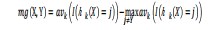SCI论文(www.lunwensci.com):
摘要:在大数据、大信息环境下,“信息”和“数据”随处可见,获取信息和数据的渠道也多种多样。如何有效快捷地分析和处理这些庞大的信息和数据,是人们长期以来讨论的热点话题。在数据处理过程中,应用最广泛、最有效的是分类方法,而将多个分类器集成来进行预测便是集成学习算法。随机森林算法是这种个多分类器组合的分类方法之一。本文先对随机森林算法进行概述,再讲述其演绎过程及这种思想的来源和思想构成原理,分析其特点和优势,探讨算法改进方法,希望能够推动相关理论的进一步发展。
关键字:分类回归;随机森林算法;研究分析
Research and analysis of random forest algorithm
Wen Yang1,liumeiqi2
(1.Chengdu QiGeng Technology Co.,Ltd.,Chengdu Sichuan,610000;2.Sichuan Tianao Aerospace Information Technology Co.,Ltd.,Chengdu Sichuan,610094)
Abstract:In the big data and big information environment,there are"information"and"data"everywhere.At the same time,it is easy to obtain information and data.How to deal with and analyze these huge amounts of information and data effectively and quickly has been a hot topic for a long time.In the process of data processing,the most widely used and effective method is the classification method,and integrating multiple classifiers to predict is the integrated learning algorithm.The random forest algorithm is one of the classification methods of this combination of multiple classifiers.This paperfirst introduces the random forest algorithm,then describes its deductive process,the source of this idea and its composition principle,analyzes its characteristics and advantages,and discusses the algorithm improvement methods,hoping to promote the further development of related theories.
Keywords:classified regression;random forest algorithm;research analysis
在数据处理环节中,虽然存在很多方法,但应用最广泛、最有效的是分类方法。而分类器是数据挖掘中对样本进行分类的方法的总称,用户将需要分析分类的数据通过这个分类器进行处理,就能得到该分类器预测的分类结果。分类技术有单分类器和多分类器技术之分,主要由分类器的个数决定。单分类器虽然推动了分类技术的发展,甚至一时达到了巅峰,但是由于其自身的缺陷,很快便碰到了瓶颈。基于此,多分类器组合思想应运而生。本文围绕随机森林算法,分析其特点和优势[1]。
一、随机森林理论概述
随机森林在数学上的定义是由h1(x),h2(x),……hk(x)构成的随机森林[1]。
其边际函数定义:
边际函数表示的意思是,在正确分类的情况下,得到的票数比在不正确分类的情况下得到的票数多的函数表现,显然,函数越大,原分类器分类效果越可靠。
二、随机森林性能指标
(一)分类效果系列指标
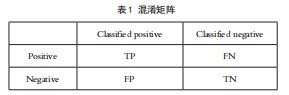
众所周知,森林算法主要用来进类预测,那么,分类预测效果自然有对应指标进行衡量。下面介绍一下二分类混淆矩阵[2]。如表1所示。
上表为二分类混淆矩阵,假设有正分类和负分类两种分类,如上表列向显示,TP、TN表示正确分类的正负类样本数,FN、FP表示错误分类的正负类样本数。
(二)泛化误差与OOB估计
1.泛化能力与泛化误差
机器学习分析数据背后的规律,依照这些规律得出分类预测结果,对数据集以外但有着同样规律的数据进行分析,也能得出一定的结果。这种举一反三的能力即为泛化能力[3]。分析模型常用于简单线性问题的误差估计,而交叉验证是将样本划分为训练集和验证集,因为验证集输出已经给出,所以可以计算其分化误差[4]。
泛化误差定义:
代表概率定义空间。
2.OOB估计
随机森林采用bagging方法训练,而这种训练方式会有一1-1MM部分数据不被抽取,这些不被抽取的数据个数约为。若M很大,其值约为1/e,即0.368,这些数据被称为OBB数据。对于没有被抽取的数据,利用这些数据进行估计的方法称为OOB估计。OOB数据不仅能估计误差,还能计算强度与相关系数,从而保证分类结果的准确性。
(三)随机森林算法运行效率指标
任何算法的可行性都要考虑其运行效率,即需要考虑算法运行时的执行量和工作量,以及占用多少计算机资源。因此,时间复杂度和空间复杂度成为必须考虑的影响算法运行效率的两大因素[5]。
1.时间复杂度
时间复杂度,简单来说就是计算机执行指令需要的工作量和时间。若直接计算算法执行多长时间往往比较困难,这时,则可以引入时间复杂度的概念来描述算法执行快慢。时间复杂度可通过代码中指令条数、循环次数及语句重复次数计算得出。从理论上说,指令越多,重复执行的次数越多,需要的运行时间越长。
2.空间复杂度
空间复杂度,简单来说就是该算法占用计算机内存空间的大小。指标可以估计算法在运行过程中需要占用多大的计算机内存来执行算法。技术人员既需要处理程序本身的变量,又需要在CPU与主存之间留存一些虚拟存储空间来提供算法需要变量的存储空间。
三、随机森林的构建过程
(一)训练集的生成
每棵决策树都有自己的训练集,构建N棵决策树,就对应着N个训练集,从原始训练集到N个子训练集可以采用抽样的方法,包括不放回抽样和有放回抽样。
不放回抽样的意思是从多个容量为M的个体中不放回地抽取一定数量为m的样本。简单随机抽样时,在每次不放回抽样的过程中,每个个体被抽取的概率是相等的。
有放回抽样,顾名思义是在每次抽取完样本时,将样本再放回训练集,这样每次抽样不会减少数据集,且生成的样本可能重复。
大多数随机森林都是采用有放回抽样的方法,该方法生成训练集样本的数量约为原始训练集样本数量的2/3,且样本有重复,这能避免单决策树非全局最优解的问题,从而提高整体性能水平。
(二)森林的形成
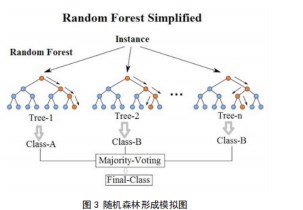
在之前的基础上,反复测试训练生成多棵决策树,并在每棵决策树上对预测样本进行训练分类,最终结果由所有决策树投票产生。所有决策树需先对样本进行分类,再对每棵决策树的结果进行汇总分析,最后选出票数最多的结果作为最终输出[6]。
随机森林形成如图3所示。
(三)随机森林的构成
在样本的众多特征中,算法可限制其中一些样本,利用其余样本来训练生成决策树。树上的分裂点可通过贪婪算法进行分析和评估。和之前的方法一样,随机森林是通过抽取复合样本进行演算,但与之前的区别在于数据在分裂时会完全分裂融入树中,且用一个固定的子集样本储存在树中。
四、随机森林算法应用场合
受分类预测的有效性和可行性影响,随机森林算法在多数领域得到了广泛应用,其可以对数据进行处理和分析,并合理预测其他类似的样本。
(一)预测能力
随机森林算法能对已有样本进行训练,总结一定规律,进而获得相似样本的预测能力。比如,对沉船事件的生还几率进行预测。
在这个交通便利的社会,意外每天都在发生,如何在意外发生的第一时间,对生还者进行预测,然后及时抢救,是关键的一步。如果相关部门不能第一时间准确预测生还者数量及状态,不仅会导致抢救行动效率降低,还会导致生还者数量减少。为避免这一情况,相关部门可利用随机森林算法的预测算法,在事件中快速预测生还者的状况,以及准确定位生还者的位置,从而及时进行抢救。
(二)分类能力
随机森林在样本训练的同时,可根据选取目标的不同特征将样本分成不同子集,再根据这些特征对一个新事物进行分类。
例如,对一群动物进行分类时,可根据“生活区域”“繁殖方式”“生活习性”“样貌特征”等属性进行分类,最后得到该生物种类的相关属性。利用随机森林算法进行分类,能提升分类的准确率,快速识别该动物的物种,且可靠性和可行性更强。
五、总结
当下,随机森林算法是一种非常实用且应用十分广泛的算法,虽然复杂度较高,但其大幅度优化了单个分类器的性能,能通过组合多个分类实现分类预测,预测结果更加准确、高效,因此在实际生活中得到了广泛应用。该算法因其简单高效、快捷方便的特质,在生物信息、物流信息、经济社会、计算机等领域获得了巨大成就。
【参考文献】
[1]文耀宽,王献军,王峻,等.基于随机森林算法的电力计量大数据分析平台研究[J].计算机技术与发展,2021(6).
[2]蒲东川,王桂周,张兆明,等.基于独立成分分析和随机森林算法的城镇用地提取研究[J].地球信息科学学报,2020(8).
[3]刘勇,兴艳云.基于改进随机森林算法的文本分类研究与应用[J].计算机系统应用,2019(5).
[4]庄巧蕙.基于改进随机森林算法的研究与应用[D].泉州:华侨大学,2019.
[5]贾文超,戚兰兰,施凡,等.采用随机森林改进算法的WebShell检测方法[J].计算机应用研究,2018(5).
[6]李扬,祁乐,聂佩芸.大规模数据的随机森林算法[J].统计与信息论坛,2020(6).
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/43628.html