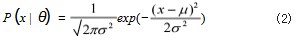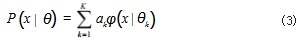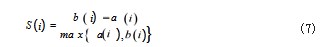SCI论文(www.lunwensci.com)
摘 要 :随着金融业的迅猛发展和金融交易监管的不断升级,可疑交易监测工作面临巨大考验。可疑交易是指通常情况下 不认为符合正常逻辑思维的交易,本文首先介绍可疑交易的特点,而后提出多种不同聚类算法,分析不同聚类算法结合可疑交 易识别工作下的优劣势。本文的核心是基于高斯混合模型下的可疑交易识别模型,针对可疑交易的交易结构与交易特点,来对 可疑交易进行判别,并用 Python 实现对数据的可视化分析。
关键词:聚类算法,可疑交易识别,高斯混合
A Suspicious Transaction Recognition Method Based on Clustering Algorithm
ZHANG Yubo
(Nanjing Audit University, Nanjing Jiangsu 211815)
【Abstract】: With the rapid development of the financial industry and the continuous upgrading of financial transaction supervision, suspicious transaction monitoring is facing a great test. Suspicious transactions refer to transactions that are not considered to conform to normal logical thinking under normal circumstances, this paper first introduces the characteristics of suspicious transactions, then a variety of different clustering algorithms are proposed, analyze the advantages and disadvantages of different clustering algorithms combined with suspicious transaction identification . The core of this paper is the suspicious transaction recognition model based on Gaussian mixture model, according to the transaction structure and characteristics of suspicious transactions, to identify suspicious transactions, and use Python to realize the visual analysis of data.
【Key words】: clustering algorithm;suspicious transaction identification;Gaussian mixture
1 绪论
1.1 课题背景及意义
金融是现代经济的核心,是实体经济的血脉。近几 年,随着电子支付交易数量快速增长,基层交易机构需 要从海量交易数据中找到可疑交易,人工筛查交易流水 的工作量巨大。为降低人工工作量,目前通常结合计算 机使用的是结构化查询语言,利用数据库增加部分筛选条 件,利用一些限制以及连接,嵌套查询可疑交易,这样 的工作虽然提高了一些工作效率,可以完成可疑交易的 识别,但是存在着高度的系统依赖,使得识别监测变得 易于规避,并没有较高的准确性。因此,面对海量的交 易流水,如何高效的对交易进行分析成为可疑交易识别 的关键,准确而高效的聚类可以使工作事半功倍。
无监督学习算法可以对可疑交易问题得到良好地解决。在可疑交易识别中,基于机器学习的模型种类多种 多样,网格聚类、孤立点、离群点的数据挖掘以及基于 不同角度的聚类算法,都被证明在可疑交易识别中可以 得到良好的识别效果。聚类算法是典型的无监督学习,它 可以克服缺乏足够的先验知识而难以进行人工标注的弊 端,在无类别信息下也可以很好地寻找特征进行类标注。
1.2 可疑交易特点分析
可疑交易主要指代的是交易的金额、频率、流向、 用途、性质等存在异常情况的交易,人民币可疑交易主 要包含短期内资金分散转入,集中转出或集中转入,分 散转出的交易 ;相同收付款人之间短期内频繁的发生资 金往来的交易 ;周期性发生大量资金收付与企业业务性 质不符合的交易 ;频繁开户、销户且销户前发生大额交 易 ;存取现金的金额数、频率以及用途与其现金收付明显不符的 ;资金收付频率与企业经营规模明显不符的 ; 企业日常收付与企业经营特点明显不符的等交易。总 之,可疑交易是通常情况下不符合常规逻辑思维的交易。
1.3 可疑交易识别模型的提出
根据中心极限定理和大数定律,自然界中的大多数 变量服从高斯分布,高斯分布也是广泛存在我们的生活 中。无论是最常见的人类的身高、体重、寿命、血压、 财富等,还是气温、降雨量、产品的质量,甚至是抓起 一把砂砾随意扬在桌子上砂砾的分布都会是大部分集中 落在一起, 少量分散在四周。总之, 在经济、生物、气 象、天文等各个领域都遍布着高斯分布的规律。
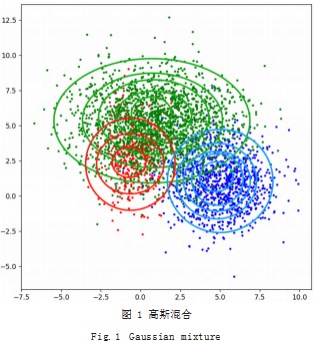
在庞大的交易记录中,同样会掺杂着形形色色,大相 径庭的交易。通过使用原始数据中不同角度的特征属性, 如从货币种类角度分类会有人民币交易、美元交易等, 从 交易的频率角度分类,会有每天几笔交易或每几天一笔 交易以及每小时甚至每分钟都存在交易。从交易金额角度 分类,可以分为大金额交易与小金额交易。而根据广泛存 在的高斯分布,我们不难分析判断出来,交易记录交易频 度的高低会符合高斯分布,交易的时间角度中, 是在白天 交易还是在夜间交易会符合高斯分布,交易金额角度中 金额的大小也会符合高斯分布。这样高斯分布会为寻找 可疑交易提供帮助,而我们只需要将多种符合高斯分布 的交易特点分别提取出来计算,再融合到一起形成高斯 混合模型。需要重点关注的即为分布在边缘的数据,因 分布在高斯混合模型图像边缘的即为可疑交易。
2 相关工作
2.1 数据预处理
预处理是在对数据进行分析前的必要工作。金融交 易流水数据往往是海量的,且交易数据格式不会完全相 同。同时,交易记录会存在少量错误与缺失,这些“噪 声”都会影响到数据的分析处理与聚类效果。因此,对 重要字段,如交易金额、交易时间、开户销户时间等重 要字段属性要进行合理预处理,取出对聚类效果无影响 的字段属性,对关键特征进行提取,避免对聚类算法的 效果产生不利影响。
2.2 选取聚类算法
聚类算法种类多样,不同的聚类算法对不同数据集 有着不同的聚类效果,基于划分、基于层次、基于密度 等聚类算法都在可疑交易识别中得以应用。基于划分的 聚类算法如 K-means 算法随机选择 k 个对象,并且每 个对象代表了一个簇的中心,然后对剩余点计算其到簇 中心距离并重新计算簇的平均值更新簇中心,如此不断 迭代直至函数收敛 [1]。基于层次的聚类算法如 BIRCH算法、CURE 算法,其思想主要分为合并的层次聚类 和分裂的层次聚类,每一次通过合并最相似的聚类来 形成上一层次中的聚类,当全部数据点达到某个终止 条件而结束。基于密度的聚类算法如 DBSCAN 解决了 K-means 无法解决的不规则形状的聚类,同时也对噪 声数据的处理较好,当临近区域的密度超过某个阈值就 继续聚类,最后在一个圈里的就是一个类。
2.3 优缺点及适用性分析
基于划分的聚类特点是计算量大,很适合发现数据 库中的球状簇,对大型数据库简单高效,时间复杂度和 空间复杂度都不高,但对于预先选取的 k 个点敏感,在 海量复杂变化的交易中,准确的设定 k 值是一大难点。 基于层次的聚类算法特点是算法处理数据集的速度快, 与数据集中的数据量关系不大,而取决于将数据集分为 多少个单元,但该类算法缺点明显,不太适合处理大数 据集,对于交易数据这样庞大的数据集,易出现与贪心 算法一样的缺点,一步错步步错。基于密度的聚类算法 克服了上述一些只能发现“类圆形”的聚类算法的缺 点,且对噪声不敏感,但在交易记录中,不同交易记录 差别大相径庭,相同的判定标准可能会破坏聚类的自然 结构,稀疏的聚类会被划分为多个类且距离较近的类会 被合并为一个类。
2.4 评估聚类效果的指标
将样本数据进行聚类后,需要通过指标评判数据的 聚类效果,常见的聚类评价指标有聚类纯度(Purity)、 兰德系数(RI)、调整兰德系数(ARI)等,纯度是一 种简单直观的聚类评价指标,其思想是用聚类正确的样 本数除以总的样本数,也被称为聚类的准确率。由于无 法准确确定对于聚类后结果不同簇对应的真实类别, 因 此每种情况都取最大值,纯度定义公式如式(1)所示 :
其中 N 表示总的样本数,Ω 表示簇,C 表示正确的 类别,最终取值范围为 [0.1],越大表示聚类效果越好。 兰德系数与纯度计算方法类似, 其定义 a 同类样本在同 一个簇, b 非同类样本在同一个簇, c 非同类样本在两 个簇与 d 同类样本在两个簇的情况四个变量,计算公式 为(a + d) /(a + b + c + d),同样系数取值范围在 [0.1] 且越大越好。调整兰德系数是对兰德系数的改进,去掉 随机标签对兰德系数评估结果的影响。
2.5 高斯混合聚类
2.5.1 单高斯模型
当一维样本数据服从高斯分布的时候,高斯分布遵从如式(2)所示的概率密度函数,其中 μ 为数据均值(期望),σ 为数据标准差。
通过 Python 中的 Numpy 扩展库和 Matplotlib 下 的子库 Pyplot 绘制生成一个 [-10.10] 区间内均匀的 20 个点的 Scatter 散点图,其服从高斯分布。可以直观的 得出该高斯分布的参数。
2.5.2 高斯混合模型
在上述单高斯分布的基础上再继续加入 [15.25] 区 间内均匀的 20 个点,并生成单一高斯曲线,从绘制出 的高斯曲线可以发现,均值 μ 取在了 mean (x) = 10 处, 但在此处的数据却极其稀疏,并不符合高斯分布的数据 特点,因此尝试使用两个高斯曲线分别描述,在每组数 据下分别绘制高斯曲线,得到两组高斯分布的曲线。
显然这样分别绘制的高斯曲线更加契合样本数据, 还原了数据的真实性。为了更加直观的表达多个簇下的 高斯分布曲线,用随机的三组二维数据来观测,高斯曲 线如图 1 所示。
将多个高斯分布融合在一个模型中就需要高斯混合 模型。显而易见,交易数据作为样本数据是多维多簇 的,因此用到高斯混合模型,即将交易流水看做由 K 个单高斯模型而合成的模型, K 个子模型是混合模型的隐 变量,其概率分布如式(3)所示 :
Xj 表示第j 个观测数据, j=1.2. …, N ;K 是混合
3 基于高斯混合聚类的可疑交易识别模型
3.1 模型概述
整个可疑交易流程可以被细化为几步 :第一步 :原 始数据预处理,模型首先需要将数据库中的交易数据读 取进来,交易流水信息通常包含一些高斯混合模型不需 要的字段,如银行卡号、持卡人姓名、开户行、持卡人 手机号、住址等相关信息,因为这类字段并不能满足本 文所预想的高斯分布,所以不做保留。而交易频度、交 易金额等重要关键信息需重点关注剥离开来,其次筛查 是否有缺失字段,尽量补全。第二步 :将预处理后的原 始数据读取进模型,作为模型的输入,模型会根据输入 的数据进行计算每个高斯分布的方差,根据预先设定的 不同高斯分布的权重大小来求得最大期望。通过不断更 新均值与方差迭代求解最大似然值 [3]。第三步 :聚合信 息提取,经过不断迭代后,最后一定会得到一个收敛的结果,而后读取模型的输出结果。第四步 :可疑交易识 别,根据输出结果,聚类后的离群点与小团体被认定为 可疑交易 [4]。第五步 :实验结果分析,将识别出的可疑 交易输出存档,由于本文采用的是无监督的聚类算法, 因此需评判高斯混合聚类算法在样本数据上的聚类效果 是否有效合理,检查被识别出的可疑交易是否有说服性。
3.2 可疑交易识别模拟实验
由于缺乏真实银行交易数据,本文使用模拟交易流 水数据进行可视化并用 EM 算法计算最大似然值, 经过 多次迭代,最终结果逐渐收敛,并向预期发展。得到结 果如图 2 所示。
3.3 模型效果评价指标
为了评估聚类效果的好坏,需要选取合适的评估指 标,轮廓系数即为一种评价聚类效果好坏的指标,它结合 了内聚度和分离度两种因素。它的公式如式(7) 所示 :
其中 a (i)代表样本点 i 与同一个簇中其他点之 间距离的平均数, b (i)代表样本点 i 与下一个距离最 近的簇中的所有点距离的平均值。轮廓系数的值域为 [-1.1],在值域内轮廓系数越大证明聚类效果越好。
3.4 结果分析
使用高斯混合模型聚类的初衷是根据广泛存在的高斯分布来聚类,聚类后的离群点与小团体可以视为可疑 交易,根据模拟数据观测,只提取交易金额和交易时间 两个特征, α 权重值平均分配来判断并将结果分为三个 簇,分别是存在嫌疑交易、大概率存在嫌疑交易与基本 正常交易,经过 EM 算法的迭代,虽然第一次计算的极 大似然值为 -19.484 与最终结果相差甚远,但经过大约 五次迭代数据逐渐收敛并最终趋于稳定。通过 Sklearn 中 的 metrics.silhouette_score 方法 求取不 同取值 k 下的轮廓系数均在 0.67 以上,证明聚类效果良好。
4 结语
本文首先对可疑交易介绍, 引入背景,分析可疑交 易的特点,通过该背景引入金融监管工作中的可疑交易 识别,通过无监督学习的聚类算法,进行数据预处理, 特征提取,选取不同聚类算法解决可疑交易识别问题。 利用高斯分布解决可疑交易问题符合统计学,高斯混合 聚类学习速度快,通过模拟数据对交易金额、交易频度 等敏感属性聚类且聚类效果良好,但最终效果仍需大量 数据多次模拟试验并不断改进。该算法仍有部分局限 性,要提前准确确定对实验结果具有深刻影响的分量, 即对聚类效果影响明显的属性,最好分为训练集与测试 集进行计算,用信息理论标准确定采用多少分量,未来 仍有改进空间。
参考文献
[1] 朱琳.银行交易大数据洗钱挖掘模型及应用研究[D].大连:大 连理工大学,2020.
[2] 王卫东,徐金慧,张志峰,等.基于密度峰值聚类的高斯混合模 型算法[J].计算机科学,2021.48(10):191-196.
[3] 何庆,易娜,汪新勇,等.基于高斯混合模型的最大期望聚类算 法研究[J].微型电脑应用,2018.34(05):50-52+75.
[4] 钟弘杰,巴继东.基于离群检测模型的反洗钱系统设计[J].电 子设计工程,2017.25(23):52-54+58.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/53299.html