SCI论文(www.lunwensci.com)
摘 要 :传统角色扮演游戏(RPG)的游戏性有待提高,它们通常只是向玩家展示预设的剧情和任务,玩家只能在固定的 框架内进行选择和操作,这降低了玩家的沉浸感和自由度。本文提出了一种将深度学习技术与传统 RPG 相结合的方法,通过 捕捉和分析玩家的面部表情和语音文本,将玩家的真实反应与游戏的反馈相匹配,从而增强游戏的可玩性和趣味性。玩家的面 部表情和语音文本可以作为游戏的输入信号,影响游戏的效果和结果。
A Role-playing Game Development that Combines Deep Learning Technology
YAN Yunfeng, ZHANG Haojie, QIN Yuxuan, LU Kai'ang, YAO Yuxin
(Nanjing Institute of Technology, Nanjing Jiangsu 211167)
【Abstract】:Traditional role-playing games (RPGs) have room for improvement in their gameplay, as they usually only present pre-set plots and tasks to the players, who can only choose and act within a fixed framework, which reduces the players'immersion and freedom. This paper proposes a method of combining deep learning technology with traditional RPGs, by capturing and analyzing the players' facial expressions and voice texts, and matching the players' real reactions with the game's feedback, thus enhancing the game's playability and fun. The players' facial expressions and voice texts can serve as input signals for the game, affecting the game's effects and outcomes.
【Key words】:game;deep learning technology;Unity3D;Bert;Restnet18
0引言
角色扮演游戏(RPG)是一种让玩家扮演虚拟角色 并参与故事的游戏类型 [1],其中单线发展的 RPG 主要 由两部分组成 :一部分是交互部分,玩家可以通过游戏 提供的方式进行输入 ;另一部分是剧情部分,由一系列 按顺序排列的事件构成。这样的设计可能导致玩家缺乏 沉浸感和自主性。虽然虚拟现实(VR)游戏在一定程 度上弥补了传统 RPG 的不足, 但其昂贵的成本限制了 其普及范围 [2]。因此, 将深度学习技术应用于游戏中, 通过收集和分析玩家的反应并给予相应的反馈,是一种 既能提高玩家沉浸感又能降低成本的方法。
1 游戏设计及深度学习模块简介
1.1 游戏流程设计
玩家进入游戏场景后,会遇到一个引导 NPC(非玩家角色),告诉玩家需要收集所有的物品。同时,有 一个机器人 NPC 会追逐玩家, 玩家的目标是通过所有 的检查点。由于机器人 NPC 的速度比玩家快, 玩家必 然会被抓住,此时,玩家可以按下道具键 q, 并在 3s 内表现出或说出积极的反应(比如笑或说一些正能量的 话),就可以获得一个加速道具,帮助玩家过关。
1.2 面部识别模块设计思路
1.2.1 数据集选择与处理
我们使用 CNN 网络和 CK+ 数据集来构建一个人脸表 情识别模型。在图像预处理部分,我们首先利用 OpenCV 中的级联分类器对 CK+ 数据集中的人脸进行检测和裁 剪,然后将图片缩放到 48×48 的大小并转换为灰度图。 为了增加数据的多样性,我们还对图片进行了随机翻转 的操作。
1.2.2 模型选择
为了构建一个人脸表情识别模型,我们选择了 ResNet[3] 模型系列中的 ResNet18 作为我们的网络结构。随着网 络结构的加深,虽然可以提取到更加精细复杂的特征, 但同时也容易出现退化现象,即网络性能下降。为了解 决这种问题,残差神经网络结构被提出,它通过在各层 级之间加入残差连接,有效缓解了退化问题,提高了网 络的训练效果。
残差网络模型相较于此前的网络区别在于残差模 块。残差模块包括恒等残差与非恒等残差。恒等残差计算公式如式(1)所示 :
H(x) = F(x) + x (1)
非恒等残差计算公式如式(2)所示 :
H(x) = F(x) +W(x) (2)
1.2.3 模型训练与结果分析
参数设置上我们设置批大小 (Batch_size) 为 32. 每 次训练迭代 60 个周期 (Epochs),使用 Adam 优化器, 初始学习率设置为 0.001.
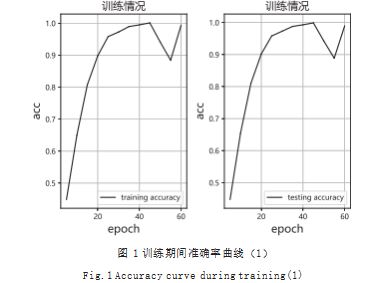
在训练期间网络准确率情况如图 1 所示。
在 50 轮时,模型基本稳定。模型同时在训练集和 验证集上获得 95% 以上的准确率。
1.3 文本情感识别模块设计思路
1.3.1 数据集选择与处理
使用包含 40 万条微博评论的数据集进行训练,将 情感简单分为两类 :积极和消极。将文本最大长度设为 50. 不足补齐, 超长截断。使用上述预处理模型所提供 的字典对句子进行编码。
1.3.2 模型选择与训练
我们使用 BERT 的预训练模型权重来训练,使用 BERT 模型抽取中文语句中的语义并进行分析 [4]。BERT是基于 Transformer[5] 模型构建的。我们可以通过微 调模型的方式快速实现下游任务的特定目标。BERT 的 Attention 机制计算过程如下 :
中间权重矩阵 WQ、WK、WV、用于生成 Q、K、V 这 三个向量, X 为每个单词转换为词嵌入向量长度。计算 公式如式(3)所示 :
Q = XWQ , K = XWK , V = XWV (3)
score 代表当前位置单词对其他单词的评分。用这 个值除以 sqrt(dk)(dk 为词向量维度)起到调节作用防止 积过大,如式(4)所示 :
score = QKT , scale = score /(4)
将上述输出进行一次归一化处理,用归一化后的结 果乘以 V 获得该词的影响力分数,如式(5)所示 :
V × softmax(scale) (5)
在数据预处理中,将文本序列头部都加了 [cls] 标 志用来表示这是一条文本或一个文本对。通常在文本分 类任务中将此位置输出的向量作为这个文本序列的语义 表示。通过抽取这一个向量并将其作为全连接层的输入 以得到句子分类的类别。
1.3.3 模型训练与结果分析
参数设置上我们设置批大小 (Batch_size) 为 32.每 次训练迭代 21 个周期 (Epochs),使用 AdamW 优化器, 初始学习率设置为 0.001.
在训练期间网络的损失曲线与准确率情况如图 2 所示。
由于我们加载了预训练模型权重,模型很快在训练 集达到了 90% 左右准确率。但是由于此数据集噪声太 多,导致验证集只能达到 70% 左右的准确率。
2 游戏实现
2.1 系统架构
系统通过游戏场景来展现关卡,包括模拟真实的碰撞和碰撞发出的声音。场景中的主要物体有角色、机器 人及相机。
2.2 游戏场景的布置
初始化每个场景中玩家的初始角色的位置。将场景 中的机器人放置在距离玩家 100 单位的相对位置,将要 收集的物品均匀分散在场景的各处,引导玩家根据收集 物放置的位置走遍场景。
2.3 游戏的实现
2.3.1 自动寻路
A* Pathfinding 中的 astarpath.cs 提供了中央舞台 的功能,展示和提供所有概览功能。在 AstarPath 的检 视面板(Inspector)可以创建和调整所有的图表和设 定。其次重要的组件就是 Seeker.cs。Seeker 组件绑定 在每一个需要寻路的 GameObject 上,供处理单位的 路径调用,并对路径进行后处理。
2.3.2 碰撞体的实现
碰撞检测部分是本系统中的核心内容,使用 Unity3D 中支持的检测函数来完成, Unity3D 支持六个碰撞检测函 数。此次游戏设计中使用的是 OnTriggerEnter(),当碰 撞体离开触发器范围时此函数被调用。例如,检测玩家 是否进入检测区域的,代码如下 :
public static int num = 0;// 记录玩家进入次数 public GameObject player;// 获取监测角色
private void OnTriggerEnter(Collider other) {
if (other.gameObject == player)// 判断玩家是否 进入检测区域
{
/* 内部逻辑 */
}
}
2.3.3 人工智能与游戏结合部分
本游戏设计利用深度学习和 Unity 引擎,在玩家进行 游戏的过程中,捕获并分析玩家面部表情,根据返回值判 断此次触发是否有效,例如, 当返回结果为愉悦时, 减缓 机器人速度。通过分析玩家音频判断玩家当时的情感,调整机器人的速度和交互方式。在 connect.cs 脚本中, 我们调用了 Python 脚本,使用 Flask 框架封装了模型 的接口。当在游戏中按下道具键 q 触发 connect.cs 脚 本时,将此时摄像头捕获的面部表情信息送入模型中 进行分析,获取此时的返回值判断此次触发是否有效。 并且调用麦克风将 3s 内玩家所说的话进行收集,通过 Whisper 模型将其转换为中文文本内容并送入 Bert 模 型中进行处理,获取情感分析结果。积极为 1.消极为 0.为了实现模型的一次加载,我们使用 Flask 框架对 代码进行封装。第一次加载将模型的参数加载到显存 中,后续做到调用只传入输入值作为模型输入。
3 总结与展望
本文介绍了一种利用深度学习技术提升角色扮演游 戏中玩家沉浸感的方法,将游戏中的玩家互动部分进行 了智能化。玩家在游戏过程中与游戏的交互更加丰富和 自然,使玩家体验到了超越传统角色扮演游戏的沉浸 感。根据不同的游戏互动需求,可以使用不同的模型完 成相应的任务, 相比于 VR, 只增加了较少的性能开销, 却获得了较高的互动性。未来将游戏接入大预言模型, 便可以实现真正的人机对话,相比于过去的线性关卡和 选择式对话,有了巨大的提升。
参考文献
[1] 田野.角色扮演类游戏中的游戏系统与游戏参与研究[J].文 化创新比较研究,2018.2(5):132-133.
[2] 韩笑.虚拟现实技术与VR游戏[J].数字技术与应用,2019.37 (09):217-218.
[3] HE K M,ZHANG X Y,REN S Q,et al.Deep Resi Dual Learning for Image Recognition[C]//IEEE Conference on Computer Vision and Pattern Recognition,2016:770-778.
[4] 徐翔,余珺君.社交网络内容用户“茧房趋同性”—基于 BERT模型的新浪微博样本研究[J].北京理工大学学报(社会科 学版),2023.25(4):182-191.
[5] VASWANI A,SHAZEER N,PARMAR N,et al.Attention is All You Need[C]//Neural Information Processing Systems(NIPS).USA:MIT Press,2017:6000-6010.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/68736.html