SCI论文(www.lunwensci.com)
摘 要:近些年随着深度强化学习的不断发展,其训练成本也在不断增加,然而传统的训练平台大部分是基于顺序执行训 练,不仅训练时间长、硬件成本高昂,且数据采样也非常困难。为了解决这些问题,本文中提出了一种基于 Ray 并行分布式架 构的深度强化学习计算平台(RRLP),平台利用固定资源预算进行异步并行训练,兼容机器人仿真环境,不仅可以节约硬件资 源,还可以加快采样与训练速度提高效率。通过实验可知基于 Ray 并行分布式架构的深度强化学习计算平台优于传统的计算平 台,且有一定稳定性和可扩展性。
关键词:Ray,并行,仿真,深度强化学习
Deep Reinforcement Learning Computing Platform Based on Ray Parallel Distributed Framework
ZHAO Kang, MA Chenyan, WANG Daojun
(School of Information Engineering, Huzhou University, Huzhou Zhejiang 313000)
【Abstract】: In recent years, with the continuous development of deep reinforcement learning, its training cost is also increasing. However, most of the traditional training platforms are based on sequential execution of training, which not only takes a long time to train, the hardware cost is high, but also data sampling is very difficult . In order to solve these problems, this paper proposes a deep reinforcement learning computing platform (RRLP) based on the Ray parallel distributed architecture. The platform uses a fixed resource budget for asynchronous parallel training and is compatible with the robot simulation environment. It can not only release hardware resources, but also speed up sampling and training to improve efficiency. Experiments show that the deep reinforcement learning computing platform based on the Ray parallel distributed row architecture is superior to the traditional computing platform, and has certain stability and scalability.
【Key words】: Ray;parallel;simulation;deep reinforcement learning
引言
深度学习主要是通过多层的神经网络训练以使其达 到期望的学习效果,通过组合低层特征形成更加抽象的 高层表示属性类别或特征,以发现数据的分布式特征表 示 [1]。强化学习是机器学习中一种重要的学习方法, 也 被认为是属于马尔科夫决策过程和动态优化方法的一个 独立分支 [2]。强化学习是智能体以“试错”的方式进行 学习,随着人工智能的发展,强化学习不再局限于动作 空间和状态空间很小的离散环境,特别是深度强化学习面临更复杂更接近现实的连续环境,机器人是深度强化 学习主要的应用场景之一。目前,机器人领域中使用的 大多数方法都是基于控制理论的,这就要求提前建立模 型并收集机器人与环境之间的大量交互数据来训练控制 策略的模型,成本很高,需要通过大量机器人的交互来 获得大量采样数据。然而,使用真实的机器人进行大 量数据采样时同样存在一些问题,如采样速度慢、损耗 大、成本昂贵等,甚至可能是危险的,比如四翼飞机机 器人。为了解决采集数据的困难,美国南加州大学研发了一种先进的机器人仿真器 --Gazebo,它有助于节省 成本、缩短时间和加快数据收集速度。为了方便环境模 拟和机器人训练,有许多优秀的项目,例如 OpenAI 下 的 Gym、Roboschool 等。只有对机器人环境进行充 分的交互和训练,才能获得满意的训练结果。然而,由 于受单指令顺序操作方式的局限性,训练时间已成为机 器人领域强化学习应用的瓶颈 [3]。
为了解决这些问题,本文提出了一个基于 Ray[4] 并 行分布式行架构的深度强化学习计算平台(RRLP),将 并行和分布式方法进行了结合和扩展,融合了机器人仿 真环境,有效地提高机器人的强化学习训练速度,提高 了效率。本平台不仅为强化学习的训练与机器人仿真提 供了分布式支持、具有一定的高兼容性,且支持远程桌 面等操作。
1 平台系统架构
本节将介绍基于 Ray 并行分布式架构的深度强化学 习计算平台设计方案及平台各部分结合的主要框架,系 统整体架构如图 1 所示。平台由应用层、Ray 并行分布 式框架、模拟框架和虚拟容器层 4 部分构成。
1.1 应用层
应用层由基于 Docker[5] 虚拟 LXDE 轻量化桌面和 VNC 控制构建组成,用户可以便捷,直观的进行桌面 操作,近实时的对机器人的模拟、训练效果进行查看, 客户端实现架构如图 2 所示。
服务启动后,用户可以利用浏览器访问虚拟 LXDE 轻量化桌面(如图 3 所示),通过虚拟 Ubuntu 操作系 统桌面,进行训练模型任务的提交,模拟环境数据的采 样、便捷的查看训练结果 ;通过 Nginx[6] 反向代理服务 服务,可以有效地防止局域网内的集群被攻击。
1.2 Ray 并行分布式框架
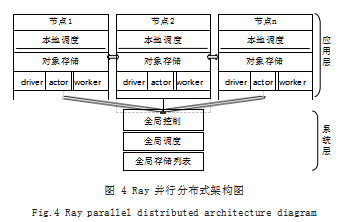
Spark[7] 是美国加州大学研发出来的类 Hadoop MapReduce[8] 的分布式通用架构,系统框架主要采用 的是一主多从架构,使用计算机内存进行大量的数据运 行,很好的支持了机器学习模型的训练。虽然 Spark 可 以应用于常规的机器学习模型,但是它任务级别的作 业迭代方式 [9],对强化学习需要频繁交换参数的任务很 难有效的处理。2017 年伯克利大学 RISELab 实验室开 发出了一个针对深度强化学习通用异步并行框架 Ray, Ray 的分布式迭代作业从任务级别降到了函数级别,有 效地解决了 Spark 对强化学习的不支持。故本文提出的 RRLP 平台采用 Ray 作为主体框架,可以完美地解决强 化学习模型训练过程中频繁的数据收集和再分发。Ray 不仅可以异步并行的分发任务,还可以共享所有的存储 资源,从而获得了更加适宜并行分布式强化学习计算的 优异性能,Ray 并行分布式架构图如图 4 所示。
1.3 仿真环境
本平台的仿真架构融合了可以进行自动驾驶测试任 务的模拟赛车游戏 Torcs(如图 5(a)所示),图像识 别及情景交互测试任务的 FPS 游戏框架 VizDoom(如 图 5(b) 所示), 常用的机器人仿真软件 Gazebo(如 图 5(c) 所示) 以及 Bullet 模拟环境(如图 5(d) 所 示)。由于仿真模拟框架系统内部设计是单机设计的, 为了便于并行分布式和容器的部署,使机器人仿真模拟框架更适应联机采样及训练,修改各个模拟框架中部署 与启动部分的内容。另外为了给深度强化学习模型的训 练提供便利,平台安装了多种强化学习开源算法工具 包, 包括 :Gym、TensorFlow、Pytorch 以及 Ray 开 发组提供的 Tune 和 RLlib。
1.4 Docker 虚拟层
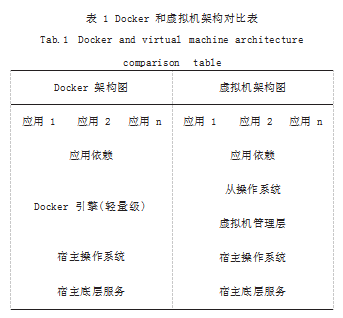
现有的大部分强化学习训练模型和机器人仿真框架 都是基于 Linux 系统开发的,然而用户使用的操作系 统不一,版本较杂乱,故引入了 Docker 虚拟化容器技 术,使平台进行容器化部署,进而提高平台的灵活性, 有效地解决了多系统的兼容问题。Docker 独特的虚拟 化方式,和传统的虚拟机式对比拥有明显的优势,开发 人员可以快速交付和部署产品、不需要额外的虚拟化管 理程序的支持,高效的计算机资源利用、轻松地进行迁 移和扩展、快捷的版本管理。如表 1 所示是 Docker 和传统虚拟机的架构对比表。
2 实验与评估
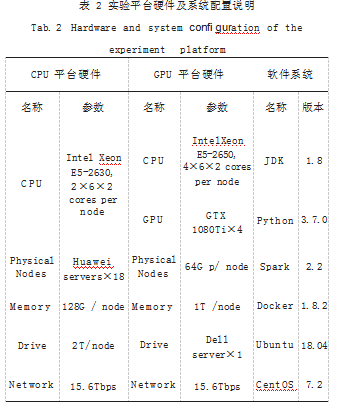
本节对基于 Ray 并行分布式行架构的深度强化学习 计算平台与 Spark 平台从流数据处理性能和在节点扩 展性能两个方面进行实验,综合实验结果对平台进行分 析。如表 2 所示为 CPU、GPU 实验平台硬件及软件系 统配置说明,本文中的实验都是基于此配置进行的。重要指标,能够有效的体现系统中各节点之间数据计 算性能和数据交互的速度,故采用流数据处理来测试 RRLP 平台的性能。另外选用经典的 Spark 分布式框架 作为对比实验,实验的基础数据是 20 篇英文期刊论文 和 20 篇中文期刊论文, 文章的内存约为 29Mb 大小 ; 实验内容是对文章进行统计字符数、单词数、行数,实 验选择的节点数为 1 ~ 10 个,每个节点对应的 CPU 核 心数为 12 个。
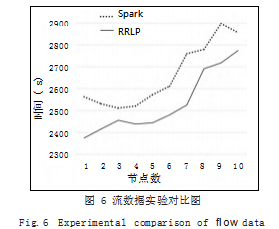
通过如图 6 所示的流数据实验对比图可以看出, RRLP 平台处理数据所使用的时间都少于 Spark 分布式 计算平台,且在运行节点数较少的情况下 RRLP 平台 性能更优。
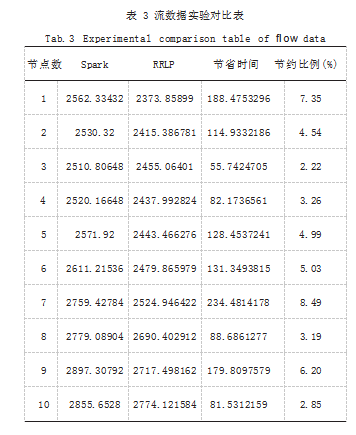
如表 3 所示给出了在相同运行节点数量下处理完数据所使用的耗时,可以发现 RRLP 平台比 Spark 对流数据处理能节省时间在 81 ~ 234s 之间,节省比例 在 2.22% ~ 8.49% 之间。综上可得 RRLP 平台在流数 据处理性能优于 Spark,且性能随着节点的数量增加稳 步提高,具有一定的稳定性。
2.2 RRLP 平台分布式实验
平台在具体的使用中, 除了硬件配置外, 可扩展性 是分布式平台的另一个非常重要的性能指标,故本实验 通过不同的节点数来判断 RRLP 计算平台是否具备良好 的可扩展性。
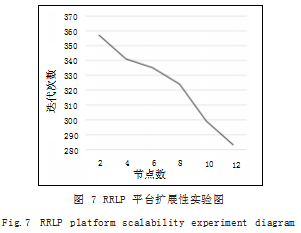
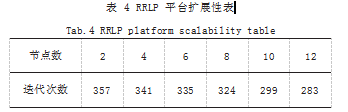
实验采用的仿真环境是 Pybullet 中的 Humanoid BulletEnv-0 仿真环境,策略选取强化学习策略算法 : A3C(Asynchronous Advantage Actor-critic) 算法 [10], 通过超参数调优的方法选择超参数 [11],实验终止条件 是最优奖励达到 1000.使用的 GPU 集群,集群的节点 数为 2 ~ 12 个。如图 7 所示是 RRLP 平台在不用运行 节点数上的性能折线图,如表 4 所示是达到停止条件的 迭代次数,通过分析可得 RRLP 平台对于同一个训练任 务,随着节点的增加训练时间稳步减少,说明并没有因 为节点数量的增加而过多的增加节点间通信损耗。综上 可知 RRLP 平台具有一定的稳定性和可扩展性。
3 结论
本文根据传统计算平台不能满足当前深度强化学习 发展的需要,提出了一种异步并行训练平台—基于 Ray 并行分布式架构的深度强化学习计算平台(RRLP)。该 平台以 Ray 并行分布框架底层框架, 融合了强化学习 相关的开源框架,兼容多种机器人仿真环境,使平台不仅可以充分利用集群硬件资源,还可以提高强化学习训 练数据采集的速度。另外平台利用 Docker 容器技术, 大大提高了平台的部署速度。通过实验可知 RRLP 平台 是一个具备可用性、可扩展、稳定性的计算平台。
参考文献
[1] HINTON G E,OSINDERO S,TEH Y W.A Fast Learning Algorithm for Deep Belief Nets[J].Neural Computation, 2006.18(7):1527-1554.
[2] WIERING M A,VAN OTTERLO M.Reinforcement Learning[J].Adaptation,Learning,and Optimization,2012. 12(3):729.
[3] MORITZ P,NISHIHARA R,WANG S,et al.Ray:A Distributed Framework for Emerging Ai Applications[C]// Operating Systems Design and Implementation.Carlsbad: USENIX,2018:561-577.
[4] 黄增强.面向机器人模拟与强化学习的分布式训练平台设计 与实现研究[D].杭州电子科技大学,2020.
[5] Dirk Merkel.Docker:Lightweight Linux Containers for Consistent Development and Deployment[J].Linux Journal,2014(239):76-90.
[6] Will Reese.NGINX the Hith-performance Web Server and Reverse Proxy[J].Linux Journal,2008(173):62-67.
[7] ZAHARIA M,CHOWDHURY M,FRANKLIN M J,et al.Spark:Cluster Computing with Working Sets[C]// IEEE International Conference on Cloud Computing Technology and Science.USENIX Association, 2010.
[8] DITTRICH J,QUIANÉ -RUIZ J A.Efficient Big Data Processing in Hadoop MapReduce[J].Proceedings of the VLDB Endowment,2012.5(12):2014-2015.
[9] ZAHARIA M,CHOWDHURY M,DAS T,et al.Resilient Distributed Datasets:A {Fault-Tolerant} Abstraction for {In-Memory} Cluster Computing[C]//9th USENIX Symposium on Networked Systems Design and Implementation (NSDI 12),2012:15-28.
[10] SCHULMAN J,WOLSKI F,DHARIWAL P,et al.Proximal Policy Optimization Algorithms[J].2017.
[11] 蒋云良,赵康,曹军杰,等.基于种群演化的超参数异步并行 搜索[J].控制与决策,2021.36(8):1825-1833.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/52617.html