SCI论文(www.lunwensci.com)
摘 要:针对二维表生成知识图谱的节点冗余问题,单表知识不足和多源数据库表在没有关系约束的前提下难以形成表间 的映射问题,本文提出一种基于二维表数据的知识图谱融合构建方法。首先利用 TKGC 方法自行选出的核心属性与其他属性之 间构成的 < 属性值、属性名、属性值 > 三元组生成单表知识图谱,然后利用 SNF 融合方法或者 SRF 融合方法对不同类型的二 维表知识图谱进行融合,最后实现基于 Neo4j 的可视化存储。利用 4 个真实数据集进行实验,可视化结果证明图谱构建真实有 效,融合后整体关系节点比增加了 22.3%,关系数量增加了 10.5%,增强了图谱联合查询和知识挖掘能力。
关键词:二维表,知识图谱,构建,融合
Knowledge Graph Construction and Fusion Method Based on Database Tables
ZHANG Dawei, GUO Jingjing
(College of Computer and Information Technology, Liaoning Normal University, Dalian Liaoning 116000)
【Abstract】:Aiming at the node redundancy problem of generating knowledge graph of database table, the problem of insufficient knowledge of single table and the difficulty of generating mapping between tables in multi- source database tables without relational constraints, this paper proposes knowledge graph fusion construction method based on two-dimensional table data. Firstly, the triples between the core attributes and other attributes selected by the TKGC method are used to generate a single- table knowledge graph, and then SNF fusion method or SRF fusion method is used to fuse different types of two- dimensional table knowledge graphs, and finally the visual storage based on Neo4j is realized. Using four real data sets for experiments, the visualization results prove that the graph construction is real and effective, and the overall relationship node ratio increased by 22.3% and the number of relationships increase by 10.5% after fusion, which enhances thejoint query and knowledge mining capabilities of the graph.
【Key words】:two-dimensional table;knowledge graph;construction;fusion
0 引言
2012 年 Google 公 司 提 出 知 识 图 谱 (Knowledge Graph) 这一概念,发布了基于知识图谱的搜索引擎产 品。知识图谱以图的形式呈现,用以描述现实世界中的 实体、概念及二者的内在联系,被应用于金融风险控 制、个性化推荐、情报分析、智能医疗、反欺诈等 [1] 各 个领域。知识图谱数据来源广泛才能更好地满足不同场 景下的应用需求。知识图谱中的事实以三元组的形式表 示,事实数量决定了知识图谱的丰富程度 [2]。在上述背景下,知识图谱融合构建成为研究热点。
传统的二维表数据组织形式扁平、数据冗余量较 大,不适用于特定的知识检索。将表作为知识进行组 织,从语义层面上增加了表格内容之间的关系,提高了 查询的便利性 [3]。近年来关于知识图谱构建和融合的研 究得到了相关研究者的广泛关注。针对二维表的三元组 抽取,现有的组织方式通常设置 ID 为主节点,在客观 上造成了数据冗余。本文提出的知识图谱构建方法,利 用属性之间的主次关系形成主属性值节点到其他属性值节点间的单一关系,有效地去除了重复属性值的存在, 同时原表属性值之间的属性关系得到了很好的保留。
部分学者 [4] 提出的针对具有相似属性和属性值的 二维表融合方法,对融合候选表的要求较高,针对更广 泛的数据资源适配性较低。本文提出一种更具普适性的 二维表融合方法,该方法对候选数据要求较低,为知识 图谱的自动化构建提供了可行的途径,提高了知识完备 性,有利于更广泛的二维数据表的知识关联、检索和推 理,给知识图谱的融合构建提供了新的思路。
1 相关研究
1.1 二维表的知识图谱构建
二维表的知识图谱构建,需要在原数据表中抽取出 三元组信息,并存储到图数据库中。二维表的三元组抽 取通常采用序列标注的方法,即标注头尾实体以及它们 之间的关系。如蒋耀 [5] 等直接按照表格字段,将每个单元 格创建为“实体—属性—属性值”记录。李华昱等 [6] 设 计了数据流组合模型,对二维表单元格分配二维坐标, 利用已有概念标注单元格,设置约束从表格中抽取出实 体、关系及属性值组合成三元组。该模型针对计算机学 科知识图谱构建效果较好,但是对未知领域的概念难以 捕捉标注。李梦妮等 [7] 利用 Apache POI 插件定位行列 坐标,对二元组集合进行实体及属性的自动标注,利用 Bootstrapping 半监督学习算法从多值表格中提取实体 间关系,同时对非结构化表格文档随机抽样,进行部分 实体对及其关系的人工标注。上述方法都是以 ID 作为 中心节点与其他属性值节点形成三元组关系。由于 ID 值在通常情况下缺乏明确的语义信息,以 ID 值生成过 渡性中心节点,不但削弱了图谱的知识密度,也减弱了 节点间的直接关系链接。
知识图谱常见的存储工具有 Neo4j、Gephi、VOSviewer 等,其中 Neo4j 直接存储图数据,可提高图数据的计算 效率。根据 DB-ENGINES[8] 的调查,Neo4j 在图数据库 领域的热度长期稳居首位,具有嵌入良好、高性能和轻 量级等优势,有助于用户更好地理解和使用知识图谱。
1.2 多源数据知识图谱融合
知识融合也称为实体消歧、实体对齐、本体对齐等。 针对多源图谱的融合,李坚林 [9] 通过语义匹配和字符 串匹配来建立起两类数据间的联系,从而实现知识图谱 统一规范的表达方式。周炫余 [10] 提出一种基于层次过 滤思想的知识融合模型。首先按照实体对齐精度高低设 定一系列过滤模块,分别实现百科和文本内部的实体对 齐,再以教材知识为主体,对两类数据进行实体链接, 实现多源数据的融合。苏佳 [11] 融合了多源的 Java 代码知识图谱。首先构建 API 知识图谱,再往 API 实体上补 充来自源码的结构性知识,以及 SO 的问题描述,最后 将 API 功能性描述和 SO 上的问题性描述以及 API 概念 相连接。Wang 等 [12] 利用外部定义和上下文信息丰富本 体中的实体,并将这些附加信息用于本体对齐。Juanzi Li[13] 提出一种大规模实体匹配方法,其主要采用 TF- IDF 为向量中的每个分量分配权重并建立索引,实体相 似度通过余弦相似性进行判别。这种算法具有较快的计 算速度和较高的召回率,但其只将实体关系看作实体的 一类属性,并未真正实现本体对齐,准确率较低。
2 知识图谱融合构建方法
设数据集 D=, 其中 name 为属性名 称集合,data 为数据内容集合。name={a1.a2.… ,an}, data={{d11.d12.… ,d1n},… ,{dm1.dm2.… ,dmn}}。
二维数据表与其对应的知识图谱如表 1 和图 1 所 示。表 1 中 price 列包含的单词最多被选做主属性列。
2.2.1 共享节点融合方法
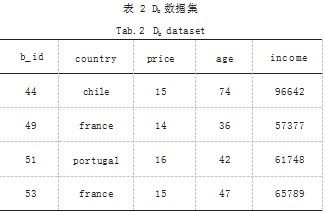
拥有相同属性名的非同源二维表数据如果属性值也 相同,大概率表明该属性值的语义也相同。如表 1 和表 2 所示。
由表 1 和表 2 可知,存在相同属性名 country 和 price。两个表的 country 列有相同的属性值 chile 和france,price 列有相同的属性值 14 和 15. 很显然这 些相同的属性值具有相同的语义。基于此给出共享节点 融合算法。
算法 1 共享节点融合 (SNF) 算法
输入 :数据集 Da 和 Db。
输出 :经共享节点融合后的知识图谱 G。
Step1. 令 D1=Da .data,D2=Db.data,A1=Da .name, A2=Db.name。
Step2. 对 D1 和 D2 进行分词、过滤和词频统计,生 成词频字典 WC1 和 WC2.
Step3. 找 A1 和A2 中相同属性名的位置集合 S={(x,y)| x 属于 A1 中的位置,y 属于 A2 中的位置 }。
Step4. 遍历 S 中的属性对, 寻找相同属性值, 并建 立共享点集合 SN。
Step5. 判断 WC1 和 WC2 中的词关键字是否也是 SN 集合中的关键字, 如果是直接引用 SN 中节点, 否则用 词关键字创建新节点。
Step6. 分别确定 Da 和 Db 中的主属性列。
Step7. 以每行记录主属性中的主关键词作为头结 点。
Step8. 遍历当前行其他列的属性值作为尾结点, 以尾结点的属性名作为关系名,生成头尾节点之间的 关系。
Step9. 两个数据集通过共享节点融合生成知识图 谱 G。
2.2.2 共享关系融合方法
对于没有相同属性名的任意两个二维表进行融合, 需要找到具有语义相似的属性值才行。这要求两个表中 需要包含具有实际语义价值的非数值型词汇。语义词汇 的生成或标注可以采用如下方法 :
(1)人工标记 :对缺少语义信息的表格增加语义 列,并将每行的语义标注写在该列内。
(2)自动化标记 :标注方案和语义列的设定根据数据集的特点决定。例如一组逻辑属性具有唯一的真值或 假值,可将唯一值对应的属性名标记为语义标签。同 理,可在一组可比较的数值属性中选择最大或最小值, 并将该值对应的属性名作为语义标签。
对于语义相似性的判断本文推荐如下方法 :
(1)等价相似 ES。属性值之间的语义相关性可用 等价相似度 ES(Equivalent Similarity) 进行判断,ES 判断成功需满足如公式 (1) 所示 :
Step3. 判断 D1 和 D2 是否有语义关键词,若无,进 行语义标注。
Step4. 用 WC1 和 WC2 中的词关键字创建节点。
Step5. 分别确定 Da 和 Db 中的主属性列。
Step6. 以每行记录主属性中的主关键词作为头结点。
Step7. 遍历当前行的其他列值作为尾结点,以尾结 点的属性名作为关系名,生成头尾节点之间的关系。
Step8. 对 Da 和 Db 中具有语义属性的关键词进行 相似性判断。
Step9. 在符合相似性要求的关键词节点间建立共享 关系。
Step10. 两个数据集通过共享关系生成融合知识图 谱 G。
3 实验
3.1 数据集
实验数据集部分描述如表 3 所示。
3.2 红酒知识图谱的构建与融合
采用 TKGC 方法对表 3 数据集分别进行单表知识 图谱构建和多表知识图谱构建,实验表明构建速度与数 据规模呈正相关性。选择 TKGC 自动构建方法的结果 不受数据规模的影响,始终以一定规则进行构建。随着 数据规模增加,程序的运行时间虽有所延长,但构建 时间也远低于常见的以 ID 为主节点的构建方法,证明 TKGC 方法明显提高了构建效率。
如图 2 所示,代表着表 3 中 4 个二维数据表融合后 的部分知识图谱,不同颜色的圆点代表不同的对象。其中 橘色为 wine_evaluation, 红色为 wine_customer, 蓝色 为 marketing_campaign, 绿色为 wines_spanish, 箭 头连线表示关系的起点和终点,关系的类型显示在连线 上。4 种节点间通过 SRF 方法进行了有效融合,例如, dryred 为干红类型的葡萄酒酒评,与购买了 red 类型 酒的用户产生了 fusion 连接,从常识角度来看,两者 之间融合关系真实有效。
3.3 构建融合效果分析
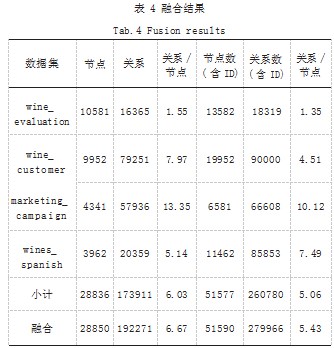
如表 4 所示可以看出,基于 TKGC 方法构建的知 识图谱拥有更好的连通性, 4 个数据集关系节点比分别 增加 14.7%、76.5%、31.9、 -13%, 整体增加 22.8%。 基于 TKGC 方法生成的知识图谱的节点数量远低于以 ID 为主属性的节点数量,同时保留了原表属性关系不 变。在多表融合生成的知识图谱中,通过少量新增的语 义标签可以大范围的增加节点间的关系数量,达到了多 表融合的效果。4 个数据集采用 SRF 方法融合后共生成了 28850 个节点、192271 个关系, 相比 4 个独立的图 谱而言,增加了 14 个节点,关系个数增加 10.6%。总 体而言,融合后的知识图谱确实使单表图谱的知识得到 了有效的拓展,加强了不同数据集之间的联系,使知识 检索和挖掘更加方便有效。
4 结语
使用数据库存储二维表数据仍然是目前主要的数据 存储方式,通过知识图谱对二维表数据进行知识挖掘, 发现其具有巨大的发展潜力。本文提出的二维表数据 知识图谱的构建和融合方法,有效解决了节点冗余和非 同源数据融合问题,为大规模的数据库表知识图谱化提 供了坚实的基础。实验表明恰当地运用共享节点融合方 法和共享关系融合方法可以对任意多源数据进行有效融 合。融合后的知识图谱在保持原图谱内容不变的前提下 有效地实现了相互拓展,为二维数据表的知识挖掘提供 了无限可能。尽管本文方法对拥有相同属性和相近语义 值的非同源二维表进行直接融合较为方便,但对更广泛 的非同源二维表而言还需要进行恰当的语义标注,而语 义标注本身就是一个值得研究的重要问题。由于数据的 损坏或其他原因导致二维表数据项的缺失,也会使知识 图谱的完整性和丰富性受到直接影响,因此通过图神经 网络进行链接预测,融合邻域知识,对缺失内容进行补 全也是一个重要研究方向。
参考文献
[1] 田莉霞.知识图谱研究综述[J].软件,2020.41(4):67-71.
[2] 李涓子,侯磊.知识图谱研究综述[J].山西大学学报(自然科学 版),2017.40(03):454-459.
[3] ROUSIDIS D,KOUKARAS P,TJORTJIS C.Examination of NoSQL Transition and Data Mining Capabilities[C]// Research Conference on Metadata and Semantics Research. Springer,Cham,2020:110-115.
[4] 赵雪芹,李天娥,曾刚.基于Neo4j的万里茶道数字资源知识 图谱构建研究[J].情报资料工作,2022.43(5):89-97.
[5] 蒋耀,胡啸峰.基于多源数据的城市犯罪风险知识图谱研究 [J].中国人民公安大学学报(自然科学版),2022.28(1):87-94.
[6] 李华昱,刘烨宸,李家瑞,等.基于异质数据源的计算机学科知 识图谱构建[J].计算机系统应用,2022.31(6):10-18.
[7] 李梦妮.基于多源数据的高校学术知识图谱构建及其应用研 究[D].杭州:浙江工业大学,2020.
[8] 李娇.基于知识图谱的科研综述生成研究[D].北京:中国农业 科学院,2021.
[9] 李坚林,张晨晨,赵昊然,等.基于多源数据融合的电网设备技术监督知识图谱构建[J].电工电气,2021(9):60-63+68.
[10] 周炫余,唐祯,唐丽蓉,等.基于多源异构数据融合的初中数 学知识图谱构建[J].武汉大学学报(理学版),2021.67(2):118- 126.
[11] 苏佳,苏小红,王甜甜.基于多源数据融合的Java代码知识图 谱构建方法研究[J].智能计算机与应用,2020.10(5):9-13.
[12] WANG L L,BHAGAVATULA C,NEUMANN M,et al. Ontology Alignment in the Biomedical Domain Using Entity Definitions and Context[C]//Annual Meeting of the Association for Computational Linguistics;Workshop on Biomedical Natural Language Processing,2018:47-55.
[13] LI J Z,WANG Z C,ZHUANG X,et al.Large Scale Instance Matching Via Multiple Indexes and Candidate Selectio[J]. Knowledge-Based Systems,2013.50:112-120.
[14] 田江伟,李俊锋,柳青.结合属性结构的图卷积实体对齐算 法[J].计算机应用研究,2021.38(7):1979-1982+1992.
[15] RAHMAN Z,HUSSAIN A,SHAH H,et al.Urdu News Clustering Using K-Mean Algorithm On The Basis Of Jaccard Coefficient And Dice Coefficient Similarity[J]. ADCAIJ:Advances in Distributed Computing and Artificial Intelligence Journal,2021.10(4):381-399.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/55540.html