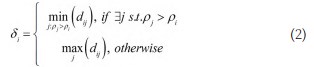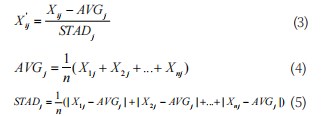SCI论文(www.lunwensci.com):
摘要:网络安全己经成为现如今社会发展的重要保障,而入侵检测系统在网络安全的体系结构中占着举足轻重的地位。传统的基于聚类分析的网络入侵检测方法需要预先设定聚类数目且无法处理噪声数据,但入侵检测系统获取的网络行为记录具有很强的随机性,其聚类数目和聚类形状难以事先确定,故需要更鲁棒的聚类方法进行入侵检测。本文提出一种基于密度峰值聚类的网络入侵检测方法,该方法利用了密度峰值聚类算法的优点,无需迭代、参数鲁棒、自动获取聚类数目,并且可以很好地处理噪声数据和入侵检测系统所获取的网络行为记录,挖掘更有效的入侵信息。最后通过对KDD CUP 1999数据集的实验验证,验证本文方法的有效性和精确性。
关键词:聚类;密度峰值聚类;网络安全;入侵检测
Network Intrusion Detection Based on Density Peaks Clustering
DU Shuying1,2
(1.School of Information Management,Xuzhou Vocational College of Bioengineering,Xuzhou Jiangsu 221000;
2.School of Computer Science and Technology,China University of Mining and Technology,Xuzhou Jiangsu 221116)
【Abstract】:Network security has become an important guarantee for the development of the society,and intrusion detection system plays an important role in the network security architecture.The traditional network intrusion detection method based on clustering needs to set the number of clusters in advance and cannot process noises,but the network behavior records obtained by the intrusion detection system have strong randomness,and the number of clusters and the shape of the clusters are difficult known in advance.Thus,more robust clustering methods are needed for intrusion detection.In this paper,a network intrusion detection method based on density peaks clustering is proposed.This method takes advantage of the advantages of density peaks clustering algorithm.It does not need iteration,has robust parameters,automatically obtains the number of clusters,and can well deal with noise data and network behavior records obtained by intrusion detection system,mining more effective intrusion information.Finally,the effectiveness and accuracy of the proposed method are verified by experiments on KDD CUP 1999 data set.
【Key words】:clustering;density peaks clustering;network security;intrusion detection
0引言
随着计算机技术与网络技术的不断发展,计算机系统和互联网络越来越智能化和多元化,但同时也面临着越来越严重的威胁、攻击和破坏[1]。网络的广泛应用,使得网络与人们的生活、工作密切相关,网络已经成为维系社会正常运作的支柱[2]。网络中的信息事关企业甚至国家的发展,因此,网络和网络信息的安全已经事关个人、企业、甚至国家的安危[3]。在过去的几年中,网络安全事件频频发生,并且让人们触目惊心。2019年,国家互联网应急中心(CNCERT)共处理各类网络安全事件近10.8万起,其中安全漏洞事件位居第一,达3.4万余起。据国家信息安全漏洞库(CNNVD)统计,截至2019年12月31日,仅事件型漏洞总量就达14.1万条,较2018年同比大幅增长227%,将信息系统和网络暴露在严重的安全风险之中。大环境下的网络安全形式不容乐观,组织信息系统和个人数据的安全问题亟待解决,刻不容缓[4]。
入侵检测技术是目前网络安全研究的一个关键技术[5]。但是目前大部分入侵检测技术都需要事先提供一个行为模型,将当下所有已知的违反安全策略的行为封装成集合[6]。但在现实中,行为模型的获取需要消耗极大的人力物力,需要安全工作人员手工对大量的网络流量数据、系统活动日志等原始数据进行详细的分析与甄别,而且很难保证数据的真实性与随机性[7]。基于聚类分析的入侵检测方法可以直接对网络流量、系统行为等进行分析与检测,无需安全工作人员提供原始数据,这种入侵检测方法已经成为当下的主要发展方向[8]。Bhuyan等[9]第一次提出了用聚类分析的方法进行网络入侵检测的研究方向,简要描述和比较了大量的网络异常检测方法和系统。常刚等[10]提出基于聚类算法的入侵检测系统设计,基于改进的K-means进行入侵检测,提高入侵检测的准确率。马文亭[11]提出基于Apriori-KNN算法的入侵检测方法,降低入侵检测误报率。邢瑞康等[12]提出改进的聚类算法在入侵检测系统中的应用,在K-中心点聚类算法中引入数据的密度信息,并将改进的算法用于入侵检测,克服传统K-中心点聚类算法依赖初始中心的问题。但由于入侵检测系统获取的网络行为记录具有很强的随机性,其聚类数目和聚类形状事先难以确定,故无法直接使用传统的聚类算法。
2014年,Rodriguez和Laio在《Science》期刊上发表了一篇名为《Clustering by fast search andfind of density peaks》的文章[13]。作者在这篇文章中提出全新的密度聚类算法,即密度峰值聚类算法(Density Peaks Clustering,DPC)。该算法采用可视化的方法来帮助查找准确的聚类中心[14]。相对于传统的基于密度的聚类方法,密度峰值聚类算法仅有一个输入参数,无需事先定义聚类数目,可以获取任意形状的簇,可以处理噪声数据,并且实现更为简单[15]。密度峰值聚类算法凭借上述优势,为诸多实际问题提供了全新的解决思路,该算法在入侵检测中有着巨大的应用前景。
本文结合网络安全知识,主要讨论入侵检测技术以及密度峰值聚类算法,并对基于密度峰值聚类算法的网络入侵检测做了一些有益的探索与实践。本文的主要框架结构安排如下:第2章,入侵检测系统以及密度峰值聚类算法的简单概述。第3章,基于密度峰值的网络入侵检测系统描述。第4章,通过对KDD CUP 1999数据集的验证,证明密度峰值聚类算法在网络入侵检测中的有效性。第5章,对已完成的工作进行总结并对相关技术的发展做出展望。
1相关工作
1.1网络入侵检测
网络安全问题是指网络环境中发生的破坏信息可用性、机密性、完整性、不可否认性和可控性的事件,如主机感染病毒、黑客入侵、拒绝服务攻击和网络欺骗等[16]。所有破坏网络可用性、机密性和完整性的行为都是入侵行为。目前,黑客主要使用恶意代码、非法访问和拒绝服务攻击等手段[17]。恶意代码一是可以破坏主机系统,例如删除文件;二是它可以为黑客提供非法访问主机信息资源的渠道,例如设置后门和改变黑客访问权限;三是可以泄漏主机系统重要信息资源,如检索含有特定关键词的文件,将其压缩打包,发送给特定接受终端[18]。非法访问指未经授权的用户使用操作系统或应用程序漏洞来访问信息资源;或者是非注册用户使用暴力破解的方法破解管理员密码以实现对主机系统的访问[19]。拒绝服务攻击一是指使用操作系统或应用程序漏洞使主机系统崩溃,例如发送长度超过64KB的IP数据包;二是利用协议的固有缺陷来耗尽主机系统资源,使主机系统无法提供正常的服务,如SYN泛洪攻击等[20]。
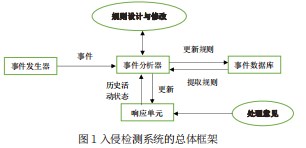
入侵检测系统的功能是在网络传输的信息流中,或者输入输出主机系统的信息流中检测出用于实施入侵的异常信息,并对异常信息予以反制。实现这一功能的步骤包括捕获信息、检测信息、确定入侵行为并予以反制等。入侵检测系统通用框架结构如图1所示,由事件发生器、事件分析器、响应单元和事件数据库组成[21]。
网络入侵检测系统主要用于检测流经网络某个关键链路的信息流[22]。网络入侵检测系统具有以下功能:(1)保护网络资源。主机入侵检测系统只能保护主机免遭攻击,需要网络入侵检测系统保护节点和链路免遭攻击,如一些拒绝服务攻击就是通过阻塞链路来达到使正常用户无法正常访问网络资源的目的;(2)大规模保护主机。主机入侵检测系统只能保护单台主机免遭攻击,如果一个系统中有成千上万台主机,对每一台主机都安装主机入侵检测系统是不现实的,一是成本太高,二是使所有主机入侵检测系统的安全策略一致也很困难。而单个网络入侵检测系统可以保护一大批主机免遭攻击;(3)和主机入侵检测系统相辅相成。主机入侵检测系统由于能够监管发生在主机上的所有操作,而且可以通过配置列出非法或不合理的操作,从而通过判别最终操作的合理性来确定主机是否遭受攻击,这是主机入侵检测系统能够检测出未知攻击的主要原因。但有些攻击是主机入侵检测系统无法检测的,如黑客进行的主机扫描,主机入侵检测系统无法根据单个被响应或被拒绝的建立TCP连接的请求报文确定黑客正在进行主机或端口扫描,但网络入侵检测系统根据规定时间内由同一台主机发出的超量请求建立TCP连接的请求报文确定网络正在遭受黑客的主机扫描观察。
1.2密度峰值聚类算法
在人们认识、理解世界时,“类”的概念具有非常重要的意义,类是具有相似公共属性的一组对象。聚类分析就是将输入的数据对象集合按照数据对象间的相似度并依据相应的规则将其划分至不同的簇内,旨在使得同一个簇内的数据对象具有较大的相似度,不同的簇内的数据对象差异较大[23]。这种方式实际上是一种无标签分类,因此,聚类属于无监督学习方法。聚类分析属于数据挖掘领域,也是人类一种基本的认知活动。聚类算法已在数据挖掘、语音识别、机器学习及生物信息处理等领域广泛应用[24]。聚类主要分为:基于划分的聚类算法、基于层次的聚类算法、基于密度的聚类算法、基于图论的聚类算法、基于网格的聚类算法等[25]。
其中密度聚类算法的优势在于相较于其他种类的聚类算法,密度聚类算法能够在包括噪声数据的数据空间中找到任意形状和大小的簇,并且无需预先定义簇数[26]。DPC是2014年被提出的新的基于密度的聚类算法,其核心思想是根据聚类中心的特点快速识别聚类中心,然后再完成剩余点的分配[27]。聚类中心具有两个特征:
(1)局部密度较高,即聚类中心被低密度点环绕;(2)聚类中心与其他高密度点间的距离相对较大。基于聚类中心的两个特征,假设一个数据集,n是数据集的规模,dij表示两个点之间的欧式距离,DPC定义两个重要属性:
定义1:局部密度,即表示距离xi不超过dc的所有点的集合[28]。
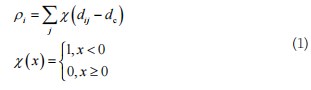
其中参数d称为截止距离,是DPC的唯一输入参数。
定义2:相对距离,即xi与最近高密度点之间的距离[29]。
为了找到数据对象集合的聚类中心点,DPC根据局部密度和相对距离构造决策图,通过可视化方法选择两个属性值都大的点作为聚类中心[30]。决策图可以被视为基于二维坐标系的数据表示,横坐标是局部密度ρ,纵坐标是相对距离6。确立了聚类中心之后,再对非聚类中心数据点进行归类。对非聚类中心的数据点作归类时,是按照ρ值从大到小的顺序进行遍历的,将数据点归类到离其最近的高密度点一类[31]。同时,定义一个边界阈值,即一个类的边界阈值表示为属于该类但距离其他类小于dc的点的集合中密度最大的点,设置为ρb,而该类中密度不大于边界阈值的样本即为噪声点[32]。例如,如图2(a)、图2(b)所示分别代表28个点的数据集分布和根据这些点绘制的决策图。
从图2(b)中可以看出,第1号和第10号数据点的ρ值和6值较之于其他数据点都非常大,在数据集合中非常显眼,这两个点恰好就是聚类中心。第26号、第27号、第28号数据点是孤立点(噪声点),它们ρ值很大但6值很小。在一定程度上DPC算法是一种启发式算法,DPC的主要过程总结为算法1。
算法1.DPC算法
输入:数据集X;
输出:类别Y。
步骤:
Step1.计算相似度矩阵D;
Step2.根据公式(1)、公式(2)计算局部密度ρi和相对距离6i;
Step3.根据ρi和6i绘制二维决策图,并标识具有高ρi和6i的点为聚类中心;
Step4.分配非中心点到最近高密度点类;Step5.筛选局部密度不超过ρb的离群点;Step6.输出数据划分结果。
DPC算法无需迭代,无需先验,且只有一个输入参数,不仅可以处理非球形数据集,而且可以很好的筛选离群点[33]。
2基于密度峰值的网络入侵检测
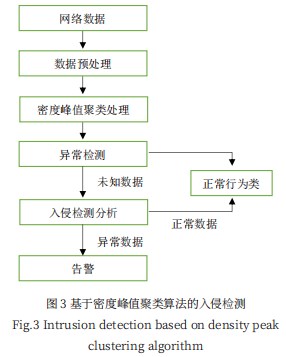
由于传统的基于聚类分析的网络入侵检测技术需要预先设置聚类数目且无法处理噪声数据,但入侵检测系统获取的网络行为记录具有很强的随机性,其聚类数目和聚类形状事先难以确定[34]。本文为解决信息安全中的网络入侵问题提出基于密度峰值聚类的网络入侵检测,该检测系统分为训练部分和异常行为部分,模型如图3所示:
网络入侵检测的工作过程包括三步[35]:
(1)捕获信息。网络入侵检测系统是一种对经过网络传输的信息流进行异常检测的设备,因此首先必须具备捕获信息的功能,通过事件发生器提供网络数据。
(2)检测异常信息。通过密度峰值聚类算法根据捕获的网络数据,例如入侵特征描述、用户历史行为模型等,对获取的信息进行检测,并根据事件数据库判断数据是否属于正常数据。事件数据库存储用作确定数据是否合法的基础信息,包括攻击行为描述、攻击特征描述、用户历史行为、统计阀值、检验规则等。
通过此步骤可以根据分析结果在事件数据库中更新和添加诸如入侵特征描述和用户历史行为模型之类的信息,通过设置规则或者修改规则可以人工干预某些数据的分析结果。
(3)响应单元,即对异常检测信息结果作出反应,包括丢弃IP分组、释放TCP连接、报警、登记和分析、终止应用进程、拒绝操作请求、改变文件属性等。通过异常检测后,向响应单元发出更新消息时,可以依照之前的响应单元对类似事件的分析结果做出应答,还可以通过向响应单元设置处理意见,人工干预对指定异常检测结果做出的反应。
基于密度峰值聚类的网络入侵检测利用了DPC算法的优点,无需迭代、参数鲁棒、自动获取聚类数目,并且可以很好地处理噪声数据和入侵检测系统所获取的网络行为记录。
3实验分析
3.1数据集预处理
本文的网络入侵检测部分采用KDD CUP 1999数据集来进行算法的评估和验证。数据集中所包括的攻击类型有以下四种[36]:(1)对本地超级用户的非授权访问(Unauthorized Access to Local Super User,U2R),U2R是指入侵者通过缓冲区溢出漏洞来获取本地超级用户访问权限的攻击手段。(2)拒绝服务攻击(Denial of Service,DOS),DOS是指入侵者通过发送大量的请求信息占用大量服务器资源,使得服务器无法响应合法用户请求的攻击手段。(3)非授权远程主机访问(UnauthorizedAccess From a Remote Machine,R2L),R2L是指入侵者通过远程获取网络服务程序缓冲溢出漏洞,来获取本地用户的访问权限的攻击手段。(4)扫描攻击(Surveillance and Other Probing,Probing),Probing是入侵者通过扫描网络各种端口中可能存在的系统漏洞,对服务器或本地用户进行攻击。具体分类标识如表1所示。
KDD CUP 1999数据集中的每条连接记录有41个特征向量,第1位到第9位是TCP连接的基本特征(如连续时间,协议类型,传送的字节数等);第10位到第22位是TCP连接的内容特征(如登录失败的次数等);第23位到第31位是基于时间的网络流量的统计特征,统计在过去2s内连接记录的特征。第32位到第41位是基于主机的网络流量统计特征,统计之前发生的100个TCP连接有何特征。第42位是连接记录的标识(Label),用于表明此条连接记录是正常还是异常,如果出现异常,系统受到的攻击是哪一种。原始的KDD CUP 1999数据集含有500多万条连接记录的特征数据,信息量过于庞大。因此本文采用的是kddcup.data 10 percent子数据集来进行训练和测试。由于其中Normal和DOS两类样本数量较大,占10 percent总样本的98.93%,而U2R、R2L和Probe三类样本数据量较小(其中U2R故障只有52个样本,通常在训练U2R的单分类器时,将选取全部的U2R样本进行训练),如表2所示,将Normal样本和DOS、U2R、R2L和Probe这4类故障样本进行编号。
聚类算法中要使用计算距离的方法对数据进行聚类,各特征属性的度量方法不一样,一般而言,所用的度量单位越小,变量可能的值域就越大,这样对聚类结果的影响也就越大,即在计算数据间距离时对聚类的影响越大,甚至会出现“大数”吃“小数”的现象。因此为了避免对度量单位选择的依赖,消除由于属性度量的差异对聚类产生的影响,需要对属性值进行标准化。数值标准化之后再进行数值归一化,数值归一化将标准化后的每个数值归一化到[0,1]区间。
本文采用 Python3.7 对 KDDCUP 1999 数据集进行预处理,分为以下三个步骤 :(1)采用 one-hot 方法将字符型特征转换为数值型特征(即符号型特征数值化);(2)数值标准化。设Xij' 为数值标准化后Xij 的值 :
其中 AVGj 为平均值, STADj 为平均绝对偏差, 比标准差对于孤立点具有更好的鲁棒性。上述计算时要做如 下判断, 如果 AVGj = 0, 则 Xij = 0 ;如果 STADj = 0 , 则 Xij = 0 ;(3)数值归一化。将标准化后的每个数值 归一化到 [0,1] 区间,设 Xij 为 Xij 归一化后的值 :
3.2设计实验
本文所采用的仿真开发工具是Matlab 2016a与Pycharm 2019.1.2×64,仿真平台配置为Intel(R)Core(TM)i7-6500/2.50GHz/8.00GB/Win10/x64。
将DPC算法应用到对KDD CUP 1999数据集的数据分析与异常数据检测中。本实验选取KDD CUP 1999数据集中数据记录的12个关键特征向量,其中9个为连续型数据特征,另外3个为离散型数据特征。实验从KDD CUP 1999数据集的训练集中随机抽取10000条数据记录作为实验的训练集,从测试集中同样随机抽取10000条数据记录随机划分为两个各含有5000条数据记录的测试集U1和U2。现实情况中正常的数据记录应该占数据集的绝大部分,而异常数据记录应该占数据集的绝小部分,所以算法的训练集与测试集中的数据分布应该也要符合上述特征,各个数据集合中的数据记录分布如表3所示。
将聚类分析算法应用在网络入侵检测技术上采用检测率(T)和误检率(F)两个衡量指标。假设TP表示检测到的入侵记录数,TN表示数据集中入侵记录数,FP被误报为入侵的正常记录数,FN是数据集中正常记录数,则计算公式为:
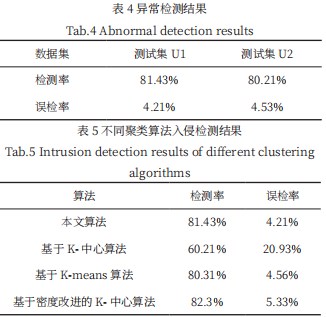
实验结果如表4所示,并将本文算法与传统的基于聚类的网络入侵检测方法对U1进行测试对比,结果如表5所示,本文提出的基于密度峰值聚类网络入侵检测的方法的误检率低于传统聚类方法,虽然其检测率不是很高,但是基本令人满意,并且比K-means,K-中心都要好,这是由于这两个算法都对初始值的设置要求比较高,并且需要事先定义聚类的数目。而DPC算法无需迭代,无需先验知识,并且可以处理噪声数据,因此基于密度峰值聚类的网络入侵检测可以取得令人满意的结果。
4总结与展望
随着计算机技术飞速发展,网络安全的防护日渐重要。入侵检测技术是网络安全的重要保障,聚类分析在入侵检测中得到了广泛应用并极大地推动了入侵检测技术的发展。针对传统基于聚类的入侵检测需要先验知识且无法处理噪声等问题,本文主要尝试将DPC算法用于网络入侵检测,提高网络入侵检测的稳定性和鲁棒性,该算法无需迭代,仅有一个参数,并且无需预先设定聚类中心以及聚类数目,可以针对入侵检测的数据集的未知性而做出调整,更适用于入侵检测技术的应用。
但是目前大部分网络入侵检测系统是独立设备,因此,除非每一段链路都配置网络入侵检测系统,否则网络入侵检测系统是无法检测经过网络传输的所有信息流的。另外,如果捕获的信息是加密后的信息,网络入侵检测系统的检测机制便不再有效。因此,对于黑客通过HTTPS攻击Web服务器的情况,网络入侵检测系统是无能为力的,因此更有效的网络入侵检测方法有待进一步探究。
参考文献
[1]解男男.机器学习方法在入侵检测中的应用研究[D].长春:吉林大学,2015.
[2]李响.基于经验模态分解的局域网络入侵检测算法[J].西南师范大学学报(自然科学版),2016,41(8):132-137.
[3]徐伟,冷静.基于人工蜂群算法和XGBoost的网络入侵检测方法研究[J].计算机应用与软件,2021,38(3):314-318+333.
[4]邹臣嵩,杨宇.基于密度和最优聚类数的入侵检测方法[J].西南师范大学学报(自然科学版),2018,43(12):97-105.
[5]文华,王斐玉.利用SSO速最佳路径森林聚类的网络入侵检测[J].西南师范大学学报(自然科学版),2017,42(5):34-40.
[6]王婷,王娜,崔运鹏,等.基于半监督学习的无线网络攻击行为检测优化方法[J].计算机研究与发展,2020,57(4):791-802.
[7]AHMEDM,MAHMOOD A N,HU J K.A Survey of Network Anomaly Detection Techniques[J].Journal of Network and Computer Applications,2016,60:19-31.
[8]王磊.改进粗糙集属性约简结合K-means聚类的网络入侵检测方法[J].计算机应用,2020,40(7):1996-2002.
[9]BHUYAN M H,BHATTACHARYYA D K,KALITA J K.Network Anomaly Detection:Methods,Systems and Tools[J].IEEE Communications Surveys&Tutorials,2014,16(1):303-336.
[10]罗文华,许彩滇.利用改进DBSCAN聚类实现多步式网络入侵类别检测[J].小型微型计算机系统,2020,41(8):1725-1731.
[11]马文亭.基于Apriori-KNN算法的入侵检测误报过滤研究[D].哈尔滨:哈尔滨理工大学,2019.
[12]邢瑞康,李成海.改进的聚类算法在入侵检测系统中的应用[J].火力与指挥控制,2019,44(2):126-130.
[13]RODRIGUEZ A,LAIO A.Clustering by Fast Search and Find of Density Peaks[J].Science,2014,344(6191):1492-1496.
[14]XU J,WANG G Y,DENG W H.DenPEHC:Density Peak Based Efficient Hierarchical Clustering[J].Information Sciences,2016,373:200-218.
[15]CHEN J Y,HE H H.A Fast Density-based Data Stream Clustering Algorithm with Cluster Centers Self-determined for Mixed Data[J].Information Sciences,2016,345:271-293.
[16]HAGHIGHAT M H,LI J.Intrusion Detection System Using Voting-based Neural Network[J].Tsinghua Science and Technology,2021,26(4):484-495.
[17]崔文科.基于聚类算法的入侵检测系统的设计与实现[D].北京:电子科技大学,2015.
[18]赵石真.基于SVM的K-means聚类算法在WSN入侵检测中的应用[D].成都:西华大学,2016.
[19]黄思慧,陈万忠,李晶.基于PCA和ELM的网络入侵检测技术[J].吉林大学学报(信息科学版),2017,35(5):576-583.
[20]LIUJ P,ZHANG W X,TANG Z H,et al.Adaptive Intrusion Detection Via GA-GOGMM-based Pattern Learning with Fuzzy Rough Set-based Attribute Selection[J].Expert Systems with Applications,2020,139:1-17.
[21]金波,林家骏,王行愚.入侵检测技术评述[J].华东理工大学学报,2000(2):191-197.
[22]卿斯汉,蒋建春,马恒太,等.入侵检测技术研究综述[J].通信学报,2004,25(7):19-29.
[23]DING S F,DU M J,SUN T F,et al.An Entropy-based Density Peaks Clustering Algorithm for Mixed Type Data Employing Fuzzy Neighborhood[J].Knowledge-Based Systems,2017,133:294-313.
[24]MEHMOOD R,ZHANG G Z,BIE R F,et al.Clustering by Fast Search and Find of Density Peaks Via Heat Diffusion[J].Neurocomputing,2016,208:210-217.
[25]谢娟英,高红超,谢维信.K近邻优化的密度峰值快速搜索聚类算法[J].中国科学:信息科学,2016,46(2):258-280.
[26]LIU Y H,MA Z M,YU F.Adaptive Density Peak Clustering Based on K-nearest Neighbors with Aggregating Strategy[J].Knowledge-Based Systems,2017,133:208-220.
[27]CHEN J Y,LIN X,ZHENG H B,et al.A Novel Cluster Center Fast Determination Clustering Algorithm[J].Applied Soft Computing,2017,57:539-555.
[28]ABDUL M M,HUANG J Z,WEI C,et al.I-nice:A new Approach for Identifying the Number of Clusters and Initial Cluster Centres[J].Information Sciences,2018,466:129-151.
[29]DU M J,DING S F,JIA H J.Study on Density Peaks Clustering Based on K-nearest Neighbors and Principal Component Analysis[J].Knowledge-Based Systems,2016,99:135-145.
[30]XIE J Y,GAO H C,XIE W X,et al.Robust Clustering by Detecting Density Peaks and Assigning Points Based on Fuzzy Weighted K-nearest Neighbors[J].Information Sciences,2016,354:19-40.
[31]LIANG Z,CHEN P.Delta-distance Based Clustering with a Divide-and-conquer Strategy:3DC Clustering[J].Pattern Recognition Letters,2016,73:52-59.
[32]ZHANG Y F,CHEN S M,YU G.Efficient Distributed Density Peaks for Clustering Large Data Sets in MapReduce[J].IEEE Trans on Knowledge and Data Engineering,2016,28(12):3218-3230.
[33]ANWAR T,LIU C F,VU H L,et al.Partitioning Road Networks Using Density Peak graphs:Efficiency vs Accuracy[J].Information Systems,2017,64:22-40.
[34]AL-YASEEN W L,OTHMAN Z A,NAZRI M Z A.Multi-level Hybrid Support Vector Machine and Extreme Learning Machine Based on Modified K-means for Intrusion Detection System[J].Expert Systems with Applications,2017,67:296-303.
[35]Francisco J Aparicio-Navarro,Konstantinos G Kyriakopoulos,GONG Yu,et al.Using Pattern-of-life as Contextual Information for Anomaly-based Intrusion Detection Systems[J].IEEE Access,2017,5:22177-22193.[36]吴建胜,张文鹏,马垣.数据集的数据分析研究[J].计算机应用与软件,2014,31(11):321-325.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/41790.html