 如表 3 所示, 500 个样本, 99% 的请求响应时间不超过 503ms,异常率为 2.6%,所以可得到有 5 个请求响应 时间在 503ms 以上,有 8 个请求大于 500ms 但不超过 503ms 之间,一共 13 个请求因为响应超时不合格,翻 查程序的调用栈日志可看见 SocketTimeoutException: Read timed out 异常信息。
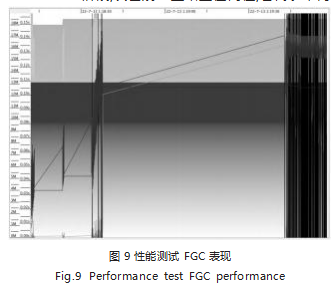
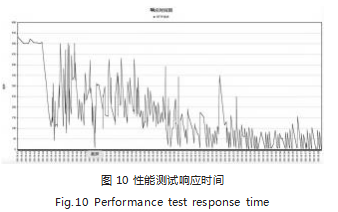
步骤 4: 进一步观察 Jmeter 的响应时间图 8.发现整个响应推移线都处于抖动状态,尖刺特别多,可理解为 应用程序内部资源 I/O 处理十分不稳定。使用 GCViewer 查看案例程序 GC 日志表现,如图 9 所示。如图 10 所示 可以确认响应第一次发生的时间是 09:19:43. 即图 9 的 时间轴第 6 格以及第 2 纵轴 ( 时间消耗轴 ),发现了 一堆密密麻麻的黑色线,代表 FGC。再观察第 1 纵轴 15M-17M 阶段,灰色线一直站立在高位,它代表堆内存占用情况, 已经使用超过 80%(20MB 用了 17MB), 基本可确认性能测试期间,案例程序运行环境内存不 足,发生了严重的 FGC。
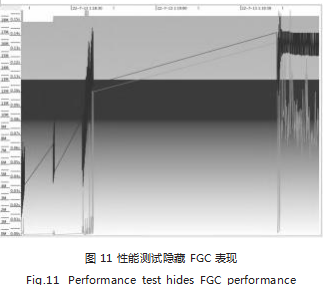
步骤 5: 将 FGC 隐藏得到如图 11 所示,可清晰地 观察代表当前时刻 GC 消耗时间的黑色线。并继续查看 GCViewer 里面 Pauses 选项卡, 它会计算出 GC 过程 中导致应用程序停止的时间总和是 9.23 秒,
其中 FGC 占了 95.3% 即 8.79 秒。整个性能测试过程是 15 秒, 中途停顿了 9.23 秒,整体停顿时间 =FGC 时间 +GC 时 间。可以得出结论,图 9 的尖刺是由 GC 导致的,结合 性能测试过程中产生大量的 FGC, 可判断原因是启动 应用程序时候堆内存分配太少导致的,与插件包和案例 程序本身逻辑无关。
步骤 6:根据步骤 5 的结论,调整堆内存和测试计 划,其他参数不变,如表 4 所示,为的是将插件包性能 发挥到最大,在异常率为 0% 的情况下,逼近最佳的吞 吐量。结论如表 5 所示,可见整体结果数据与未调整测 试方案前相差不大,甚至更好,同时未发现 GC 日志。 可以确认插件包逻辑 I/O 处理正常。
步骤 7:进一步观察计算资源消耗情况。通过 Arthas 工具得出插件包和案例程序运行时生成的 CPU 资源占 用火焰如图 12 所示, 平顶部分为 CPU 资源占用最多的 调用栈。发现是核心程序类 ReneeAsyncClient 中的 语句 Thread.sleep(0) 导致的。对应的场景是跨系统访 问,下游系统异步线程处理上游系统返回的响应结果产 生 CPU 占用高。原因是 ReneeAsyncClient 作为跨系统访问的异步客户端,内部逻辑使用了线程池负责异步 请求,而父线程直接将空结果返回。异步访问的时间与 父线程返回的时间无法确定顺序,一旦子线程先标记完 成并结束,而父线程返回的空结果未来得及注册回调函 数,那么回调函数就会由父线程劫持执行。Span 的异 步样式逻辑将会出错,为了避免发生,使用了 Thread. sleep(0),要求子线程让出 CPU 时间片占有权,保证 父线程先注册响应结果处理的回调函数。所以 CPU 在 性能测试并发场景场景下占用高是正常现象。
4 结语
基于 OpenTracing 规范,设计一种轻量级的可视 化跟踪样式,使用 Java Spring 框架开发了分布式系统日 志跟踪的插件包程序。该插件包可覆盖系统内同层、跨 层、异步处理、跨系统跟踪场景。并对插件进行单元、集 成和性能基准测试,确定生产环境下的高可用性。以支持 中小微企在低成本下,快速精准定位分布式系统的异常。
[1] Alex Boten,Charity Majors.Cloud-Native Observability with OpenTelemetry[M].Birmingham:Packt Publishing, Limited,2022:42-45.
[2] Austin Parker,Daniel Spoonhower,Jonathan Mace, et al .Distributed Tracing in Practice:Instrumenting, Analyzing,and Debugging Microservices[M].Sebastopol: O'Reilly Media,Incorporated,2020:69-73.
[3] 温小斌,张达,诸映晴 .轻量级分布式追踪系统的设计与实现 [J].计算机时代,2020(9):64-66.
[4] Gurpreet Sachdeva.Applied ELK Stack:Data Insights and Business Metrics With Collective Capability of ElasticSearch, Logstash and Kibana[M].Charleston,South Carolina:CreateSpace Independent Publishing Platform,2017:160.
[5] Charity Majors,Liz Fong-Jones,George Miranda . Observability Engineering:Achieving Production Excellence[M].Sebastopol:O'Reilly Media,Incorporated, 2021:29-35.
[6] Benjamin H Sigelman,Luiz A Barroso,Mike Burrows,et al.Dapper,a Large-Scale Distributed Systems Tracing Infrastructure[R].Santa Clara County,2010:3. [7] Yuri Shkuro .Mastering Distributed Tracing[M] . Sebastopol:O'Reilly Media,Incorporated,2019:81-88.
[8] 宁肖 .基于微服务架构的应用运行性能监控研究[J]. 电子技 术与软件工程,2021(15):166-167.
[9] Chris Richardson.Microservices Patterns:With Examples in Java[M]. Manning Publications,2019.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/57845.html