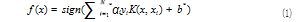SCI论文(www.lunwensci.com)
摘 要:分类是数据挖掘的研究分支,用于发现数据中隐含的模式并实现数据的类别划分,通常将每一个类别称作概念。 本文首先介绍数据挖掘现有的应用研究 ;其次,应用传统机器学习方法及群智能算法,对比分析不同方法的实现 ;最后,对未 来工作进行展望。
Survey of Classification Methods Based on Data Mining Tasks
HAN Chengcheng
(Liaoning Vocational University of Technology, Jinzhou Liaoning 121000)
【Abstract】:Classification is a research branch of data mining, which is used to discover hidden patterns in data and realize the classification of data. Each category is usually called a concept. Firstly, the application research of data mining is introduced; Secondly, the traditional machine learning method and swarm intelligence algorithm are used to compare and analyze the implementation of different methods; Finally, the future work outlook.
【Key words】:support vector machine;random forest;genetic algorithm
1 相关工作
随着信息通信技术的日益成熟,物联网和无线通信 已经广泛应用于工农业生产、生态环境保护、公共安全 监测和人体健康跟踪等领域,用以实时记录并传输状态 数据。从数据挖掘的角度讲,流数据的处理包括分类、 聚类、关联规则提取、序列模式发现和异常检测。其中, 流数据分类用于将当前数据流(段)划分到某个事先确 定的类别当中,是流数据挖掘的重要研究分支,已经引 起了学术界的普遍关注。基于传统静态数据挖掘技术, 开发流数据分类模型、算法和方法是学术界普遍采用的 做法,其中决策树在流数据分类研究中扮演着重要角色。
数据挖掘是人工智能和数据库领域的热点研究问 题, 在数据库的知识发现中扮演着重要角色。数据挖掘 就是要从随机产生的、富含噪声的大量不完整数据中获取 事先未知但潜在有用的信息和知识,以提取出数据的模型 及数据之间的关联, 进而实现数据变化趋势和规律的预 测。数据挖掘主要包括数据准备、规律寻找和规律表示三 个步骤。其中,数据准备从相关的数据源(如商品交易记录、环境监测数据、经济运行数据等)中选取所需的数 据,并经清洗、转换、整合等处理生成用于数据挖掘的 数据集 ;规律寻找应用某种方法(如机器学习和统计方 法)发现数据集中隐含的规律 ;规律表示以用户尽可能理 解的方式(如可视化)将从数据中发现的规律表示出来。
数据挖掘的任务主要包括分类、聚类、关联规则挖 掘、序列模式挖掘和异常点检测。其中,分类是指通过 在给定的一组已标记数据集上训练模型,预测未标记的 新数据所属类别的过程。不同于分类问题,聚类能够在 不给定数据标签的情况下,实现数据的类别划分。由于 聚类操作不需要对输入数据做预先标记处理,完全根据 数据自身的属性实现类别的划分,因此属于无监督学习 的范畴。关联规则挖掘用于发现事物(如商品的购买) 之间的某种关联关系。序列模式挖掘是从序列数据库中 发现高频子序列的过程 [1]。异常点检测用于自动发现数 据集中不同其他数据的“异常”数据 [2]。
传统的文本挖掘技术仍然广泛应用于不同的文本挖掘 领域,其中分类方法在文本挖掘研究中扮演着重要角色。
2 分类算法
2.1 SVM 的算法原理及其优化
2.1.1 SVM 的算法原理
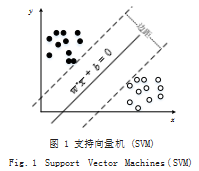
支持向量机 SVM 作为传统机器学习典型算法,解 决小数据集时具有优势。SVM 算法能够求解正确划分 数据集和几何间隔最大的分离超平面。如图 1 所示, 黑圈和白圈分别代表正确划分文本类别和划错文本类 别,支持向量机寻找虚线之间最大化边距的分离超平面 w·x + b = 0 ( w 为平面法向量, x 为特征量, b 为位移 )。
根据本实验文本数据特点, SVM 引入核函数把包含 五元组的样本映射到高维特征空间中,使得样本线性可 分。对于给定的特征集合 T={(X1.y1),(X2.y2),… ,(XN,yN)}, 分类决策函数如式(1)所示 :
其中, Xi ∈ Rn , yi ∈ {-1.1}, 对应疾病类型 C, i=1.2. …,N。
核函数 K(.) 作为非线性分类不可或缺的一部分, 本 实验采用两种核函数比较 SVM 分类结果。其中,多项式核函数 (Polynomial 核函数 ) 表达式如式(2)所示 :
上述两种核函数由于适合解决小数据集,且处理非 线性问题,因此,将这两种核函数引入 SVM 中,分析 二者的识别结果,选择最优核函数分析分类效果。SVM 的分类过程如下所示 :首先,通过对数据特征提取得到 的表征构成 4 维向量空间,将其表示为向量形式 ;其次, 通过 SVC 方法对向量形式的训练样本训练学习, 得到分 类模型 ;最后,分类模型对测试样本判断预测,得到最 终的分类结果。
整个模型的关键步骤就是调参过程,本实验选择 c和 g 作为 SVC 方法的参数, c 为惩罚系数, c 越大,模 型对样本的学习更准确,但易发生过拟合。g 影响核函 数中的 σ 值, g 越大, σ 越小,易发生过拟合 ;g 越小, σ 越大,易发生欠拟合。因此参数的选择影响着整个模 型的分类效果。
2.1.2 遗传算法优化
遗传算法 GA 作为一种群智能算法,主要通过选择、 交叉及变异过程实现。通过遗传算法找到 SVM 参数 c 和 g 的全局最优值,分析统计该方法的性能。具体的算 法流程如图 2 所示。
算法首先选择初始种群,种群是染色体组,染色体 代表特征集合,每个染色体用二进制编码, 1 代表选中该 特征, 0 代表未选中该特征。例如,染色体 Ci=[0.1. 1.1], 说明这 4 个特征中,第 2. 3. 4 的表征形状、程度、状 态被选择作为子特征。然后利用轮盘赌方法选择染色体 Cj (j ≠ i),染色体 Cj 被选中的概率如式(4)所示 :
其中, E(Cj) 是染色体 Cj 的精度, |pop | 是种群数。
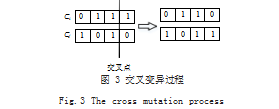
最后进行交叉变异操作,当染色体对在交叉点基因交 换后,将 1 转换为 0.将 0 转换为 1.具体如图 3 所示, 交叉变异后第 1. 3. 4 的表征位置、程度和状态被选中。
通过选择、交叉变异操作后生成的新种群如果没有 满足设定的种群数量时,则继续循环。直到满足终止条 件为止,输出最优解,也就是 SVM 的参数。
2.2 随机森林及其优化
随机森林作为一种机器学习方法,因其有着较好的 分类性能,广泛应用于计算机辅助的各个领域。本文采 用决策树作为随机森林的基分类器。决策树生成过程主 要运用信息熵理论,采用基尼指数选择划分属性,基尼 指数越小,数据集的纯度越高。基尼纯度表示在子集中 正确选择一个随机样本的可能性。对于给定的五元组集合 D={D1.… ,Dn} 以及一个五元组 Di (1 ≤ i ≤ n) 中的疾 病类别 Ck (1 ≤ k ≤ K),基尼值定义如式(5)所示 :
其中, Dv 是指当表征为 a 时第 v 个疾病类别的样本 集合。
选择基尼指数小的作为分裂节点,按照上述过程依 次选择节点,直到不能再继续划分为止。具体步骤算法 如表 1 所示。
算法通过有放回抽样抽取 k 个样例,得到训练集。 剩余少数数据作为测试集。对于每棵决策树,算法首先 利用 Boostrap 方法(有放回抽样,步骤 2)选择 N 个 训练集 ;其次在每个训练集中随机选择 k 个特征,利用 公式(2)计算基尼指数,从而进行最优属性(特征) 选择(步骤 3) ;最后生成决策树。
通过算法 1 可得到随机森林的训练模型,测试样例 即可通过模型预测结果。训练集通过测试集得到的模型 进行最终的预测分类。在整个模型的建立过程中最重要 的步骤就是调参,随机森林方法的参数有很多个,不同 参数的组合方式可以使随机森林达到较好的分类效果。 如表 2 所示给出了随机森林的主要参数。
很明显, 从表 2 中还可以看出只有随机森林多个参 数取值最佳,才能得到较好的分类结果。由于在实际操作中,无法保证所选参数是否达到最佳。因此,本文提 出一种基于遗传算法优化随机森林参数的方法。通过遗 传算法找到随机森林树木数量和深度的最优值,分析统 计该方法的性能。
算法首先选择初始种群,种群是染色体组,染色体 代表子森林,每个染色体用二进制编码, 1 代表被选中 该树, 0 代表没有被选中该树。例如,染色体 Ci=[0.1.0. 1.0.1.0.1], 说明这 8 棵树中, 第 2.4.6.8 被选择作 为子森林。然后利用轮盘赌方法选择染色体 Cj (j ≠ i), 染色体 Cj 被选中的概率如式(7)所示 :
其中, E(Cj) 是染色体 Cj 的精度, |pop | 是种群数。
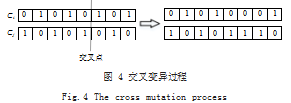
最后进行交叉变异操作,当染色体对在交叉点基因 交换后,将 1 转换为 0.将 0 转换为 1.具体如图 4 所示。
通过选择、交叉变异操作后生成的新种群如果没有 满足设定的种群数量时,则继续循环。直到满足终止条 件为止,输出最优解,也就是随机森林的参数、树木数 量和深度。
3 结语
本文首先对比总结了基于 SVM 及其优化的方法,特 别是考虑了遗传算法对 SVM 参数优化的影响 ;其次总结 了基于随机森林及其优化的方法。未来将计划在下一步 工作中利用数据,实现上述模型,为以后的研究做准备。
参考文献
[1] AGRAWAL R,SRIKANT R.Mining Sequential Patterns[J]. Proc.Int.Conf.on Data Engineering(ICDE ‘ 95),1996.96 (1057):3-14.
[2] 马骊.随机森林算法的优化改进研究[D].广州:暨南大学,2016.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/62921.html