SCI论文(www.lunwensci.com):
摘 要:为了获取图像序列中的时序信息,构建了卷积神经网络和时序注意力结合的网络模型。卷积神经网络用于捕捉空 间特性,时序注意力机制用于捕捉序列间各样本之间的局部关联,通过对局部关联性加权求和得到序列时序特征。最后利用训 练好的网络模型进行了测试,并对测试结果进行了展示。
关键词:行为识别;注意力机制;稀疏采样
Action Recognition Based on Temporal Attention Fusion
CAO Xinying1, YANG Wenjie2, ZHAO Jianguang1
(1.Hebei University of Architecture, Zhangjiakou Hebei 075000;2.China Agricultural University, Beijing 100083)
【Abstract】: In order to obtain the temporal information in the image sequence, a network model combining convolutional neural network and temporal attention is constructed. The convolutional neural network is used to capture the spatial characteristics, and the temporal attention mechanism is used to capture the local correlation between the samples in the sequence. The temporal characteristics of the sequence are obtained by weighted summation of the local correlation. Finally, the trained network model is used to test and the test results are shown.
【Key words】: action recognition;attention mechanism;sparse sampling
0 引言
行为识别任务关注如何准确判断视频中人体正在进 行的动作, 是计算机视觉领域的一个典型研究方向 [1]。 行为识别通常包括两步:特征提取和决策分类。在深度 学习发展之前,行为识别主要依赖手工选定特征,对特 定视频进行分类。典型的手工选定特征包括:梯度直方 图特征 (HOG)[2]、光流直方图 (HOF)[3]、运动边界直方 图 (MBH)、时空兴趣点 (STIP) 以及骨架特征等。
随着视频多样性的增加,视频行为特征的表达逐 渐由 2D 向 3D 演化, 传统的手工特征提取的复杂度升 高,深度学习的提出为行为识别的深入研究提供了新的 方案。卷积神经网络在特征提取方面的能力远远超出手工特征提取,基于深度学习的行为识别以神经网络为基 础,主要以卷积神经网络、循环神经网络为主要基准网 络。目前基于深度学习的主流行为算法主要包括双流卷积网络 [4-5]、长短期记忆网络、3D 卷积网络 [6-7] 等。
尽管行为识别的研究已经取得了一定的进展,但是 在时序特征表征方面仍然止步不前,导致行为识别无法 得到实际的应用。针对此问题,本文引入时序注意力机 制,将卷积神经网络与时序注意力模块结合,捕获时序 方向的数据关联性,能够在一定程度上增强长距离时序 特征。
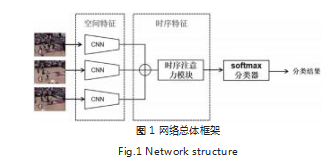
1 网络框架
本文将 CNN 网络与时序注意力机制进行结合,卷 积神经网络用于帧图像序列的空间特征提取,获取帧级 图像特征,然后利用时序注意力机制对多帧图像之间 的上下文信息进行序列建模 [8]。由于视频序列中存在大量冗余帧,为了消除冗余帧信息,本文采用稀疏采样策 略,在一定的时间间隔内获取一张图像,组成序列数 据,作为网络模型的输入。网络总体框架如图 1 所示。
1.1 稀疏采样
如图 2 所示,一个视频通过一定的采样率分为了 N 个图像帧,但是相邻的帧图像之间的行为变化不明显, 会造成网络训练负担,因此采用稀疏采样策略在一定的 时间间隔内取一帧,消除冗余的帧图像,减轻了网络在 训练过程中的数据量。
具体的流程: 给定一段视频 V,将视频转化为 N 帧,按照等间隔划分为 K 段 {S1,S2,...SK},其中每一段 中图像帧的数量为 N/K,在每一段中随机选择连续 P 帧 图像组成该视频的帧图像序列,故视频 V 一共取得了 K×P 帧图像,该 K×P 帧图像将作为网络模型的输入。
1.2 基于 CNN 的空间特征提取网络
卷积神经网络是深度学习的中心,在图像识别、计 算机语言处理、图像检索、语义分割等多个领域得到 了广泛的应用。卷积神经网络具有自我学习的强大功 能,最早应用于手写数字识别中。目前,深度学习模 型大部分是卷积神经网络的变形体,主要包括 LeNet、 AlexNet、VGG、ResNet 和 Inception 等。 本文采用ResNet50 作为空间特征提取网络。ResNet50 由多种 残差块组成,残差结构如图 3 所示。输入的特征会沿着 两个分支进入残差网络结构,最后进行融合。残差网络 结构克服了网络过深导致梯度消失的问题,纵向加深了 网络层次结构。
ResNet50 网络结构如表 1 所示。
1.3 基于注意力机制的时序建模
注意力机制模仿人的大脑,当载入的信息映入眼帘 的时候,人类大脑会自动识别重要信息,而忽略无关信 息。注意力机制的本质就是在大量的数据特征中筛选出 关键信息。在时序建模中,注意力发生在序列数据的内 部,在学习每个元素的重要程度的同时建立各个元素之 间的联系,这个过程是动态进行的。本文网络模型输入 的数据为图像序列,因此引入注意力模块 [9-10] 加强各帧 之间的联系,提取时间特征信息,有助于提高模型的识别精度。
本文网络模型的输入为经过稀疏采样后的多帧图 像,将每帧图像对应的特征向量在通道维度上进行拼 接形成立方体,然后利用平均池化与最大池化结合的 注意力模型聚合各个图像之间的时序信息。注意力 模块的输入 F, 表示各个特征向量的拼接矩阵,其中 F ∈ B×C×H×W,Favg 和 Fmax 分别表示平均池化操 作和最大池化操作, F 分别经过平均池化和最大池化得到两个注意力描述图,然后将两个注意力描述图分别送 入一个两层的神经网络结构中,这两层神经网络结构的 参数是共享的,其中第一层的神经元的个数为 C/r, 第二 层的神经元个数为 C,两层中的激活函数为 Relu 激活 函数,再将得到的两个特征相加并融入 Sigmoid 函数 中得到权重系数 Mc, 最后将权重稀疏与原 F 相乘即可 得到新特征。具体的公式如下:
Mc (F) = σ(MLP(AvgPool(F)) +MLP(MaxPool(F)))
= σ(W1 (W0 (Favg (F)) + W1 (W0 (Fmax (F))))
2 实验
2.1 实验数据
本文实验采用 UCF101 数据集,这是具有 101 类的 行为识别数据集。数据集主要分为五种类型:人与人交 互行为、人与物交互行为、仅肢体行为、体育运动行为、演奏乐器。该数据集中动作多样性,在背景杂乱、光照 等方面存在差异性,并且存在相机运动,是具有挑战的 行为识别数据集。
2.2 实验流程
实验流程如图 4 所示, 首先按照一定的采样率将视 频转换为图像,采用稀疏采样策略将数据集进行划分;构建网络模型,并将训练数据输入到网络模型中进行学 习,并在训练过程中保存最优的网络权重;利用最优的 网络结构对测试集进行测试,得到分类结果。
2.3 实验结果分析
本实验使用 Windows 10 系统单 GPU 环境下搭建的 Pytorch 深 度 学 习 框 架。UCF101 数 据 集 使 用 split01 分割策略,其中训练数据大约占 70%,剩下的为测试数 据。训练数据采用稀疏采样策略,其中 K 值设置为 3,即将每个视频分为 3 段,每段等间隔取 1 帧。在图像处 理部分将图像剪裁为 224×224 大小,以适应 ResNet50 网络模型的输入。ResNet50 采用在 ImageNet 数据集上 预训练的权重模型。在时序注意力网络后面添加了一个 全连接层用于输出本数据集类别的维度,经过 Softmax 激活函数得到每段的得分,然后将每段的得分取平均作 为整个视频的分类得分。
本文随机选择了几段视频对网络模型进行测试,测 试结果如图 5 所示。可以看出,网络模型取得了不错的 识别效果。
3 结论
本文采用卷积神经网络与时序注意力机制结合的网 络结构,通过卷积神经网络作为特征提取器,将卷积网 络获取到的特征向量输入到时序注意力网络中,通过注 意力机制建立序列间的长距离依赖关系,获得更加丰富 的时间维度信息。实验表明,时序注意力网络能够较好 的表达时序特征,能够实现较好的识别效果。
参考文献
[1] 高陈强,陈旭.基于深度学习的行为检测方法综述[J].重庆邮 电大学学报(自然科学版),2020,32(6):991-1002.
[2] Laptev I,Marszalek M,Schmid C,et al.Learning realistic human actions from movies[C]//2008 IEEE Conference on Computer Vision and Pattern Recognition.IEEE,2008:1-8.
[3] Wang H,Kläser A,Schmid C,et al.Action recognition by dense trajectories[C].IEEE Conference on Computer Vision and Pattern Recognition.IEEE Computer Society, 2011:3169-3176.
[4] Simonyan K,Zisserman A.Two-stream convolutional networks for action recognition[C]//Proceedings of the Neural Information Processing Systems(NIPS).2015.
[5] Liu C,Ying J,Yang H,et al.Im prov ed human action recognition approach based on two-stream convolutional neural network model[J].The Visual Computer,2021,37(6):1327-1341.
[6] Ji S,Xu W,Yang M,et al.3D convolutional neural networks for human action recognition[J].IEEEtransactions on pattern analysis and machine intelligence, 2012,35(1):221-231.
[7] Kanagaraj K,Priya G G L.A new 3D convolutional neural network(3D-CNN) framework for multimedia event detection[J].Signal,Image and Video Processing, 2021,15(4):779-787.
[8] 张天雨,许飞,江朝晖.基于时空自注意力转换网络的群组行 为识别[J].智能计算机与应用,2021,11(5):77-81+87.
[9] 高明柯,赵卓,逄涛,等.基于注意力机制和特征融合的手势识 别方法[J].计算机应用与软件,2020,37(6):205-209.
[10] Guan C,Wang X,Zhu W.Autoattend:Automated attention representation search[C]//International Conference on Machine Learning.PMLR,2021:3864-3874.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/35879.html