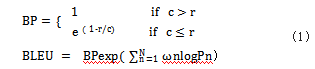SCI论文(www.lunwensci.com)
摘 要:为了解决现有的代码补全方法因数据集有限而不能有效地提高模型的泛化能力和特征向量间语义不紧密的问题, 本文设计了基于 RoBERTa 模型,结合数据增强和代码文本 Embedding 技术(代码词嵌入技术) 的 RoBFill 代码补全模型。 本文通过在 6 个安卓数据集上进行三组比较实验,三组实验基于 RoBERTa 模型,分别使用数据增强技术、代码词嵌入技术、 数据增强技术,结合代码词嵌入技术这三个角度来验证本模型的有效性,本文实验在 RoBERTa 模型的基础上增加了技术层面 的创新。通过实验结果可以得知,基于 RoBERTa 的数据增强与代码词嵌入代码补全模型能够提高代码补全的性能,使预测的 准确性提高。
关键词:代码补全,RoBERTa,代码数据增强,代码词嵌入
The Code Completion Model of Data Augmentation and Code Word Embedding Based on the RoBERTa
YANG Wanling
(Dalian University of Foreign Languages, Dalian Liaoning 116044)
【Abstract】: In order to solve the problem that the existing code completion methods cannot effectively improve the model generalization ability and the semantics between feature vectors are not tight due to the limited data set, this paper designs RoBFill code completion model based on RoBERTa model and integrating data enhancement and code text Embedding technology. Based on six android data sets compared three groups of experiments, three groups of experimental model based on RoBERTa, respectively using data enhancement technology, embedding technology, the code word data enhancement technology combined with embedded code word these three angles to verify the effectiveness of this model, in this paper, the experiment on the basis of RoBERTa model increases the technical innovation. The experimental results show that the RoBERTa based data enhancement and code word embedding code completion model can improve the performance of code completion and improve the accuracy of prediction.
【Key words】: code completion;RoBERTa;code data augmentation;code word embedding
1 相关概念及问题定义
代码补全是自动化程序生成的方法之一,通过预测 下一步的代码编写, 如 :关键字、类名等, 能够辅助编 程人员进行软件开发,进而缩短编程时间,提高编程效 率。随着互联网技术的快速发展,深度学习也应用在代 码补全的领域中 [1],这为自动化程序开发创造了更多的 可能。在代码补全领域的发展过程中,代码补全的方式越来越多,如基于关键字、变量名这样 Token 级别的 代码补全、补全代码片段和补全 API[2] 以及各种表达式 和语句的生成等。本文旨在实现代码 Token、代码行、 代码块三个粒度上的代码补全。
在代码补全领域,众多学者提出了丰富的研究方 法。Zhao 等人 [3] 提出了一种新的分布式内存架构代码 补全方法,同时提出通过一些基于代码生成规则来构建通信集,并且验证了它们的正确性和准确性。另外, N-gram 模型是重要的代码补全方法 [4], 它是最常用的 统计语言模型之一,在句子中第 N 个词的出现只取决 于前 N-1 个单词,与其他词无关,所以整句的概率即为 每个词出现概率的乘积。
尽管目前在补全代码片段等不同粒度上的文本已 比较出色 [5.6], 但是现存的代码补全方法仍然存在一些 问题,如因数据量有限而导致泛化能力的提升受到了 限制,模型虽然对其训练示例运行准确但推广到未知 的测试数据时现有模型的稳健性和准确性有待提升。其 次,在设计向量时往往会导致矩阵稀疏,联系不紧密,致 使预测的准确率有待提高。针对以上问题,本文提出了一 种基于 RoBERTa 的 RoBFill(RoBERTa Filled with Data Augmentation and Code Word Embedding) 模型, 该 模型在 RoBERTa 模型的基础上增加了一个代码数据增 强机制,通过该机制扩展训练集,有效地解决了泛化能 力较差的问题。数据增强是一种数据扩充技术,是从现 有的样本中生成新的样本,在数据约束的环境下提高模 型性能的泛化性,实现数据增强的方法多样,如使用抽 象语法树等 [7]。本文还使用了代码文本的 Embedding, 将向量转换成低维稠密特征向量,增强语义,提高准确 率。为了验证基于 RoBERTa 的 RoBFill 模型的有效性, 本文与基于 BERT 模型的代码补全方法方法进行了对 比,通过在 6 个 Android 数据集上的实验验证,基于 RoBERTa 的 RoBFill 模型在精确率上表现更优。
2 模型设计
如图 1 所示描述了本文提出的 RoBFill模型框架图,其流程如下,首先通过替换变量名等数据增强的方式将代码文 本生成语义和功能一致的多份文本,增大数据集,再将一份 文本中的所有Token 通过 BPE 算法每次用一个新的Token 合并出现最频繁的字符对,迭代此操作,最后成为新的 Token 序列, 再将新的Token 通过Wordembedding 转 换成向量 Vector,组成的向量序列输入到 RoBERTa 模 型中,经转换输出融合了上下文语义信息的向量,最后 转换成预测的 Token。
2.1 BERT 模型与 RoBERTa 模型
BERT 模型是近年在 NLP 领域最具突破性的一项技 术 [8.9],该模型的训练分为预训练阶段和 Fine-tuning 阶 段。BERT 的第一个预训练任务是 Masked LM(MLM), 是指在句子中随机掩盖 15% 的词汇用于预测,这 15% 的词汇中 80% 的概率用特殊标记 [MASK] 替换, 10% 的概率使用任意词汇替换,剩余 10% 的概率保持原词 汇不变,通过这种掩盖方式可以在一定程度上避免预训 练阶段和 Fine-tuning 阶段不匹配的问题。BERT 的第 二个预训练任务为 Next Sentence Prediction(NSP), 即判断输入模型的两个句子是否连续。通过预训练阶段 能够使 BERT 输出的每个结果更加贴合输入文本的全局 信息。在 Fine-tuning 阶段可以将预训练后的模型迁移 到具体的 NLP 任务中,只需重新学习任务所需的部分 参数就能够达到较高的准确率,无需做复杂的修改。
RoBERTa 模型是 BERT 模型的优化版本 [10.11],在自 然语言任务处理取得了更好的效果,相较于 BERT 模型 RoBERTa 主要做出了以下改进 :(1)使用动态 Mask: BERT 使用的是随机静态 Mask,被选择掩盖的 Token在训练过程中不会再改变,而 RoBERTa 将预训练的数 据扩大成相同的多份,即每个文本有多种 Mask 的方 式,避免训练数据重复,在每次向模型输入数据时会生 成不同的掩码方式,能够使模型不断学习新的掩码模式。 (2)取消 NSP 任务 : 通过 RoBERTa 的实验表明,不采 用 NSP 任务能够小幅度地提高模型的性能,所以取消 NSP 任务。(3)增加训练数据 :通过扩大数据量能够使 模型性能有较大地提升。如图 2 所示展示了 RoBERTa 模型的框架图, RoBERTa 模型由若干层 Transformer Encode 组成,表示为将输入的字向量增强语义,并输 出相同长度向量的黑盒,Encode 的第一层 Multi-head Attention 是由多个 Self-attention 组成, 通过计算所有 Token 的语义信息,得到每个 Token 的增强语义向量,并 且使用多个 Self-attention 可获得每个 Token 在不同空间 下的增强语义向量,多个向量进行线性组合,最终获得与 输入向量等长的增强语义向量。Multi-head Attention 的上 方为 Add& Norm, Add(残差连接)将输入与输出相加, 使网络更加容易训练,Norm(Layer Normalization)将 每一层的激活值归一化。Feedforward 层更加能够表示 Token 之间的作用关系。经过多层 Encode 训练后便得 到结合上下文语义的向量。
2.2 代码数据增强
数据增强是指在原有数据集的基础上创造出更多有 价值的数据,拥有足够的训练数据可以使模型更出色,如该技术在应用于人脸识别时, Aleksei Zhuchkov 通 过增强面部图像扩大数据量,提高了识别的准确性。 本文采用的代码数据增强技术其关键在于新生成的代 码片段在语义和功能上与原始的代码片段一致,使 程序能够正常运行并产生相同的输出结果。本文采用 了如下基于规则的代码数据增强方式 :(1)将 Java 中 for、while、do while 循环语句互相等效替代 ;(2) 替换变量名和参数名,名称的改变不会改变变量和参数 的实际类型, 从而对代码的语义并无影响 ;(3) 增加 冗余的中间变量,同时不改变代码的语义和功能 ;(4) 调换类中函数定义的顺序,这并不会改变函数的具体 功能。
2.3 代码文本的 Embedding
本文采用该技术的目的是通过 Byte Pair Encoding (BPE) 将代码里的 Token 转换成向量。BPE 是一种数 据压缩算法,是在代码文本中每次用一个新的 Token 来合并出现最频繁的字符对,并把它们添加到原先的代 码文本中,迭代此操作,直到达到预先设定的阈值,即 实现了数据压缩。通过 BPE 算法,减少了代码文本中 的 Token 数量,可以减小内存占用空间,提高模型预 测的准确性。通过 Embedding 技术将 Token 向量化, 避免向量稀疏和保留上下文语义,保证文本信息的完整 性。BPE 的算法流程如下 :(1)准备数据文本,确定期 望词典大小的阈值 ;(2)通常在每个词汇末尾添加后缀,统计每个词汇出现的频次,如 public 出现的次 数为 8. 即表示为“public”:8 ;(3) 将文本中所 有词汇拆分成单个字符构成词典,统计所有字符出现的 频次 ;(4)选择出现频次最高的字符对合并,例如 p 和 u 出现的频次最高, 则将文本中所有相邻的 p 和 u 合 并成 pu,并将其加入词典 ;(5)迭代步骤(3)和(4) 至词典中的词数达到设定的阈值。
3 实验设计
3.1 数据集
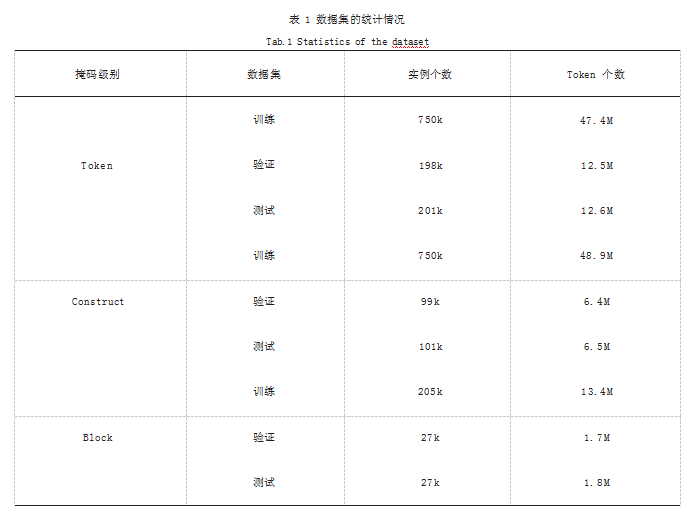
本文采用了 GitHub 中 Android TimeMachine 数据 集里的开源安卓应用程序, 为此构建了 6 个 Android 数据集。这 6 个数据集中包含两个代码表示(原始版本 和抽象版本), 每个代码表示包括三个不同的掩盖级别 (Token、构造、块)。数据集具体的统计情况如表 1 所 示。从表 1 可以看出,本文选取的数据集涵盖了大量的 实例个数和 Token 个数,这提升了实验结果的可信性。 数据集被分割成训练集、验证集和测试集,其中训练集 用于构造模型,验证集用于调整和优化模型,测试集用 于评价模型的性能。
3.2 评价指标
本文所采用的评价指标是 BLEU score 和 Levenshtein Distance,这是两个常用于评价代码补全模型性能的评 价指标。
(1) BLEU score :是用来评估机器翻译的质量, 其核心为判断两个句子的相似度, BLEU 将机器翻译结 果与参考翻译相比较,分数范围是 0-1.算出的分数越 高,说明机器翻译的质量越好,本文中 BLEU score 分 数为 1 则表示预测输出的 Token 代码与参考代码相同。 c 表示生成代码的长度, r 表示参考代码的长度。BLEUscore 的计算公式如式(1)所示 :
(2) Levenshtein Distance :又称编辑距离,是用 来计算两个文本相似度的方法,在本文定义为预测代码 转换成参考代码所需的最少 Token 编辑次数(编辑方 式包括插入、删除、替换)。x,y 分别为预测代码和参考 代码的长度。Levenshtein Distance 的计算公式如式(2)所示 :
Similarity=(Max(x,y)-Levenshtein)/Max(x,y)
3.3 对比方法
3.3.1 RoBERTa 模型
本文的第一个对比方法为 Matteo Ciniselli 等人 [12] 的 RoBERTa 代码补全方法。在 RoBERTa 模型中,使 用了一个预处理任务,用一个 标记掩盖多个 Token,可以避免因一个 掩盖一个 Token 的 掩盖跨度太大而导致超出固定序列长度的问题 ;另外, 引入迁移学习为几个任务微调模型 ;使用 BPE 编码方 式,用字节作为词汇构成词典,将输入文本根据词汇的 索引转换成对应的数值,再转换成张量输入到模型中, 最后预测出 Token。
3.3.2 N-gram 模型
本文对比的第二个方法为 N-gram 模型,其关键为 第 n 个单词的出现只与其前 n-1 个词有关,整个语句的 概率就是各个词出现的概率相乘。在本文通过 N-gram 来单独预测每个掩盖的 Token, 然后结合所有预测的 Token 生成最终的字符串。
4 实验结果
4.1 数据增强技术对代码补全性能的影响
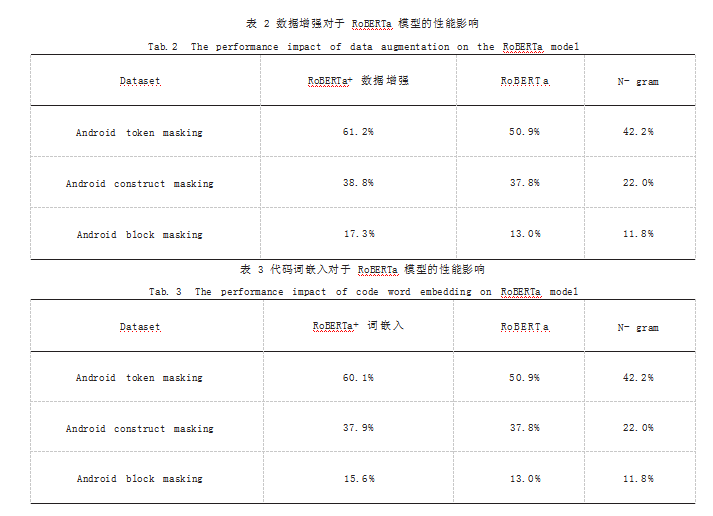
为了探究数据增强技术对代码补全模型性能的影 响,本文对增加了数据增强技术的 RoBERTa 模型和原 始的 RoBERTa 模型在本文的数据集上进行了对比实 验。该对比实验采用文本文件中的完美预测率作为评估 指标。 实验在 Token Masking、Construct Masking 和 Block Masking 三个由细到粗的粒度上进行。从表 2 可以看出在 RoBERTa 模型上,使用数据增强技术来扩 充训练集,可以有效地提升代码补全的性能。增加了数 据增强技术的 RoBERTa 模型分别在这三个粒度上对原 始 RoBERTa 模型的提升达到了 0.3%、1.0% 和 4.3%, 其中对 Block Masking 粒度的模型提升效果最为显 著。由此看出,数据增强技术对于提升代码补全性能是 有效的。另外,两种基于 RoBERTa 的方法的表现远比 N-gram 表现好。
4.2 代码词嵌入技术对代码补全性能的影响
为了探究代码词嵌入技术对代码补全模型性能的影 响,本文对增加了代码词嵌入技术的 RoBERTa 模型和原始的 RoBERTa 模型在本文的数据集上进行了对比实 验。该对比实验采用文本文件中的完美预测率作为评估 指标。 实验在 Token Masking、Construct Masking 和 Block Masking 三个由细到粗的粒度上进行。如 表 3 所示可以看出在 RoBERTa 模型上,使用代码词嵌 入技术可以有效地提升代码补全的性能。增加了代码 词嵌入技术的 RoBERTa 模型分别在这三个粒度上对原 始 RoBERTa 模型的提升达到了 0.2%、0.1% 和 2.6%, 其中对 Block Masking 粒度的模型提升效果最为显著。 由此得出,代码词嵌入技术对于提升代码补全性能是 有效的。另外,两种基于 RoBERTa 的方法的表现远比 N-gram 表现好。
4.3 RoBFill 模型性能验证
为了探究 RoBFill 模型在代码补全问题上的有效性, 本文将 RoBFill 模型的代码补全性能与领域内前沿的模 型 RoBERTa 进行了对比实验。实验在 6 个安卓数据集 上进行, Raw 表示在源代码上进行的实验, Abstract 表示在代码的抽象表示上进行的实验。实验分成 Token Masking、ConstructMasking 和 BlockMasking 从细到粗 三个粒度。实验的评价指标包括 BLEU-1、BLEU-2、BLEU- 3、BLEU-4 和 Levenshtein 分数。表 4 中的数值左边表示 RoBFill 的实验结果,右边的数值表示 RoBERTa 的实验 结果。如表 4 所示可以看出,在 BLEU 和 Levenshtein 两类评价指标上,总体上本文的 RoBFill 方法在各个粒度以及各个代码抽象程度上都对 RoBERTa 模型的代码 补全性能有一定程度的提升。尤其是在 Levenshtein 指标上, RoBFill 模型几乎在所有的场景下都提升了 RoBERTa 的性能。在 BLEU 指标上,总体而言 RoBFill 模型在 Token Masking 和 Block Masking 粒度上对于 模型的提升更显著。
5 结语
代码补全是开发人员进行代码编写时重要的辅助 工具,它有助于提高开发效率,减少拼写错误。本文 提出了一种基于 RoBERTa 模型的 RoBFill 代码补全方 法,因现有的方法不能在有限的数据集下提高其泛化 性,上下文语义的特征向量不紧密,且其准确率有待提 升,所以本文基于 RoBERTa 模型结合代码数据增强技 术,进一步利用代码文本的 Embedding 技术来优化性 能,增加了技术创新。本研究在大规模的数据集上进行 与 RoBERTa 模型和 N-gram 模型的三组比较实验,通 过观察实验结果可以说明,基于 RoBERTa 模型,再结 合代码数据增强技术和代码文本的 Embedding 技术能 够提升代码补全的准确率,验证了本文提出的 RoBFill 方法的有效性,最终可以提高代码补全的性能。
参考文献
[1]胡星,李戈,刘芳,等.基于深度学习的程序生成与补全技术研 究进展[J].软件学报,2019.30(5):1206-1223.
[2]马张驰.基于统计语言模型的个性化API补全方法研究[D].南 京:南京大学,2020:30-46.
[3] ZHAO J,ZHAO R C,XU J C.Code Generation for Distributed-memory Architectures[J].The Computer Journal,2015. 59(1):119-132.
[4]陶传奇,包盼盼,黄志球,等.编程现场上下文深度感知的代码 行推荐[J].软件学报,2021.32(11):3351-3371.
[5]韩奇.基于结构嵌入分析的智能代码推荐系统的设计与实现 [D].南京:南京大学,2020:45-67.
[6]殷康麒.基于差异代码克隆搜索的代码块补全推荐算法研究 [D].合肥:中国科学技术大学,2019:35-50.
[7]汤闻誉.基于抽象语法树局部与全局关系的代码补全方法 [D].南京:南京大学,2021:28-60.
[8]张俊,陈秀宏.基于BERT模型的无监督候选词生成及排序算 法[J].南京大学学报(自然科学),2022.58(2):286-297.
[9]范安民,李春辉.改进BERT的中文评论情感分类模型[J].软件 导刊,2022.21(2):13-20.
[10]孟晓龙,任正非.基于RoBERTa模型的公众留言分类研究 [J].现代计算机,2021.27(28):21-26.
[11]赵姝颖,肖宁,曾华圣,等.基于RoBerta的立场检测与趋势预 测模型设计[J].应用科技,2021.48(3):27-33.
[12] CINISELLI M,COOPER N,PASCARELLA L,et al.An Empirical Study on the Usage of BERT Models for Code Completion[C]//2021 IEEE/ACM 18th International Conference on Mining Software Repositories(MSR).May 17-19.2021.Madrid, Spain.IEEE,2021:108-119.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/52620.html