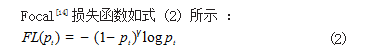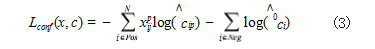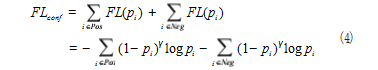SCI论文(www.lunwensci.com)
摘 要:针对目标检测中检测精度低且小目标检测较难的问题,提出了一种基于注意力机制与特征融合的改进 SSD 目标 检测算法。在标准 SSD 目标检测模型基础上,使用深层特征提取网络 ResNet50 作为主干网络,在特征提取网络中引入通道- 空间注意力机制增强特征图语义信息,计算特征图中像素点之间的影响。最后,将低层特征与高层语义信息进行 Concat 特征 融合,充分利用不同特征图之间的关联信息。此外,使用 GIOU 代替传统 IOU 来计算框间的交并比,同时考虑正负样本不均 衡的情况,选择 Focal 损失函数,重新定义了损失函数。实验采用 PASCAL VOC 开源数据集进行仿真验证,并与传统 SSD 目 标检测算法进行对比,准确率得到了一定的提高,验证了该算法对目标检测的有效性。
Improved SSD Object Detection Algorithm Based on Attention and Feature Fusion
WANG Haiyong, WANG Zhiqing
(School of Computer Science, Nanjing University of Posts and Telecommunications, Nanjing Jiangsu 210003)
【Abstract】: Aiming at the problem of low detection accuracy and difficult detection of small targets in object detection, an improved SSD object detection algorithm based on attention mechanism and feature fusion is proposed. Based on the standard SSD object detection model, the deep feature extraction network ResNet50 is used as the backbone network to introduce a channel-space attention mechanism in the feature extraction network to enhance the semantic information of the feature map, and calculate the influence between pixels in the feature map. Finally, the low-level features and high-level semantic information are fused with Concat features, making full use of the association information between different feature maps. In addition, the focal loss function is selected to redefine the loss function by using GIOU instead of traditional IOUs, and considering the imbalance of positive and negative samples. The PASCAL VOC open source dataset is used for simulation verification, and compared with the traditional SSD target detection algorithm, the accuracy is improved, and the effectiveness of the algorithm for object detection is verified .
【Key words】: object detection;single shot multi box detector;attention mechanisms;feature fusion
0 引言
目标检测是根据给定图片并判别出被检测的目标类 别,同时确定其所在位置及大小,并给出相应的置信 度。在图像分割、物体追踪、关键点检测等任务中都有 着广泛的应用,作为计算机视觉的一项基本任务,是计 算机视觉研究的热点领域之一。传统的目标检测算法流 程可概括为区域选择、特征提取和分类等三个步骤 [1], 但其在计算开销、算法移植、检测精度和速度等方面存在一定的劣势。相比于传统目标检测算法,基于深度学 习的目标检测算法在以上几方面均有明显的改善,根据 有无候选框生成分为双阶段和单阶段目标检测算法两 类 [2]。双阶段目标检测算法是以 R-CNN 系列为代表发 展的一系列算法及其改进型 [3-5],引入卷积神经网络和 RPN 这样一个候选框生成网络,自动学习如何更好地 提取特征,显著提高了检测的速度与精度,但与真正满 足实时性需求还有差距,由此单阶段网络应运而生,这
类算法以 SSD[6] 和 YOLO[7.8] 系列算法为代表, 不再单 独设计生成候选区域的初始阶段,而是在整张图像上一 次性完成所有目标的定位与分类。
此外,为加强提取特征图信息,提高目标检测的精 度, 很多学者对传统 SSD 目标检测算法进行了网络结 构、添加注意力机制和特征融合模块等多个方面的改 进,文献 [9] 针对多尺度单发射击检测 (SSD) 算法不同 尺度的特征层很难进行融合互补问题 , 提出一种特征增 强的 SSD 算法,文献 [10] 针对图像小目标舰船检测中 存在的检测率较低等问题,提出迁移学习 , 浅层特征增 强和数据增强 3 个方面的改进进行改进,文献 [11] 为 提升原始 SSD 算法的小目标检测精度及鲁棒性, 提出 了一种基于通道注意力机制的改进 SSD 算法, 实现小 目标及遮挡目标的有效识别。
本文针对传统 SSD 模型进行改进,提出了一种基 于注意力机制与特征融合的改进 SSD 目标检测算法, 该算法将传统 SSD 模型的主干特征提取网络由 VGG-16 换成 ResNet50.并引入通道-空间注意力机制增强高 层特征图语义信息的表达能力,同时将低层特征与高层 语义信息进行特征融合,以提高目标的检测准确率,实 验结果显示改进后的算法检测精度有明显提高。
1 本文模型
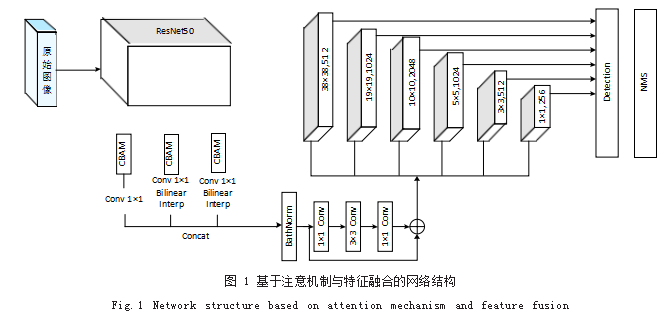
1.1 网络结构
本文模型算法使用 ResNet50 网络作为特征提取的 骨干网络,如图 1 所示。ResNet50 网络中的残差模块 可以有效的解决神经网络因为深度带来的梯度相关性衰 减的问题,提高模型对图像特征的学习能力。在主干网 络提取出来的有效特征层上的基础上增加了通道与空间 两个维度的注意力机制,使得网络模型更专注于重要的 信息的提取,同时对不同尺度的特征图进行特征融合,充分利用不同特征图之间的关联信息。
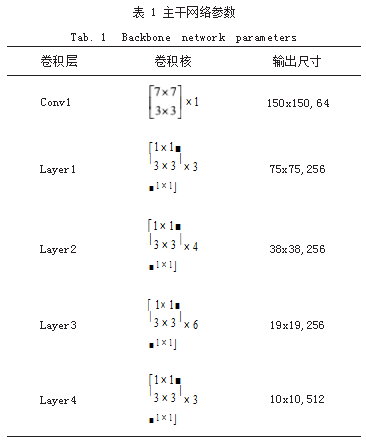
SSD 算法通过 ResNet50 网络获得其大小分别为 (38.38)、(19.19)、(10.10)、(5.5)、(3.3)、(1.1) 等 6 种 不同尺度的特征图,本文对主干网络结构进行修改,修 改后的网络各层参数如表 1 所示,在所获得的特征图上 均设置一系列固定大小的默认框。为更好地与 SSD 模 型结合,对 Layer3 和 Layer4 层修改上采样参数,保证 卷积层 Concat 特征融合后的特征图的大小不发生改变。
1.2 通道空间注意力模块
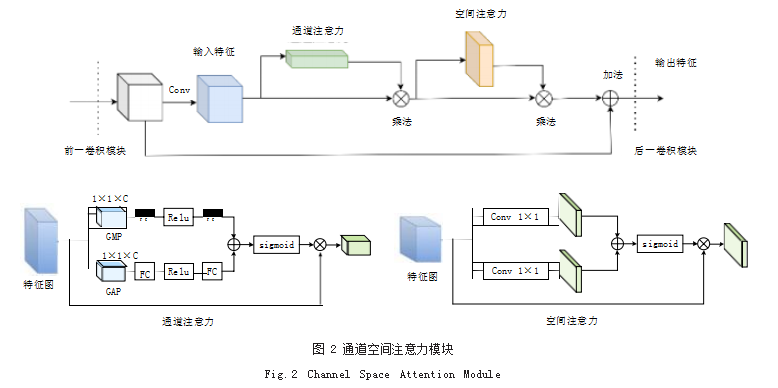
注意力机制的本质就是定位到感兴趣的信息,抑制 无用信息,在原有数据的基础上,找到数据之间的关联性,关注重要数据特征的提取。文献 [12] 提出了一个简 单而有效的前馈卷积神经网络注意力机制模块 :通道- 空间注意力机制模块 (Convolutional Block Attention Module, CBAM),该注意力机制模块由通道注意力模 块和空间注意力模块两个部分组成,因为 CBAM 是一 个轻量级和通用的模块,如图 2 所示,其中对道注意力 模块和空间注意力模块进行串联操作,它可以很方便的 集成与嵌入到 ResNet50 卷积模块中。
通道注意力模块对输入的上一层特征图分别进行 空间维度的全局平均池化和最大池化,得到了两个 1×1×C 的通道,经过全连接与激活函数后,再将得到 的两个特征进行相加。用通道注意力模块和输入的上一 层特征图相乘即可得到基于通道注意力模块改进的新特 征图。
空间注意力模块在输入的特征图上分别使用最大池 化和平均池化对每一个位置的值分别进行最大值和平 均值处理,得到了两个 H×W×1 的通道描述,然后对 其进行 Concat 拼接处理,对其连接后的特征图进行卷 积操作,最后经过激活函数计算出每个像素点分配的权 重,用空间注意力模块和输入的上一层特征图相乘便可 得到基于空间注意力模块的新特征图。
2 GIOU 与 Focal 损失函数
2.1 GIOU 引入
交并比 (intersection-over-union, IOU) 是指产生 的预测框与原标记框的交叠率,用于评估目标检测算法 的定位准确性。但 IOU 在使用过程中,存在以下问题,如果两个框没有交集,则 IOU=0.不能反映两者距离 的大小,并且 loss=0.没有梯度回传,神经网络无法学 习,且 IOU 不能反映两个物体如何重叠的情况。
GIOU 的计算示意图如图 3 所示 [13],先计算两个框 的最小外接矩形面积 C,再计算外接矩形中都不属于两 个框的区域占闭包区域面积的比重,再计算 IOU,最后 用 IOU 减去这个比重就能得到 GIOU,如式 1 所示。
式中, A 和 B 代表真实框和默认框, 最小外接矩形。
2.2 Focal 损失函数
Focal[14] 损失函数如式 (2) 所示 :
其中, pt 为类别 t 的预测概率,(1-pt)γ 为调制因子用来减低易分样本的损失贡献,无论是前景类还是背景 类, pt 越大,就说明该样本越容易被区分,调制因子也 就越小, γ 为调制参数。
SSD 损失函数中分类置信度损失采用 Soft max 损 失函数,其定义如式 (3) 所示 :
本文通过引入 Focal 损失函数替换 Soft max 损失 函数来构建新的分类置信度损失函数如式 (4) 所示 :
式中pi 为第 i 样本被预测为正样本或负样本的概率。
3 实验结果与分析
3.1 数据集与实验环境
本文实验使用 PASCAL VOC2007 和 2012 数据集, 该数据集包含 20 个类别。本文实验在 2007 和 2012 训 练集和验证集上进行训练,并在 2007 测试数据集上进 行测试。
实验环境 :操作系统为 windows,处理器为 Intel i5- 12490F,16GB 内存, 显卡为 NVIDIA RTX3060. 同时安 装 Cuda 和 cuDNN。采用 Pytorch 深度学习框架。输入 图像尺寸为 300x300. 权重衰减参数为 0.1.batchsize 为 32. 初始学习率为 0.001. 在迭代 12 万次,得到网络 训练模型,采用平均精度均值 mAP 作为评价指标 。
3.2 结果与分析
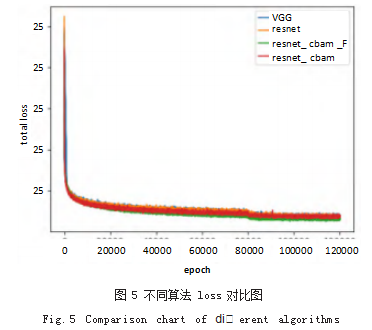
在 PASCAL VOC2007 测试集据集上的平均精度均 值 mAP 和 20 类目标检测的实验结果如表 2 和图 4 所 示,分类损失和回归损失的总损失如图 5 所示。基于注意力机制与特征融合的改进 SSD 目标检测算法在检测 精度上优于传统的 SSD 算法。
测试阶段使用单张图片进行批量测试,同时通过一 系列实验与其他算法进行对比, 以标准 SSD 算法作为 基准,对比检测每个模块的作用,表明了注意力机制与 特征融合模块能,降低了算法的损失值,提高模型的检 测性能。其对比效果图如图 6 所示。
4 结论
本文针对 SSD 目标检测算法准确性问题,结合深 层特征提取网络 ResNet50.在特征提取网络中引入通 道-空间注意力机制来增强特征图信息,考虑不同尺度 特征图之间的关联信息,将不同卷积层的输出进行特征 融合,提高了对物体的检测能力。同时,考虑交并比与 正负样本不均衡的情况,修改损失函数。在 PASCAL VOC 数据集上进行训练与测试,实验表明,基于注意 力机制与特征融合的改进 SSD 目标检测算法在检测精 度上优于传统 SSD 算法,有效提升了检测性能。
参考文献
[1] 范丽丽,赵宏伟,赵浩宇,等.基于深度卷积神经网络的目标检 测研究综述[J].光学精密工程,2020.28(5):1152-1164.
[2] 赵永强,饶元,董世鹏,等.深度学习目标检测方法综述[J].中 国图象图形学报,2020.25(4):629-654.
[3] MALINDA V,DEUKHEE L.Intervertebral Disc Instance Segmentation Using a Multistage Optimization Mask- RCNN (MOM-RCNN)[J].Journal of Computational Designand Engineering,2021.4(4):1023-1036.
[4] LIN T Y,DOLLÁR P,GIRSHICK R,et al.Feature Pyramid Networks for Object Detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2017:2117-2125.
[5] REN S,HE K,GIRSHICK R,et al.Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2017.39(6):1137-1149.
[6] LIU W,ANGUELOV D,ERHAN D,et al.Ssd:Single Shot Multibox Detector[C]//Computer Vision–ECCV 2016:14th European Conference,Amsterdam,The Netherlands, October 11 – 14.2016.Proceedings,Part I 14.Springer International Publishing,2016:21-37.
[7] REDMON J,DIVVALA S,GIRSHICK R,et al.You Only Look Once:Unified,Real-Time Object Detection[J].Computer Vision & Pattern Recognition,2016.
[8] ON J,FARHADI A.Yolov3:an Incremental Improvement [J].arXiv:1804.02767.2018.
[9] 谭红臣,李淑华,刘彬,等.特征增强的SSD算法及其在目标检 测中的应用[J].计算机辅助设计与图形学学报,2019.31(4):573- 579.
[10] 苏娟,杨龙,黄华,等.用于SAR图像小目标舰船检测的改进 SSD算法[J].系统工程与电子技术,2020.42(5):1026-1034. [11] 张海涛,张梦.引入通道注意力机制的SSD目标检测算法[J]. 计算机工程,2020.46(8):264-270.
[12] WOO S,PARK J,LEE J Y,et al.Cbam:Convolutional block attention module[C]//Proceedings of the European conference on computer vision(ECCV),2018:3-19.
[13] 侯志强,刘晓义,余旺盛,等.使用GIoU改进非极大值抑制的 目标检测算法[J].电子学报,2021.49(4):696-705.
[14] LIN T Y,GOYAL P,GIRSHICK R,et al.Focal Loss for Dense Object Detection[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2017(99):2999-3007.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/61686.html