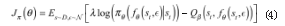SCI论文(www.lunwensci.com)
摘 要: 【目的】针对多智能体强化学习过程中样本利用率低、奖励稀疏、收敛速度慢等问题,提出了一种基于后验经验 回放的 MAAC(Actor-Attention-Critic for Multi-Agent Reinforcement Learning, MAAC) 多智能体强化学习(Hindsight Experience Replay Machanism of MAAC Algorithm, HER-MAAC)算法。【方法】利用失败的探索经验,将依据后验经验 回放算法选取的目标重新计算奖励值, 存入回放缓冲区中, 增大回放缓冲区中成功经验的比例, 从而提升样本抽取效率。【结 果】实验结果显示, HER-MAAC 相较原始 MAAC 算法,智能体成功率提升,奖励值也明显提高。在典型试验环境下,训练 3 个智能体胜率提高了 7.3%,智能体数量为 4 时胜率提高 8.1%,智能体数目为 5 时胜率提高 5.7%。【结论】研究成果表明,改 进后的算法能够有效提升多智能体训练效率。
关键词:多智能体系统,深度强化学习,后验经验回放,注意力机制
Hindsight Experience Replay Machanism of MAAC Algorithm
XIA Lin, LUO Wei, WANG Junxia, HUANG Yixue
(China Ship Development and Design Center, Wuhan Hubei 430000)
【Abstract】: [Objective] In this paper, aiming at the problems of sparse rewards and slow convergence in the process of multi-agent reinforcement learning, an algorithm named HER-MAAC which combined MAAC with hindsight experience replay is proposed. [Methods] Recalculate the reward value of the target selected according to the hindsight experience replay algorithm and store it in the replay buffer, so as to improve the efficiency of sample extraction. [Results]Experimental results show that compared with the original MAAC algorithm, HER-MAAC improves the success rate of agents and the rewards. In the typical experimental environment grid environment, 3、 4 and 5 agents were trained, and the winning rate increased by 7.3%、8.1% and 5.7% respectively. [Conclusion] The research results show that the improved algorithm can effectively improve the efficiency of multi-agent training.
【Key words】:multi-agent system;deep reinforcement learning;hindsight experience replay;attention machanis
0 引言
深度强化学习在路径规划、能源调度、无人机集群 以及机器人领域等处理连续复杂任务的场景中都展现了 良好的性能。2014 年,Facebook 基于深度学习技术的 DeepFace 项目,在人脸识别方面的准确率已经达到了 97% 以上。2016 年 3 月— 2017 年 5 月,DeepMind 开发 的 AlphaGo 围棋算法机器人将蒙特卡罗树搜索与价值和 策略网络相结合,后使用了强化学习进行自我博弈,结合使用了深度学习、监督学习、增强学习等方法 [1],陆 续战胜了多位围棋高手,标志着人工智能具备很好的表 现潜力。深度强化学习是机器学习的一个子领域,具有 实现通用人工智能的潜力。
目前多数强化学习算法集中研究处在稳定环境的单 智能体,而对于多智能体的算法研究进展较慢。主要原 因在于多智能体强化学习中环境是动态变化的,多个智 能体相互作用、相互影响,导致奖励值稀疏,算法训练难以收敛。在单智能体强化学习中,需要存储状态值函 数或动作—状态值函数。在多智能体强化学习中,状态 空间变大,联结动作空间(联结动作是指每个智能体当 前动作组合而成的多智能体系统当前时刻的动作)随智能 体数量指数增长,因此多智能体系统维度大,计算复杂。
关于多智能体的算法目前可分为以下几种 :(1)行 为分析类是指将单智能体强化学习算法(SARL) 直接 应用到多智能体环境(MARL)之中,每个智能体之间 相互独立。2017 年,Ardi 等人结合 DQN 算法与 IQL 算法 [2],通过在 Pong 游戏中的实验表明 DQN 算法在 高度复杂的多智能体环境中也有比较好的性能,而这类 算法忽视了智能体之间的相互影响。(2)通信学习类的 多智能体强化学习方法在训练过程中学习如何与其他智 能体通信,在决策时需要考虑其余智能体传递的信息。 2016 年, Jacob 等人首次在多智能体深度强化学习中引 入通信学习,提出了 RIAL 和 DIAL 算法 [3]。前者使用 DQN,后者利用智能体在学习过程中可以通过通信信道 反向传播错误参数的特点,中心化训练去中心化执行。 2017 年, Peng 等人引入了一个多智能体双向协调网络 (BiCNet), 并对 Actor-Critic 公式进行了矢量化扩展 [4]。 通过分析表明, BiCNet 可以学习经验丰富的游戏玩家 常用的各种高级协调策略,在实验中显示了优秀的性能。 (3)协作学习类算法将多智能体领域的一些思想引入到 MARL 中 [5]。2017 年,Ryan 等人提 出 的 MADDPG 算 法将 DDPG 算法扩展到多智能体环境中,提出了集中训 练、分散执行(Centralized Training Decentralized Execution,CTDE) 框架 [6],能够成功地学习需要复 杂多智能体协调的行动策略。2019 年,Shariq 等人提 出了 MAAC 算法,遵循 CTDE 框架,通过共享参数的 注意力机制来计算 Critic 网络 [7],这种机制可以在复杂 的多智能体环境中实现更有效的学习。
稀疏奖赏、样本利用率低是强化学习应用中的经典 难题。2015 年, Schaul 等人提出了一种优先级经验回 放(Prioritized Experience Replay,PER) [8],按经验重 要性增大其被采样到的概率,从而增加学习效率。文章中 将 PER 结合 DQN 算法训练 Atari 游戏,在 57 个游戏中 有 42 个表现优于单独使用 DQN 算法,而将经验按重要 性排列会耗费大量的系统资源。2017 年,Andrychowicz 等人提出了事后经验回放算法(Hindsight Experience Replay,HER) [9],使智能体在完成任务后具有自我审 视的能力,将预先设定的目标更改为每一次失败的尝试 达到的状态, 从而从错误的经验中学习。HER 算法可 以结合任何 Off-Policy 的强化学习算法使用,通过实验证明结合 HER 算法使 DDPG 算法效果有明显提升。
多智能体环境因其维度空间大,奖励稀疏问题更为 明显, 收敛困难。PPER-MADDPG 算法 [10] 将 PER 机制 融入 MADDPG 算法,使得在多智能体系统中经验数据 利用率提高,算法性能得到显著提升。然而, MADDPG 算法的可扩展性差,训练速度慢。MAAC 算法引入注 意力机制和熵最大化算法来解决这些问题。PEMAC 算 法 [11] 将优先经验回放引入多智能体与 MAAC 算法结 合,对训练经验按优先级标记,并采样优先级较高的经 验更新网络。而在多智能体系统中将经验数据按重要性 标记优先级会造成更大量的系统资源消耗。因此,将后 验经验回放应用在多智能体是解决这一问题的新尝试。
针对以上问题,本文将后验经验回放(HER)思想 引入 MAAC 算法。MAAC 算法引入注意力机制,在智 能体数目增大时可扩展性更好。事后经验回放通过将既 定目标更改为当前智能体达到的状态获得更密集的奖励 函数,可以加速算法收敛。研究将算法在多智能体仿真 平台应用,通过智能体表现评估算法的有效性。
1 背景知识
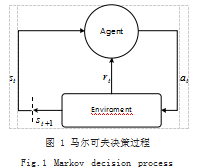
1.1 马尔可夫决策过程
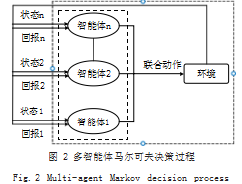
在强化学习过程中,智能体与环境不断交互, 通过 探索、试错学习决策,指导智能体执行奖励值较大的动 作,以使智能体在一轮游戏结束后获得最大奖赏。强化 学习中智能体与整个环境的交互过程也叫做马尔可夫决 策过程,如图 1 所示 :t 时刻,智能体在环境中处于状 态 st ,然后通过学习到的策略选取动作 at 作用于环境, 环境接受该动作后发生状态转移得到 st+1.同时反馈给 智能体执行该动作获得的奖励 rt ,智能体不断重复这一 过程,进而最大化自己的累积回报。相似地, 在多智能体强化学习中,环境中的智能体 也都遵循多智能体马尔可夫决策过程,如图 2 所示。环 境中的每个智能体得到各自的局部观测 o=(o1.… ,oN), 根据学习到的策略选择动作 a=(a1.… ,aN),以联合动作 的形式作用在环境中,接下来环境给出反馈,包含联合奖励 r=(r1.… ,rN) 以及下一时刻的整体状态,每个智能 体从中得到各自的私有状态观测值和私有奖励值。
1.2 SAC 算法
SAC 不同于传统以最大化智能体回报为目标的传统 算法, SAC 同时最大化智能体回报和动作的熵值。在 策略函数和价值函数中最大熵具有不同的作用,在策略 函数中,它可以防止智能体的策略过早收敛于局部最优 解。在价值函数中,增加智能体动作的熵 [12],可以鼓 励智能体探索,使得算法更加稳定。最大化熵值算法 SAC 的优化目标如式 (1) 所示 :
J (π ) =E(st ,at )~ ρπ ■r (st , at ) + λΗ (π ( · st ))■
其中, E 为数学期望, T 为智能体每轮与环境交互 的总时间步数, st,at 分别为 t 时刻智能体的状态和动作, ρπ 是策略 π 下轨迹 (st,at) 的分布, r(st,at) 为智能体在状 态 st 执行动作 at 获得的奖励。H( · ) 用于计算策略 π 的 熵值, λ 是正则化系数, 用于控制更关注熵或奖励值。 策略函数 πθ 可以通过最小化以下的 KL 散度得到如式 (2) 所示 :
Jπ (θ) = Est ~D ,at ~πθ ■λlog (πθ (atst )) − Qβ (st , at )■ (2)
st,at 分别为 t 时刻智能体的状态和动作, θ 为智能体 Actor 网络 πθ 的参数, β 为 Critic 网络 Qβ 的参数, D 为存储训练样本的经验回放池, Jπ (θ) 中的期望也依赖于 策略 πθ。用策略网络的重参数化来优化 Jπ (θ), 将 πθ 表 示为一个使用状态 s 和标准正态样本 ϵ 作为其输入的函 数直接输出动作 a[13] 如式 (3) 所示 :
代入式(2),得到如式 (4) 所示 :
随机噪声 ϵ 服从标准正态分布。
1.3 MAAC 算法
MAAC 算法将单智能体深度强化学习算法 SAC 采用 CTDE 框架进行拓展,在训练 Critic 网络时考虑来 自其他智能体的观察和动作作为额外信息 [14],在执行 时 Actor 网络只使用智能体的私有观察进行决策 [15]。 在 Actor 网络以及 Critic 网络中引入 SAC 算法思想中 的交叉熵的概念,促进智能体对环境进行充分的探索, 能够更有效地利用环境中的信息学习。
在真实世界中的多智能体对其他智能体的注意力分 配比例存在不同,受到这一思想的启发, MAAC 算法 将注意力机制引入到多智能体强化学习算法中。通过 选择性地关注来自其他智能体的信息来学习每个智能体 的 Critic 网络。注意力机制使智能体动态地选取周边信 息,改善了智能体在复杂环境中的合作性能,可扩展到 高度复杂和动态的环境。
1.4 后验经验回放
强化学习中智能体获得的奖励稀疏严重影响了算法的 学习速度和性能,而人类即使在失败的经验中也可以学习 到有用的知识, 后验经验回放算法(HindsightExperience Replay,HER) [9] 受到这一思想的启发,提出一种通过修 改目标为当前智能体状态来增大有价值经验比例的方法。 HER 算法在每一轮的训练序列中附加了初始目标g 与智能体状态s 对应,并且将该序列stg, at , rt ,st+1g存储在回放缓冲区中。HER 提出了 4 种采样新目标的策略 :(1) Final :取 最 后 1 个 State 作 为 新 目标 ;(2)Future : 回放该回合中,从现在开始 k 个随机状态作为新目标 ;
(3)Episode :回放当前回合中 k 个随机状态作为新目 标 ;(4)Random :回放至今为止 k 个随机状态作为新 目标。通过实验验证,策略 Future 效果优于其他 3 种 策略。HER 在每一轮结束后依据选定的策略 S 取样新 目标,将每个新目标 g' 重新计算奖励值 r',并且将得到 的序列stg′, at , rt′, st +1g′存入经验池。用后验经验来降低奖励的稀疏程度,采样经验池中 Transition 训练 算法,能有效提升算法性能,加快收敛速度。
2 基于后验经验回放的 MAAC 算法
HER 算法应用在单智能体环境中可使算法效果获 得显著提升,由此启发将其扩展到多智能体环境中,与 可扩展性强、收敛速度快的 MAAC 算法结合,提出了 基于后验经验回放的 MAAC 算法。该算法通过注意力 机制使智能体对其余智能体的信息有选择地关注,依此 来做出决策。并将依据 HER 策略选取的目标重新计算 奖励值并存储到回放缓冲区(Replay Buffer),利用经 验训练 Actor 和 Critic 网络。
在经验存储和采样阶段,智能体在 t 时刻的初始状态 为 ot=(o1t,…,oNt), oit 表示智能体 i 在 t 时刻的观测值,整体目标状态为g=(g1.…,gN),其中智能体 i 从依据局部观测和目标状态gi 更新的策略 πθi 选取动作 at=(a1t,…,aNt), 其 中ai(t) = πθi (oi(t)gi ),执行动作后得到奖励值 rt=(r1t,… ,rNt)并且得到下一时刻的观测状态 ot+1=(o1t+1.… ,oNt+1), 将Transition (otg , at ,rt , ot+1g)存储在回放缓冲区D 中。接下来,选取该回合中从当前状态开始 k 个随机状态作为新目标g'=(g'1.…,g'N),计算奖励值得到 r't=(r'1t,…,r'Nt), 将修改新目标得到的 Transition (otg′ , at , rt′, ot+1g′)存储在回放缓冲区 D 中,经验存储和回放过程如图 3 所示。
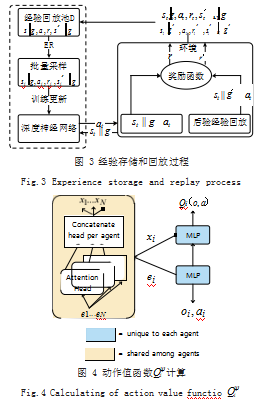
该算法引入 Attention 机制, 对动作值函数Qi(ψ)进行改 进,计算方式如图 4 所示。Critic 网络的输入是所有智能体的观测信息 o=(o1.… ,oN) 和动作信息 a=(a1.… ,aN), 并定义所有智能体的索引 i ∈ {1.… ,N},如式 (5) 所示 :
Qi(ψ) (o, a )= fi (gi (oi , ai ), xi ) (5)
其中fi 是一个双层 MLP 网络,而 gi 是一个单层 MLP 嵌入式网络函数 [7], xi 是其他智能体对智能体 i 所得奖励的贡献大小的加权和,定义为如式 (6) 所示 :
xi =αj vj =αj h (Vgi (oj , aj )) (6)
其中, vj 是智能体j 的嵌入式编码函数 ej=gj (oj,aj) 通 过一个线性的共享矩阵 V 变换,再由一个元素之间的非 线性变换函数 h 处理得到。
Attention 权重 aj 是通过使用双线性映射,即查询 值―键值系统,比较 ej 与 ei=gi (oi,ai),并将二者的相似值传递给 Softmax 网络处理得到如式 (7) 所示 :
αj ∝ exp(ej(T)WkT Wq ei ) (7)
其中,线性转换矩阵 Wq 将 ei 转化为查询值, Wk 将 ej 转化成键值,然后根据这两个矩阵的维数进行匹配, 防止梯度消失。该算法使用了多 Attention Heads。每 个 Head 使用一套独立的参数(Wk , Wq , V),从而实现从不同角度关注其他智能体的权重贡献和如图 4 所示 的计算方式 [16]。
通过后验经验回放利用历史经验降低 Critic 网络的
损失值LQi (ψ )如式 (8)、式 (9) 所示 :
LQi (ψ ) =E(o,a ,r ,o′,g )~D(Qi(ψ) (o, a )− yi )2(8)
yi = ri +γEa′~πθ (o′) ■Qi(ψ) (o′, a′)− λlog (πθi (ai′ oi′ ))■ (9)
其中y 值的计算融入了 SAC 算法中熵最大化的思想, ψ 和θ为目标 Critic 网络和目标策略参数, λ 为温度 参数,用于控制更关注熵最大化或奖励值最大, Jπ (θ) 中 的期望可以通过在经验回放池 D 中取出样本 ot 进行近似计算。策略网络的表达式如式 (10) 所示 :
∇θi J (πθ )= Eo~D ,a~π ■∇θi log (πθi (aioi )) ( −α log (πθi (aioi ))+ Qi(ψ) (o, a )− b (o, a\i ))■ (10) 其中b (o, a\i)是 MAAC 算法用于解决信度分配的反事实基线。
算法流程如下 :
Step 1 :初始化 Replay Buffer 经验回放池 D,初 始化 HER 算法目标更新策略 S ;
Step 2 :对 episode=1.…,M 执行以下循环 :
(1)初始化所有智能体的环境和状态集合 s ;
(2) 对 t=1 到最大的时间步长以及环境中的每个智 能体 i 执行以下循环 :
1)智能体 i 依据当前决策策略πθi 选择动作 :ai ; 2)同时执行每个智能体的动作得到下一个状态 s' 以及整体瞬时回报 r ;
3)将训练经验 (sg , a, r, s′ g)存入 D ;
4)依据策略 S 选择目标 g',计算瞬时回报 ;
5)将训练经验(sg′, a, r′, s′ g′)存入 D ;
6)对每个智能体 i=1.… ,N,执行以下循环 :
①从 D 中随机抽取 Minibatch ;
②计算期望回报 ;
③最小化损失函数更新 Critic 网络 ;
④利用梯度下降法更新 Actor 网络 ;
⑤更新每个智能体 i 的目标网络参数。 7)结束循环。
(3)结束循环。
Step 3 :结束循环。
3 实验
3.1 实验环境
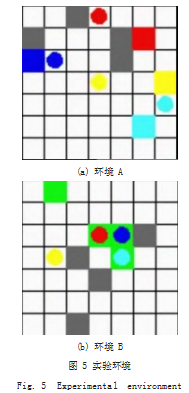
为评价 HER-MAAC 算法在多智能体环境中的表现, 本研究使用 Gridworld 环境进行仿真实验。Gridworld 是 OpenAI 开源的多智能体学习环境,在多种强化学 习算法文献中用作训练环境。Gridworld 环境简约,力 求最大程度地减少软件依赖性,易于扩展并能提供良好 的性能,从而加快学习速度。用户可以自定义格子的大 小、水平和垂直格子数目、内部障碍分布以及每一个格 子的即时奖励值。智能体的最终目标就是在到达指定位 置的同时,获得最大的奖励值。本文中实验设置了两种 环境,其中的智能体均为协作关系。
(1)环境 A 中不同颜色的球表示不同的智能体,灰 色格子表示障碍物,白色格子表示空地,其他颜色格子表 示对应颜色智能体的目标位置,如图 5(a) 所示。每个智 能体要在尽量少的步数内到达目标位置,并且避免碰撞。
(2) 环境 B 中所有的绿色格子为目标位置,环境中 的每个智能体只需要分别移动到一个绿色格子位置即为实现目标,如图 5(b) 所示。智能体之间相互通信、相 互协调,尽可能在总体步数最少、奖励值最大的情况下 到达目标点。
3.2 实验设置
本文在环境 A 实验中设置大小为 7×7 的格子空间, 4 个障碍物,为了验证随着智能体数目增多算法的有效 性,分别设置了 3 个、4 个、5 个智能体,通过算法的 表现进行对比。智能体每走一步奖励值 -0.1.与障碍物 碰撞奖励值 -0.02.与其他智能体碰撞奖励值 -0.2.到 达目标位置奖励值为 0.3.
对于环境 B,本文设置了 4 个智能体,对应 4 个相 同的目标位置以及 4 个障碍物。惩罚奖励规则与环境 A 相同。每个智能体要在避免相互碰撞和障碍物碰撞的同 时相互配合占据其中一个目标位置。
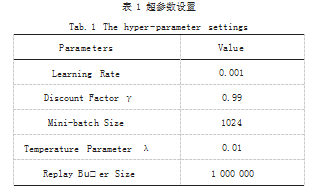
为避免实验结果的偶然性,本文中每次实验都运行 5 次,取平均值进行比较。训练超参数设置如表 1 所示。
3.3 实验结果
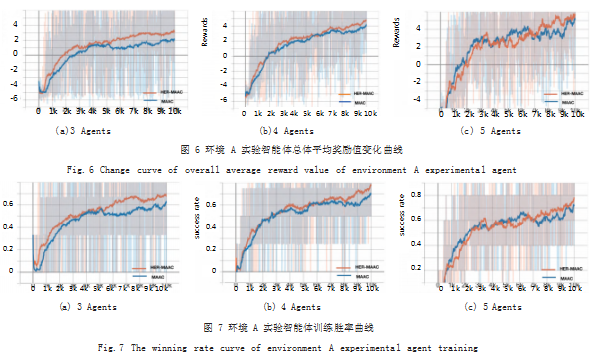
为了验证融入后验经验回放对 MAAC 算法效果有 改善,本文将 HER-MAAC 算法与 MAAC 算法进行对 比实验。将所有实验的 5 次平均奖励值范围(未经平滑 处理)统计如表 2 所示。如图 6(a)、图 6(b)、图 6(c) 所 示分别展示了在环境 A 中, 3 个、4 个、5 个智能体使用 MAAC 和 HER-MAAC 算法训练的奖励值结果趋势。通过对环境 A 中不同数目的智能体进行测试,从 算法奖励值和最终成功率均可以看出融入了后验经验回 放的 MAAC 算法对原 MAAC 算法有明显提升。在智能体数目为 3 时,使用 HER-MAAC 算法的奖励值是 MAAC 算法的 1.46 倍,胜率提高了 7.3% ;智能体数 目为 4 时,HER-MAAC 奖励值是 MAAC 算法的 1.17 倍, 胜率提高 8.1% ;智能体数目为 5 时,HER-MAAC 奖励值为 MAAC 算法的 1.21 倍,胜率提高 5.7%。实 验结果表明,在智能体数目增多时, HER-MAAC 算法 仍然表现优异,具有比 MAAC 算法更好的性能。
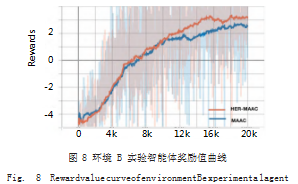
在环境 B 中,设置 4 个智能体, 4 个障碍物,对其训 练 20000 轮,得到奖励值变化曲线如图 7 所示。从图 7 中可以看出,在不同的任务环境中, HER-MAAC 算法 表现均优于 MAAC 算法,表明利用后验经验回放能够 使智能体从回放缓冲区中抽取更有用的经验元组训练。
通过以上实验得出结论, HER-MAAC 算法在智能 体数目较少时性能最好,而随着智能体数目增多,算法 效果仍优于 MAAC 算法,可扩展性更好。随着训练轮 数增加,累积经验增多, HER-MAAC 算法的表现也更 稳定,如图 8 所示。
4 结论
本文针对多智能体强化学习中的可扩展性差、收敛 速度慢、经验利用率低的问题,提出了将后验经验回 放机制融合 MAAC 算法尝试解决以上问题。通过在多 智能体训练环境进行实验测试算法效果,验证了 HER- MAAC 算法的性能在原 MAAC 算法基础上有明显提 升。在环境 A 中分别训练 3 个、4 个、5 个智能体,胜 率分别提高了 7.3%、8.1%、5.7%, 奖励值分别提升0.46 倍、0.17 倍、0.21 倍 ;在环境 B 中训练 3 个智能 体奖励值提升 0.23 倍。在后续研究中,会在更结合实 际情况的仿真场景中训练多智能体,结合相关规则,提 升算法效率。
参考文献
[1] SILVER D,HUANG A,MADDISON C J,et al.Mastering the game of Go with deep neural networks and tree search[J].Nature,2016.529(7587):484-489.
[2] ARDI T,TAMBET M,DORIAN K,et al.Multiagent Cooperation and Competition with Deep Reinforcement Learning[J].Plos One,2017.12(4):e0172395.
[3] FOERSTER J N,ASSAEL Y M,FREITAS N D,et al.Learning to Communicate with Deep Multi-agent ReinforcementLearning[C]//Annual Conference on Neural InformationProcessing Systems,2016:1425-2162.
[4] PENG P,WEN Y,YANG Y,et al.Multiagent Bidirectionally- coordinated Nets for Learning to Play Starcraft Combat Games[J].2017.9(14).
[5] 王全武,胡晓辉.动态环境下多智能体协作学习方法的研究 [J].科技创新导报,2011(9):253-254.
[6] LOWE R,WU Y,TAMAR A,et al.Multi-agent Actor-critic for Mixed Cooperative-competitive Environments[C]//31st Conference on Neural Informaton Processing Systems (NIPS 2017),Long Beach,CA,USA,2017.
[7] Iqbal Shariq,Fei Sha.Actor-Attention-Critic for Multi-Agent Reinforcement Learning[C]//International Conference on Machine Learning,2019:4957-5680.
[8] SCHAUL T,QUAN J,ANTONOGLOU I,et al.Prioritized Experience Replay[C]//ICLR,2016.
[9] ANDRYCHOWICZ M,WOLSKI F,RAY A,et al.HindsightExperience Replay[J].Advances in Neural InformationProcessing Systems,2018.
[10] 高昂,董志明,李亮,等.MADDPG算法并行优先经验回放机 制[J].系统工程与电子技术,2021.43(2):420-433.
[11] 黄子蓉,甯彦淞,王莉.基于优先经验回放的多智能体协同 算法[J].太原理工大学学报,2021.52(5):747-753.
[12] 刘庆强,刘鹏云.基于优先级经验回放的SAC强化学习算法 [J].吉林大学学报(信息科学版),2021.39(2):192-199.
[13] 胡仕柯,赵海军.基于改进柔性演员评论家算法的研究[J]. 太原师范学院学报(自然科学版),2021.20(3):48-52.
[14] YANG Y D,WEN Y,CHEN L H,et al.Multi-agent Determinantal QLearning[C]//International Conferenceon Machine Learning,2021:10078-10866.
[15] 李天旭.基于深度强化学习的多智能体协同算法研究[D]. 徐州:中国矿业大学,2020.
[16] 程艳.基于深度强化学习的智能体自适应决策能力的生成 [D].济南:山东大学,2021.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/55687.html