SCI论文(www.lunwensci.com):
摘要:情绪分析在日益发展的互联网时代极为重要,其中的研究内容主要包括语料集的选择和自然语言处理技术。为了对网民的个人情绪有较全面的了解,本文提出一种在用户授权的情况下,通过抓取输入法本地词库中的输入内容,并使用BERT和LSTM模型分析用户情感状况和情感倾向的情绪分析方法。当用户心理健康状态有下滑趋势或已处于状态较差时,则会采取相应的干预措施,以达到关怀用户的效果。
关键词:输入法;BERT;LSTM;情绪分析;情绪倾向分析;情绪关怀
Research on Sentiment Analysis and Care Based on BERT and LSTM
REN Yuxiang1,CHENG Lifei1,ZHAO Tianyi1,WANG Su1,SUN Genghui1,LIU Fang2
(1.Medical Image College of Mudanjiang Medical College,Mudanjiang Heilongjiang 157011)
(2.Modern Educational Technology Center of Mudanjiang Medical College,Mudanjiang Heilongjiang 157011)
【Abstract】:Sentiment analysis is extremely important in the growing Internet era,where research mainly includes corpus selection and natural language processing techniques.In order to have a more comprehensive understanding of the personal emotions of netizens,this paper proposes an emotion analysis method by grabbing the input content in the local thesaurus of the input method,and using Bert and LSTM models to analyze the emotional status and emotional tendency of users under the condition of user authorization.When the user's mental health is on a downward trend or is already in a poor state,corresponding interventions will be taken to care for the user.
【Key words】:input method;BERT;LSTM;sentiment analysis;emotional disposition analysis;emotional care
0引言
近年来情绪分析涉及很多较为热门的领域,其中包括的观点挖掘和倾向分析对于以商品评价[1]、预警研究[2]和倾向预测[3]为代表的各类领域具有极为重要的应用价值。伴随着社交网络的迅速发展,已有众多研究[4-6]将研究内容选为国内外网络用户较多的开放性社交平台的发布内容。由于网络的匿名化和言论自由化,人们的情绪将会被放大或真实地表达出来,那些研究者也因此实现了在某一时期对网络舆情的全面了解。这类研究对舆情背后网民的整体情绪分析较为全面,但对于很多不常用社交平台来发布内容的网络用户来说,这种研究方法针对网民个人情绪的分析研究会相对片面且较难实现。
情绪分析研究在选取研究内容的同时,也需要选择先进的自然语言处理技术。2018年,Devlin等人提出了BERT预训练模型,使用多层双向Transformer编码器对海量语料进行训练,联合所有层的左右上下文信息进行提取,以实现文本的深度双向表示。该预训练模型对词汇、句子、上下文做了充分提取,得到的是动态编码的词向量,即同一个词在不同的上下文语境中的词向量表达不一样;与此同时,LSTM模型做为较先进的倾向分析技术,能够高效完成语义分析任务。为此,基于BERT和LSTM模型,我们能更高效地分析输入法用户的情绪,检测出情绪消极的用户并为他们提供关怀。
1研究设计思路
设计思路主要分为三部分,将对网民用户的情绪做到即时分析以及对情绪消极的用户做到相应关怀。第一部分为研究内容的录入,我们将情绪分析的研究内容选为用户的输入法本地词库。在用户知情并授权后,其中的语料可保证信息来源的可靠性;第二部分为分析情绪的实现,其中BERT和LSTM模型可高效完成分析任务;第三部分为综合分析及情绪反馈,即分析网民情绪倾向消极后,相应反馈方式会在第一时间给予关怀,这将减少消极情绪走向更加极端的可能。
2输入法内容录入
2.1隐私政策
由于输入法中的本地词库内容可能涉及个人隐私,因此系统在获取爬取输入法词库的权限前,需严格遵守法律法规并向用户说明隐私政策。
(1)隐私协议:在使用前,隐私协议内容会以页面告知形式向用户介绍收集信息的目的、用途和规则。相应的法律法规及信誉承诺将会被详细列出,用户阅读并勾选所有款项后即可同意授予爬取权限。
(2)隐私保护措施[7]:为初步保证用户个人信息,系统将对个人信息匿名化处理,将用户的网络ID及词库中可能出现的网络账户进行加密,防止用户身份信息泄露。
2.2相关内容加密存储
对输入法用户的情绪分析不仅涉及本地词库,还包括了情绪分析的结果。为保证相关内容能够完整并安全地储存,每个用户的输入文本将在联网状态下定期通过HTTP协议存储于服务器相应加密网站内,防止用户的相关信息泄露。
2.3文本获取
(1)输入法词库爬取。通过爬取代码,系统对储存用户输入文本的词库进行定期语料爬取,以做到对用户的情绪实时关怀的功能。以电脑端使用最为广泛的搜狗输入法为例,通过爬取本地文件“C:Program FilesSogouInput”文字服务器中的输入法词库中语料。
(2)初步忽略无效文本。首先是为减少语料分析的工作量,爬取语料时将会减少无收集意义的语句。其主要包括特定情景下的文本输入,例如:带有“请”字的工作环境用语;其次是陈述性言论,这类文本只能代表别人的观点而不能代表用户的观点,其中包含的情绪将会对情绪分析工作造成干扰。在后续的情绪分析过程中,忽略无效文本的工作也会再次出现,此处初步减少了情绪分析的工作量。
3分析情绪
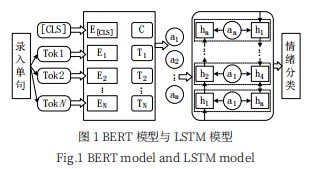
3.1 BERT模型与LSTM模型
目前情感分析方式下,基于词典的情感分析通常粒度较大,一般对整个句子或是文本进行分析判断。这样容易忽视文本和句子中更细粒度的信息,丢失很多有价值的信息,以至于不能准确地判断文本含义。传统的文本标记方法一般是人工,这样耗费大量的时间和人力资源,将影响后续的训练效果,大大降低情感分类的准确性。
BERT模型在11项NLP基准测试任务中达到state-of-the-art,证明了双向语言模型的能力更加强大[8]。首先预训练模型获取包含上下文语义信息的词向量后,利用双向长短时记忆网络提取上下文相关特征进行深度学习。引入该模型主要是为了获取文本的丰富的语法、语义特征,解决传统基于神经网络结构的语言特征表示方法忽略词语多义性的问题;而LSTM[9]是RNN的一个优秀的变种模型,继承了大部分RNN模型的特性,同时解决了梯度反传过程由于逐步缩减而产生的Vanishing Gradient问题。如图1所示,将由BERT模型处理所获取的词语语义特征输入到双向LSTM模型中,可进行精准的倾向性分类。
3.2情绪分析
3.2.1情绪分类模型
在情绪分析与关怀设想中,我们使用层级分类法[10]的情绪分类模型,其中模型结构如图2所示。这种分类模型可以改善上一层的粒度,将分析文本中包含的情绪进行四层结构的分类:第一层分析是否有情绪,如果有情绪的话则继续分类,没有将此类文本剔除;第二层在第一层有情绪的基础上进行情绪极性的二分类,分为消极与积极。通过这一层的分析结果,我们可以更快捷地识别出消极情绪的输入法用户;第三层与第四层都由上一层的结果进行多种分类;最后第四层的结果将是情绪分析的细致结果。在模拟情绪分析实验中,第三层的分类准确率可以达到90%左右。
3.2.2基于BERT模型的情绪分类方法
确定情绪分类模型后,实现该提取输入法文字进行情感分析最艰难的便是分类任务。常用的情感分析方式例如情感词典能够体现文本的非结构化特征,目前英文的情感词典衍生的情绪数值计算技术较为成熟,以此技术应用于中文时需要进行翻译工作,最后利用英文情感分析资源对翻译后进行情感极性分类,前缀步骤含有噪声且去除噪声步骤较为繁琐。
BERT的基础建立在Transformer之上,拥有强大的语言表征能力和特征提取能力。由于在用户日常输入中会包含大量无用信息,这些无法为情绪分析提供支持的信息,在情感倾向性分类的任务里所起作用不大。从数据集中可以看到存在文字表情,其中包含了明确的情感倾向性信息。在此后对该类型的数据保留处理,结合上下文进行分析、降噪等操作,最终完成数据集的预处理。
相对于词典的情感分析,BERT模型的设计将任务分为上游和下游两个部分,其中上游任务主要的目的是在保留文本句意的情况下,将文本以向量的形式进行表达,用以处理下游任务。BERT模型的预训练过程中直接对中文进行提取,会在输入词序列中随机遮蔽,同时进行下一句预测任务。下游任务实现分类判别,利用更为精准的LSTM模型进行判别,这样可学习到能够融合两个不同方向文本的表征。
3.3实现情绪分析操作
3.3.1用BERT预训练模型提取⽂本特征一个句子的提取:
inputs=tokenizer("中文",return_tensors="pt")#"pt"表示"pytorch"
outputs=bert(**inputs)
tokenizer会在文本开始和结尾分别添加[CLS]和[SEP]标记,返回给inputs的是一个字典。示例情况如图3所示:
以下为实现代码:
key
value
'input_ids'
tensor([[101,704,3152,102]])
'token_type_ids'tensor([[0,0,0,0]])
'attention_mask'tensor([[1,1,1,1]])
bert的输出outputs包括last_hidden_state与pooler_output:
outputs.last_hidden_state.shape#torch.Size([1,4,768])
outputs.pooler_output.shape#torch.Size([1,768])
多个句子的特征提取(长度不等时会进行填充):

 4分析结果整合及相应反馈
4分析结果整合及相应反馈
4.1分析应用
对输入语料的情绪分析结束后,系统将针对模型给出的不同层次的多种分类结果进行整合分析,判断用户是否需要关怀。
整合分析即为在特征及倾向性分析后,系统统计并整合分析语料集中的各类情绪。其中各种情绪出现的频次及占比会成为表现用户情绪的极性程度的依据。尤其是情绪消极的用户,其出现的负面情绪的程度分析尤为重要。根据对消极情绪的分析,可将是否极端抑郁作为判断标准,将这类用户分为两类。由于极端抑郁的用户情绪极端,他们往往会做出伤害到自己或周围人群的过激行为,因此需要特别关注。
4.2情绪关怀反馈流程
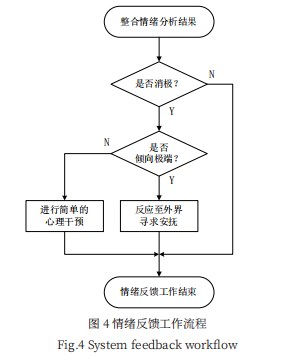
为了便于理解系统的反馈工作流程,进行用户情绪关怀的具体流程如图4所示。
系统针对情绪分类模型第2层树结构给出的结果进行判断,如若用户细分筛选后并未发现消极情绪倾向,系统无需干预,即可结束关怀流程。如若模型发现用户具有一定的消极情绪倾向,对应文本信息将进入第3、4层的情绪分析模型筛选分类—判断用户情绪是否倾向于极端抑郁状态。
当用户情绪倾向表现为一定的消极情绪时,系统将进行相对简单、温和的心理干预反馈,如:推送温馨的关怀消息、建议用户向好友倾诉、信息引导用户散心、进行娱乐活动等。系统借助这些温和、简单的关怀干预,以化解用户轻微的消极情绪。
当情绪分类模型筛选分析的结果显示用户有较严重的抑郁心理倾向时,为防止用户采取自杀等极端行为方式,系统会立即联系用户好友关怀其情绪,通知用户的紧急联系人,将用户的极端情绪倾向反映至外界,寻求更高效率的安抚手段,以制止用户采取极端行为,极力避免悲剧的发生。如存在用户情绪持续不佳,系统将酌情用户的情况及时报送有关部门,联系公安部门等请求其介入,阻止用户极端行为的发生;除此之外,系统也会采取发送信息安抚用户、提供心理咨询热线的方式,进行简单的自杀干预,以平稳用户的情绪。
在整个系统的反馈工作流程中,系统实现对用户的定期情绪状态的分析、记录、评估,把握分析结果,挖掘用户真实情绪和倾向,帮助用户自身具象化地了解自身的心理状态;同时还实现了对用户情绪变化的实时关怀,在第一时间完成对情绪消极用户的关怀,阻止情绪走向危险的用户的过激行为,切实在系统的情绪分析的基础之上,关怀用户的心理健康与生命安全,减少消极情绪的负面积累。
5结语
输入法作为互联网用户广泛使用的软件,其中词库的语料对于情绪分析及关怀具有重大参考意义。但对于用户词库使用的同时也需要对用户的隐私进行保护,隐私保护技术需要根据日益发展的网络技术进行相应的更新。本文使用较为先进的BERT模型与LSTM模型对输入内容的语法、语意进行获取并分析,但二者的计算复杂度比较高,需要进一步降低复杂度。在情绪分析与关怀设想中,本文使用了层级分类法,从而对用户的情绪分类,并将识别的情绪概念化。后续将增加改进工作,提高情绪分析的准确率并降低计算复杂度,更高效地进行情绪识别,寻找关怀对象并给予帮助。人们日常生活使用的文本无处不在,利用文本进行情绪分析,同时对情绪消极的用户进行关怀,是一个新的发展方向。情绪分析及关怀技术的应用前景可观,我们在未来需要不断地挖掘并完善这些技术,将此类技术的准确率和工作效率提高。
参考文献
[1]江涛.基于MLP神经网络的商品评论情感分析[J].电子制作,2021(12):36-37+78.
[2]郑苏晋,郭海若,宋姝凝,等.社交媒体数据对台风灾害的预警研究—以利奇马台风为例[J].管理评论,2021,33(10):340-352.
[3]朱道平,张灿凤.考虑不同平台评论情绪的电商产品销量预测研究[J].市场周刊,2021,34(3):91-93.
[4]刘洪浩.基于深度学习的COVID-19疫情期间网民情绪分析[J].软件,2020,41(9):185-188.
[5]华蓓,彭雪淳.基于词典和规则集的微博情绪分类方法研究[J].太原师范学院学报(自然科学版),2021,20(4):48-54.
[6]Marchi V et al.Attitudes Towards Urban Green During the COVID-19 Pandemic Via Twitter[J].Cities(London,England),2022,126:103707.
[7]张小波,付达杰.网络信息资源个性化推荐中隐私保护的研究[J].软件,2015,36(4):62-66.
[8]刘思琴,冯胥睿瑞.基于BERT的文本情感分析[J].信息安全研究,2020,6(3):220-227.
[9]谌志群,鞠婷.基于BERT和双向LSTM的微博评论倾向性分析研究[J].情报理论与实践,2020,43(08):173-177.
[10]王安.突发事件下微博舆情的话题发现和情绪分析研究[D].重庆:重庆邮电大学,2021.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/45692.html