SCI论文(www.lunwensci.com)
摘 要 :多麦克风融合降噪技术旨在降低来自多种麦克风(声学麦克风、光学麦克风、骨传导麦克风)的语音噪声,提 高信噪比,从而适应不同环境。针对传统多麦克风融合降噪算法在提取不同通道特征时效果不理想的问题,提出了一种基于 Transformer 的多麦克风融合降噪算法。该算法有 3 个主要步骤,首先采用多头注意力机制使每个通道能够学习到不同的权 重,更好地学习通道间的空间特征 ;其次将获得的通道特征以及原始特征输入到 Transformer 模型中,生成时域滤波器 ;最 后通过一维卷积操作获得每个通道增强后的语音数据。实验结果表明,提出的算法能够达到更好的降噪效果。
关键词 :Transformer,多麦克风融合降噪,注意力机制,特征融合
Transformer-based Multi-microphone Fusion Noise Reduction
HUA Rong1. ZHANG Heng2. LIU Yuanlong1
(1.College of Computer Science and Engineering, Shandong University of Science and Technology, Qingdao
Shandong 266590;2.Xixing (Qingdao) Technology Service Co., Ltd., Qingdao Shandong 266000)
【Abstract】:Transformer-Based Multi-Microphone Fusion Noise Reduction Technique aims to reduce speech noise from various microphones (acoustic, optical, bone-conduction) and improve the signal-to-noise ratio to adapt to different environments. To address the issue of suboptimal feature extraction from different channels in traditional multi-microphone fusion noise reduction algorithms, a Transformer-based approach is proposed. This algorithm consists of three main steps: Firstly, employing multi-head attention mechanism to enable each channel to learn different weights for better spatial feature learning between channels; Secondly, feeding the obtained channel features and original features into a Transformer model to generate time-domain filters; Finally, obtaining enhanced speech data for each channel through one-dimensional convolution operation. Experimental results demonstrate that the proposed algorithm achieves superior noise reduction performance.
【Key words】:Transformer;multi-microphone fusion noise reduction;attention mechanism;feature fusion
引言
语音在人类日常沟通过程中具有十分重要的意义, 它 是语言信息载体,是人类情感交流最主要的方式。然而, 在日常生活中,语音信号经常受到混响和背景噪声的破 坏,导致语音质量明显下降。因此,旨在提高语音识 别系统能力的语音降噪技术获得了越来越多的关注 [1-3]。 相较于单通道语音降噪算法,多麦克风可以提供空间信 息特征,这对于提升语音降噪算法的性能至关重要。然 而,传统的多麦克风融合降噪算法在提取不同通道的特 征时效果不理想。近年来,随着深度学习技术的不断发展,很多研究学者开始尝试突破传统方法的局限性,探 索深度学习方法与传统语音增强方法相结合的新方法以 实现噪声环境下的语音降噪。相较于传统方法,基于深 度学习方法的语音降噪算法采用数据驱动的形式,依靠 神经网络建立带噪语音和纯净语音之间的内在联系。目 前,深度学习方法与多麦克风语音降噪技术相结合逐步 成为当前语音领域研究的热点方向 [4.5]。
受其启发,本文提出一种基于 Transformer[6] 的多 麦克风融合降噪算法。具体而言,利用仿真工具生成多 通道语音数据,其中包含多通道纯净语音数据和多通道带噪语音数据。第一步,将多通道带噪语音数据进行预 处理,在预处理阶段,需要对语音数据进行分帧和前后 加窗操作,此时语音数据被分为两个部分, 一部分是前 后加窗后的语音数据,另一部分是未前后加窗的语音数 据 ;第二步,将加窗后的语音数据输入通道特征提取模 块,进行通道特征提取,同时将未加窗的语音数据进行 一维卷积操作 ;第三步,将第二步获得的通道特征和一 维卷积处理之后语音数据联合,输入到 Transformer 模型中,生成时域滤波器 ;第四步,将第三步生成的时 域滤波器和未加窗的语音数据做卷积操作,获得每个通 道增强后的语音数据 ;第五步,将第四步获得的每个通 道增强后的语音进行求和取平均操作,增强模型的鲁 棒性以及语音的平稳性。本文使用 STOI、PESQ、SI- SNR、SDR 四种评价指标评估模型的有效性。实验结果 表明,该模型能够达到更好的降噪效果。
1相关工作
1.1 波束形成算法
延迟求和波束形成算法首先对每一个麦克风接收到 的语音信号进行延迟补偿,用于抵消由于麦克风与声源 之间存在一定距离所导致的时间延迟,当所有麦克风的 语音信号在时间上同步之后,再进行加权求和。该算法 实现原理简单,工程上容易实现,但是效果依赖于麦 克风的数量,当麦克风数量较多时,可以达到比较理想 的效果。与固定自适应波束形成算法不同,自适应波束 形成算法根据输入数据的信号特征,通过统计估测的方 式,自适应地改变滤波器的系数。最小方差无失真响应 (MVDR) 波束形成器是一种广泛应用的最优波束形成设 计。MVDR 波束形成器是一种数据自适应波束形成解 决方案,用于在传感器阵列中抑制干扰并增强感兴趣的 信号,其目标是最小化波束形成器输出的方差,如果噪 声和基本期望信号不相关,通常情况下,捕获信号的方 差是期望信号和噪声的方差之和。MVDR 是理论上普 遍采用的波束形成典型算法,在复杂环境下,协方差矩 阵计算的精确度较低会导致算法性能急剧下降。
1.2 Transformer
Transformer 模型是为了替代传统的基于 RNN 的 seq2seq 模型而提出的。该模型克服了传统模型对长序列 建模的缺点,提高了模型的并行计算能力,在机器翻译 任务中表现出色,击败了传统模型。与早期的 seq2seq 模型一样,原始的 Transformer 模型使用 Encoder- Decoder 框架。编码器由逐层迭代输入的编码层组成, 而解码器由对编码器的输出执行相同操作的解码层组 成。每个编码器层的功能是生成信息的编码,其中包含 有关输入的哪些部分彼此相关的信息,并将其编码作为输入传递给下一个编码器层。解码器层使用编码器的输 出生成目标序列,为了更好地利用编码器的输出,每个 解码器层使用注意力机制合并所有编码器的上下文信 息,并在生成目标序列时进行处理。这种机制使得解码 器能够更好地理解输入序列的上下文信息,提高了模型 的性能。对于每个输入,注意力机制会权衡彼此输入的 相关性并将其提取出来以产生输出。每个解码器层都有 一个额外的注意力机制,在解码器层从编码中提取信息 之前,从前一个解码器的输出中提取信息。
2算法设计
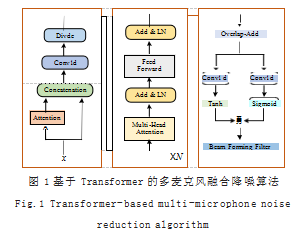
语音信号具有时序的特征,当前帧的信号会受到前 面几帧信号的影响。考虑到循环神经网络 (RNN) 及其变 种 LSTM 难以处理长期依赖关系,采用 Transformer 处 理语音信号。模型结构如图 1 所示。
如图 1 所示,该模型主要包含 3 个部分 :(1)特征 提取 ;(2)语音信号建模 ;(3)语音降噪。
(1)特征提取 :对于多麦克风模型, 每个通道所提 供的特征对于模型的贡献不应该是等价的,同样,单个 通道的每一帧数据所提供的特征,对于模型的贡献也不 应该是等价的。基于此,本文提出了一种基于注意力机 制的多通道特征提取方法,其主要分为三个步骤。
1)对输入数据在帧级别方向进行压缩,如式(1) 所示 :
(2)语音信号建模 :为了更好地建模视觉特征与语义 特征, 本文采用Transformer 作为基准模型。Transformer 是一个编码器 - 解码器框架。其中,编码器由 6 个相同的 层构成,每层有两个子层。第一个子层是多头注意力机制 层,第二个子层是前馈全连接网络。两个子层分别采用 跳跃连接,且每个子层后跟一层 Layer Normalization。 即每个子层的输出为LayerNorm(x + Sublayer(x)) ,其 中Subayer(x) 是子层实现的函数本身,如式(6)所示。 R ′ = Transformer(R) (6)
多头注意力机制层包含 H 个不同的头, 每个头对 应一个独立 的 Scaled Dot-Product Attention, 然后 用线性变换将不同的注意结果联合起来,计算方式如式 (7)、式(8)、式(9)所示 :
(3)语音降噪 :Sigmoid 的部分用于控制信息的输 出,值越接近于 1.表示允许该部分信息的通过,越接 近 0.表示不允许信息通过。Tanh 用于将数据压缩到 一个很小的范围,且不会损失小于 0 的部分,这有助于 加速模型收敛。将两个激活函数的输出结果进行乘积计 算,能够起到信息门控的作用。信息门控可以类比人类 大脑,在面对外界大量的信息时有针对地对信息进行吸 收和遗忘。信息门控对上层进行信息流的控制,有助于 筛选对模型效果影响较大的特征值。
3 实验
3.1 实验仿真环境
在某些场景中因说话人位置不同会导致语音的能量 分布不均,影响模型的增强性能。本文麦克风具体配置 如下 :一个麦克风阵列放置在客厅, 一个麦克风阵列放 置在卧室, 一个麦克风阵列放置在厨房, 一个麦克风阵列放置在餐厅。房间模型模型大小设置长为 15m,宽 为 8m,高为 3m。
3.2 实验结果分析
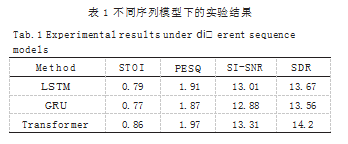
为了验证本节所提模型和通道提取算法的有效性,采 用 STOI、PESQ、SI-SNR 和 SDR 四种评价指标, 对实验 进行更加全面的分析。LSTM[7]、GRU[8] 和 Transformer 在信噪比为 0db 下的实验结果如表 1 所示。由表 1 可 以看出, Transformer 模型在所有评价指标上都获得 了最好的性能,由此证明了所提出方法的有效性。
参考文献
[1] LIM J,OPPENHEIM A.All-pole Modeling of Degraded Speech[J].IEEE Transactions on Acoustics,Speech and Signal Processing,1978.26(3):197-210.
[2] QI H,FENG B,BAO C.Multiplicative Update of Auto-Regressive Gains for Codebook-Based Speech Enhancement[J].IEEE/ACM Transactions on Audio,Speech, and Language Processing,2016.25(3):457-468.
[3] SREENIVAS T,KIRNAPUREP.Codebook Constrained Wiener Filtering for Speech Enhancement.IEEE Transactions on Acoustics,Speech,and Signal Processing,1996.4(5):383-389. [4] HAN W,ZHANG X,MIN G,et al.A Novel Single Channel Speech Enhancement Based on Joint Deep Neural Network and Wiener Filter[C]//2015 IEEE International Conference on Progress in Informatics and Computing (PIC).IEEE,2015:163-167.
[5] WU J,HUA Y,YANG S,et al.Speech Enhancement Using Generative Adversarial Network by Distilling Knowledge from Statistical Method[J].Applied Sciences, 2019.9(16):3396.
[6] VASWANI A,SHAZEER N,PARMAR N,et al.Attention is all You Need[J].Advances in neural information processing systems,2017.30.
[7] HOCHREITER S,SCHMIDHUBER J.Long Short-term Memory[J].Neural computation,1997.9(8):1735-1780.
[8] CHUNG J,GULCEHRE C,CHO K H,et al.Empirical Evaluation of Gated Recurrent Neural Networks on Sequence modeling[J].arXiv preprint arXiv:1412.3555.2014.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/76921.html