SCI论文(www.lunwensci.com):
摘要:随着互联网和借贷业务的迅速发展,超前消费日趋常态化。银行信贷在满足居民消费需求、促进国民经济发展的同时,也伴随着失信行为带来的影响,给银行造成了巨大损失。借助机器学习技术建立有效的风险控制模型,做好风险防控,已成为业界的迫切需求。本文基于银行风险防控的需求,针对模型构建的需要,对相关数据集进行了统计分析和预处理,为提供模型构建所需的高质量数据样本做了前期准备。基于随机森林算法,利用集成思想的优势,建立了一种有效的风险控制模型。通过性能度量指标对模型进行评估和参数优化,并与决策树算法模型进行对比,根据最终的实验结果验证基于随机森林算法的银行风险控制模型的可行性和有效性。
关键词:银行风控;随机森林;贷款违约;风控模型
Research on Bank Risk Control Model Based on Random Forest Algorithm
YUAN Jing
(School of Electronic and Information Engineering,Tongji University,Shanghai 201804)
【Abstract】:With the rapid development of Internet and lending business,advanced consumption is becoming more and more normal.Bank credit not only meets the consumer demand and promotes the development of national economy,but also brings the influence of dishonesty,causing huge losses to banks.With the help of machine learning technology,it has become an urgent need of the industry to establish an effective risk control model and do a good job in risk prevention and control.Based on the needs of bank risk prevention and control,this paper makes statistical analysis and pretreatment of relevant data sets for the needs of model building,and makes preliminary preparations for providing high-quality data samples needed for model building.Based on the random forest algorithm,an effective risk control model is established by taking advantage of the integrated idea.The model is evaluated and optimized by performance metrics,and compared with the decision tree algorithm model.According to thefinal experimental results,the feasibility and effectiveness of the bank risk control model based on random forest algorithm are verified.
【Key words】:bank risk control;random forest;loan default;risk control model
1引言
1.1研究背景及意义
随着互联网的不断发展,金融机构信贷业务在国内正呈现出蓬勃发展的繁荣局面,信贷的准入门槛逐渐降低,防范重大金融风险被放在了重要位置。目前,随着银行账户数目的快速增加以及信贷欺诈技术日渐狡诈,银行风险控制模型在准确率和效率上的提高都迫在眉睫。风控的主要目的是降低风险发生概率,减少风险造成的损失。如何通过有效的模型建立,对用户未来的还款表现进行有效预测,同时预防欺诈风险,已成为风控建模的迫切需求。
1.2国内外研究现状
随着互联网金融的兴起,国内外高校、研究机构和金融领域都对银行风险管理体系进行了研究,这对银行风险控制模型和方法的研究提供了理论和技术支撑。2012年,Mandala对比了C5.0和CART决策树算法,得出了C5.0决策树算法可以降低贷款违约率、提高信用评估效果和风险控制表现的结论[1]。2014年,Fernandaze-Delgado对179种分类模型的性能在UCI的121个数据集上进行了测试,发现这些分类模型中随机森林模型和支持向量机模型在综合性能表现上较优[2]。从以上文献梳理可以看出,随着互联网的普及、数据的积累以及机器学习算法快速发展,基于机器学习算法的信用风险控制模型逐渐被行业认可和使用。2016年,温珂使用动态参数来对神经网络模型进行优化,从而对投资银行风险进行预测[3]。
2模型建立与实验
2.1数据预处理
实验使用的数据集为Kaggle平台贷款违约预测的公开数据集,共15万条用户贷款数据,保存为CSV格式的文件。其中每一条样本有12个变量:事件编号、贷款人年龄、家属数目、月收入、抵押贷款数量、信用贷款数量、实贷比率、负债比率、逾期2个月以内次数、逾期3个月以内次数、逾期3个月次数、贷款类别。在数据集15万条数据中,贷款类别为未违约的数据共139974条,占数据总数的93.316%;贷款类别为违约的数据共10026条,占数据总数的6.684%。
用箱型图观察分析属性值的分布情况,发现数据大都集中分布于一个范围内,但仍有少数极端值存在,且极端值偏离数据中心。为减小对模型构建的影响,将偏离数据中心的极端值视为异常样本。针对本数据集异常值的情况,采用将异常值视为缺失值的方法,与数据集中的缺失样本一同处理。
2.2模型设计与构建
本实验基于Python语言,使用Scikit-learn库、Pandas库等进行实验,构建随机森林模型预测贷款用户的违约风险,即对用户是否违约的二分类问题进行预测。实验把模型设计与构建过程分为了4个步骤:(1)选择、预处理数据集后,按照一定比例将数据集分为训练集和测试集,用于后续模型构建和评估。(2)确定初始参数取值构建随机森林模型,将训练集作为输入对模型进行训练。(3)选择指标对模型进行评估,并通过修改模型超参数值等的方法对模型进行优化。(4)将优化后的模型与初始随机森林模型、决策树模型进行比较,对比分析优化后的随机森林模型的有效性。
2.2.1划分数据集
初始数据集共15万条,其中违约样本共10026条。使用Sklearn库中的数据集划分函数StratifiedShuffle-Split,按照8:2的比例将数据集划分成训练集和测试集分别对模型进行训练与测试。训练集中共120000条样本数量,其中8020条为违约样本;测试集中共30000条样本数量,违约样本为2006条。
2.2.2模型构建
采用Sklearn中集成算法模块Ensemble的分类类RandomForestClassifier进行随机森林模型的构建。RandomForestClassifier类包含的参数可分为Bagging框架参数和决策树相关参数两种。初始模型的参数构建取值如表1所示。
2.3模型评估与优化
2.3.1模型评估
本文随机森林模型的评价指标以AUC值和F1-Score为主,同时计算召回率、精准率和准确率的值,从稳定性、泛化能力等方面对模型性能进行评判。统计结果如表2所示。
从表2可看出,随机森林模型的拟合能力很强,虽然有理论证明随机森林不易过拟合,但在未进行参数调整的情况下,模型的泛化能力较差。随机森林模型的超参有决策树个数n_estimators、分裂内部节点所需的最小样本数min_samples_split、叶子结点处所需的最小样本数min_samples_leaf等,通过探究超参数不同取值与性能指标的关系,选择合适的超参数值,提升模型性能。
2.3.2模型优化
(1)决策树个数n_estimators。判断n_estimators的不同取值与随机森林模型的F1-Score、AUC值的关系,确定更适合数据集、性能更好的模型结构。在min_ samples_split为2、min_samples_leaf为10的条件下,对n_estimators取值:10、50、100、200、300、400、500、600、700、800、900,分别在不同取值下运行模型。实验结果表明,随着n_estimator数值的增加,模型的F1-Score与AUC值都大致呈增加趋势,在决策树个数n_estimator为500时,模型的F1-Score与AUC值取最大值,即此时模型性能表现最优。
(2)分裂内部节点所需的最小样本数min_samples_ split。根据上述调参过程,给定n_estimators为500、min_samples_leaf为10,对min_samples_split取值:2、5、10、15、20、25、30,在不同取值下运行模型。随着min_samples_split数值的增加,模型的F1-Score值大致呈现先增加后减小的趋势,在min_samples_ split=10时取得最大值;随着min_samples_split数值的增加,模型的AUC值大致呈现先增加后减小再增加的趋势,在min_samples_split=10时取得最大值。则选择10作为优化后的min_samples_split参数值。
(3)叶子结点处所需的最小样本数min_samples_ leaf。由(1)、(2)得,给定n_estimators为500、min_ samples_split为10,对min_samples_leaf取值:1、5、10、15、20、25、30、35、40,在不同取值下运行模型。随着min_samples_leaf数值的增加,模型训练集的F1-Score与AUC值都呈下降趋势;测试集的F1-Score呈现先上升后缓慢下降的趋势,AUC值呈缓慢上升趋势。min_samples_leaf从默认值1开始运行时,出现了过拟合的现象。综合F1-Score与AUC值,在不出现过拟合且性能指标尽可能高的情况下,选择20作为优化后的min_samples_leaf参数值。
综合上述过程,最终对模型调优后的结果为:n_ estimators=500,min_samples_split=10,min_ samples_leaf=20。
2.4模型对比
根据上述实验和模型优化,使用此参数集合的随机森林模型对测试集数据进行预测,得到F1-Score和AUC值,并与使用决策树算法进行预测得到的评估指标进行对比。使用决策树模型,在本实验所用贷款违约数据集上进行训练,在测试集上得到分类的评估指标。决策树模型和优化后随机森林算法模型的各评价指标值如表3所示。
表3两种模型的性能指标对比列表
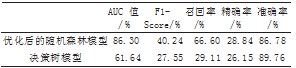
由表3中的指标数据可以看出,优化后的随机森林模型AUC值、F1-Score值和召回率三个评价指标的值都远高于决策树模型。召回率越高,表示违约的样本被预测出来的概率越高;在数据集样本不平衡的情况下,准确率这一评价指标的评价结果需斟酌看待。可得出结论,在实验数据集存在不平衡情况时,随机森林模型的性能更加优秀。
针对本实验使用的数据集,随机森林模型不仅召回率远高于其他二者,F1-Score和AUC值也是三者中最高,即随机森林模型的性能指标比基于逻辑回归和决策树算法的模型优秀。随机森林模型与另外两种模型相比,在处理较大数据集时表现优异,且不依赖于单一决策树,通过集成多棵决策树的优势,使其评价指标更高。综合来看,本实验数据集下,基于随机森林算法的风险控制模型在AUC值、F1-Score值和召回率等指标上均有突破,与决策树模型相比性能更佳。
3结语
随着互联网和贷款业务的迅速发展,风险控制的重要性日益突出。针对银行风险控制的业务需求,使用Kaggle数据集,选择随机森林算法为主要的建模方法,对贷款交易数据进行模型构建和特征重要性度量。借助模型性能度量指标,对模型进行了评估和调参优化,最终实现能有效识别贷款违约用户的银行风险控制模型。通过与决策树模型性能度量指标的评估对比,证明了随机森林模型的预测能力。在之后的研究中,将会尝试更多的机器学习算法进行模型建立,例如集成学习。组合单一的算法模型,考虑并行,以实现更好的预测效果。
参考文献
[1]Mandala I,CB Nawangpalupi,Praktikto F R.Assessing Credit Risk:An Application of Data Mining in a Rural Bank[J].Procedia Economics and Finance,2012,4(29):406-412.
[2]Fernandez-Delgado M,Cernadas E,Barro S,et al.Do we Need Hundreds of Classifiers to Solve Real World Classification Problems?[J].Journal of Machine Learning Research,2014(15):3133-3181.
[3]丁德臣.集成随机森林和支持向量机的商业银行财务困境预测研究[J].数学的实践与认识,2020,50(2):292-302.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/39998.html