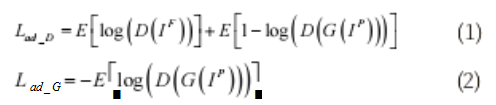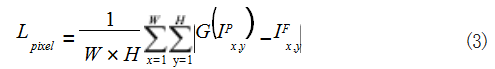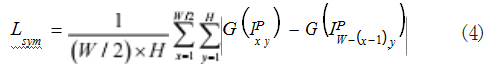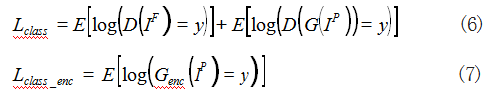SCI论文(www.lunwensci.com):
摘 要 :本文提出了一种基于生成对抗网络 (GAN) 从人脸转正过程中学习表情特征的多任务学习方法,将输入的任意角度侧脸映射为保留了表情与个体特征的正脸图像,从而减少角度对识别的影响。同时,改进了网络结构并对损失函数进行了优化,使学习到的特征更具生成与判别能力,实验结果表明,该方法在 Multi-PIE 数据集上表现出较好的表情识别性能。
关键词 :表情识别 ;生成对抗网络 ;深度学习
Multi-view Expression Recognition Method Based on GAN Facial Correction
JIANG Tao
(School of Information Technology, Guangdong Technology College, Zhaoqing Guangdong 526000)
【Abstract】:This article proposes a multi task learning method based on Generative Adversarial Network (GAN) to learn facial expression features from the process of facial recognition, map the input side face at any angle to a frontal image that preserves facial expressions and individual features, thus reducing the impact of angle on recognition. Meanwhile, improved network structure and optimized loss function, make the learned features more generative and discriminating ability, the experimental results indicate that, this method shows better expression recognition performance on Multi-PIE data sets.
【Key words】:facial expression recognition;generate adversarial networks;deep learning
0 引言
在过去的几十年里, 面部表情识别得到了很多的关注, 并成为一个快速发展的研究领域。面部表情是人类表达 情感和意图最直接、最自然的方式之一。因此,开发准 确、可靠的面部表情识别方法在许多领域中发挥着重要 作用,例如,人机交互、医疗保健、认知科学、个性发 展、虚拟现实等 [1]。然而,非约束场景下的人脸表情图 像常常有不同的头部姿势,使得不同视角下所提取出的 表情特征也有所不同,因此视角和姿势变化对于现实场 景中的表情识别来说仍然是一个具有挑战性的问题 [2]。
1 基于 GAN 的多视角表情识别方法
1.1 概述
本文提出了一种基于生成对抗性网络的多任务学习 方法,用于多视角人脸表情识别。如图 1 所示,给定 任意头部姿势和任意表情下的侧面人脸,所提出的模型将生成两种输出 :表情类标签和生成正面人脸。本文设 计了不同类型的损失函数来提取正面化过程中的表情特 征,这不仅有助于生成的正面人脸保持更多的表情特 征,而且获得的更具鉴别力的姿态不变表情特征可以更 好地提升多视角表情识别性能。
1.2 网络架构设计
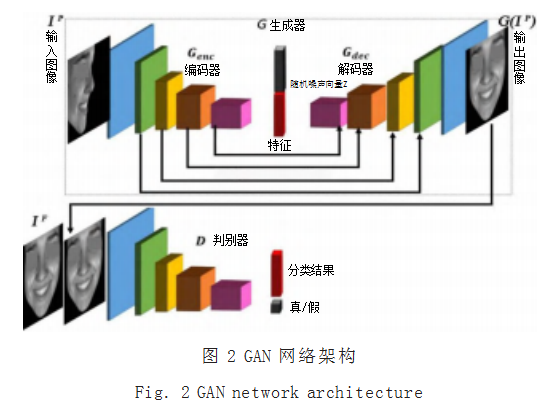
本文提出改进 GAN 网络结构,其目标不仅在于提 升人脸合成的质量,同时借助 GAN 中的对抗性损失, 更有效地促使生成器和判别器进行表征学习 [3]。所提出 的基于 GAN 的人脸表情识别方法,其模型如图 2 所示。
模型中的 IP 是具有任意头部姿态的输入表情图像, IF 是对应的真实正面表情图像,其身份和表情与 IP 相 同。模型主要包括生成器 G 和判别器 D,其中生成器 G 为编码器 Genc 解码器 Gdec 结构,编码器 Genc 用于学习人 脸表情特征, 而解码器 Gdec 被用来从 IP 提取的特征中生成与 IF 相似的正面视图 G(IP)。此外, Genc 的瓶颈层, 即提取的表情特征层,可以直接用于识别表情,因此, 设计在 Genc 瓶颈层末端附加一个全连接层来使得 G 可 以被训练用作多任务学习。
判别器 D 主要目标是区分真实图像 IF 和生成图像 G(IP),真实图像 IF 作为正样本,经过生成器处理后的 人脸表情图像 G(IP) 作为负样本,通过两者之间的对抗 使得生成的正面表情图像 G(IP) 向与真实图像 IF 相同的 分布移动,从而提高生成图像的质量。此外, D 作为判 别器,可以同时训练它识别表情,模型不仅受益于 G 和 D 之间的对抗关系,也受益于 D 的表征学习能力,因此 针对 D 的多任务学习设计可以使 G 学习更多具有判别 性的表情特征,提高面部表情识别的性能。
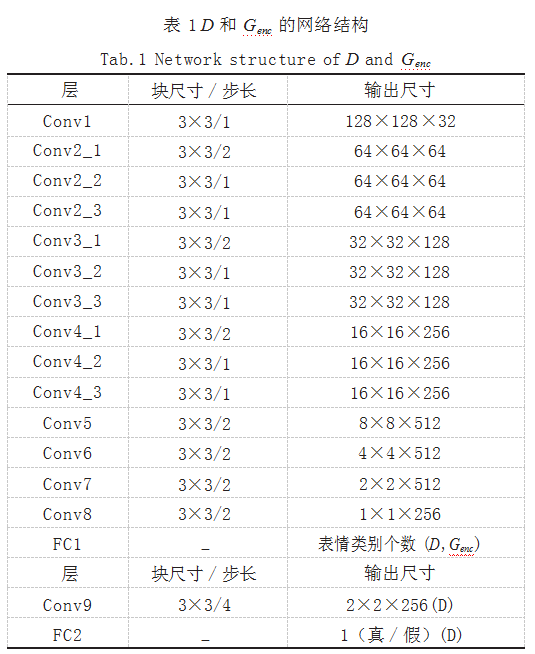
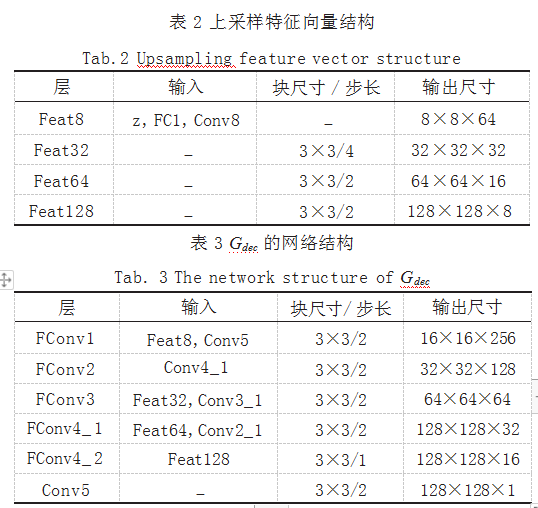
不同于一般 GAN,本文所提出的 D 判别器和 Genc 编码器的详细网络结构设计如表 1 所示, Gdec 解码器的 详细网络结构设计如表 2、表 3 所示。
在表 1 D 和 Genc 的网络结构设计中,本文使用了跨步 卷积替换了通常的池化层,并且在“Conv5”层顶部设计 了两个分支层 :“Conv6”和“Conv9”。分支“Conv6” 用于面部表情识别 ;分支“Conv9”用于区分生成图像 和真实图像, D 和 Genc 的网络结构都包括分支“Conv6”来识别表情类别,但只有 D 包含分支“Conv9”来判断 真假。另外, “Conv8”层表示来自 Genc 的待学习的表 情特征。
表2是一个反卷积结构,用于对特征向量“Conv8” “FC1”和随机噪声向量 z 的连接进行上采样。表 3 所 示结构是进行生成和重构的解码器 Gdec 的主要部分,将 编码器处理后得到的人脸图像特征、姿态和表情的编码 输入到解码器中,产生图像生成结果。另外,除了最后 一层和全连接层,模型对 G 和 D 中的所有层都采用了 Leaky ReLU 激活和批归一化。
1.3 损失函数设计
GAN 是基于生成对抗性的思想,主要通过生成器 和判别器的对抗训练来提升识别性能,它们之间的对抗 损失函数为 :Lad-D 和 Lad-G,在训练时,将 Lad-D 最大化以优化 D,将 Lad-G 最小化以优化 G,如式(1)、式(2) 所示。
在生成的正面人脸表情图像 G(IP) 和真实正面人脸 表情图像 IF 之间采用 pixel-wise L1 损失函数,用于计 算预测图像和目标图像的像素间损失, pixel-wise L1 损失函数如式(3)所示 :
其中 W、H 表示图像的宽度和高度, x、y 表示图像 空间中的位置。
不使用 L2 损失函数而使用 L1 损失函数是因为 L1 更稳健, 而 L2 损失函数对训练样本过于敏感, 容易受 到“离群值”的影响。尽管 pixel-wise 损失函数会导 致模糊效果,但它仍然是加快优化速度和提高生成性能 的重要部分。
本方法还设计了对称损失函数,目的是使得生成图 像左右对称。由于侧脸的自遮挡,需要将被遮挡的面部 部分恢复回正面视图, 一般来说,人的脸部具有对称特 征。因此,利用人脸的对称特征作为先决条件,解决姿 势较大偏转情况下的自遮挡问题,可以改善正面人脸合 成效果,对称损失函数如式(4)所示 :
另外,特征损失函数有助于生成器生成与真实正面 图像概率分布相匹配的图像,同时也能防止生成器 G 在 判别器 D 上过度训练。特征损失函数如式(5)所示 :
其中 F 表示用于匹配的特征, N 是特征的总数。
除了上述优化函数之外,本文还采用分类损失函数 来优化人脸表情识别在 G 和 D 上的性能,如式(6)、式(7)所示 :
2 实验结果与分析
2.1 数据集与预处理
Multi-PIE 数据集是当前多角度人脸表情数据集中 头部姿态偏转角度较为完备的数据集 [4], 包含 337 名受 试者的超过 750000 张图像, 其中 235 人为男性,107 人 为女性。用 13 台摄像机在不同的角度记录受试者,分别 包含 -90°、-75°、-60°、-45°、-30°、-15°、0°、15°、30°、 45°、60°、75°和 90°角的表情图像,总共记录了 6 种表情, 包括中立 (NE)、厌恶 (DI)、惊喜 (SU)、微笑 (SM)、尖 叫 (SC) 和斜视 (SQ)。在预处理中,本文应用 MTCNN 方法检测人脸 [5],根据预测的边界框和 5 个面部标志 点,裁剪检测到的面部并将其调整为 128×128 灰度图 像,并对剪裁后的图像使用均衡化处理。
2.2 Multi-PIE 数据集的实验结果
将本方法在 Multi-PIE 数据集中进行多视角面部表 情实验。使用 7 种视角 (0°、15°、30°、45°、60°、75°、 90° ), 每个视角使用 1200 张图像, 每个视角都包含 6 个基本表情的图像,将每个视角的图像随机分为 5 个子 集。其中, 4 个子集用于训练模型,训练受试者和测试 受试者之间没有重叠。
如图 3 所示展示了部分 Multi-PIE 数据集上不同角 度输入表情图像的生成结果, 0°角度下的输入图像可以 被认为是真实的正面人脸图像,可以看到 GAN 的优点 使得生成的人脸与对应的真实正面人脸 IF 相似,并且即 使在头部姿态较大的情况下,也能获得高质量的图像生 成结果,虽然面部特征的细节,如皱纹和胡须,很难完美地重建,但学习到的情感特征使生成器能够重建对应 表情的正面人脸。
如表 4 所示显示了 D(G(IP)) 和 Genc (IP) 两者在不同角 度下的整体精度,其中 D(G(IP)) 表示的是判别器 D 使用 生成图像 G(IP) 达到的准确率 ;Genc (IP) 表示解码器 Gdec 的识别性能。从表 4 中可以看到,所提方法生成的正面 人脸图像很好地保留了有效的表情特征。
3 总结
本文提出了一种基于 GAN 的多任务学习方法,用 于学习人脸正面化过程中的表情特征。判别器被训练来 区分真假和识别标签类别,生成器中的编码器不仅学习 具有代表性的表情特征,而且使解码器具有丰富的信息 以重建保持情感特征的正面人脸。通过将几种不同的损 失函数作用到网络训练中进行模型优化,生成的正面人 脸图像保持了有效的面部表情特征,且所学特征对多视角人脸表情的识别具有较好的判别效果。
参考文献
[1] 徐琳琳,张树美,赵俊莉.基于图像的面部表情识别方法综述 [J].计算机应用,2017,37(12):3509-3516+3546.
[2] 郭迎春,王静洁,刘依,等.人脸表情合成算法综述[J].数据采 集与处理,2021,36(5):898-920.
[3] 肖世明,章思远,毛政翔,等.基于风格迁移的面部表情识别方 法[J].计算机应用与软件,2023,40(2):170-177.
[4] GROSS R,MATTHEWS I,COHN J F,et al.Multi-PIE[J]. Image and Vision Computing,2010,28(5):807-813.
[5] ZHANG K,ZHANG Z,LI Z,et al.Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks[J].IEEE Signal Processing Letters,2016,23(10): 1499-1503.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/73785.html