SCI论文(www.lunwensci.com)
摘 要:针对现有垃圾短信识别方法,在复杂场景中特征表示效率低的问题,提出文本预处理结合 Bert 模型的垃圾短信 识别方法。首先对数据集进行预处理,消除冗余信息对分类器的影响,然后将预处理后的数据按 8 :1 :1 比例划为训练集,交 叉验证集和测试集三类。将 Bert 模型引入垃圾短信识别分类场景,利用动态掩码提高了文本特征表征能力。实验结果表明, 本文提出的垃圾短信识别方法具有较好的识别效果。
关键词:垃圾短信,文本分类,Bert 模型
Research on Spam Message Recognition Based on Bert Model
WANG Jingxuan, LU Beini, YANG Jie, WU Sinan
(Jiaxing Nanhu University School of Information Engineering, Jiaxing Zhejiang 312000)
【Abstract】: Aiming at the problem of low efficiency in feature representation of existing spam message recognition methods in complex scenes, a spam message recognition method combining text preprocessing and Bert model is proposed. Firstly, the data set is preprocessed to eliminate the influence of redundant information on the classifier, then the preprocessed data were divided into training set, cross validation set and test set in a ratio of 8:1:1. The Bert model is introduced into spam message recognition scenarios, and the dynamic mask is used to improve the ability of text feature representation. Experimental results show that the proposed method in this paper has a good recognition effect.
【Key words】: spam message;text classification;Bert model
0 引言
随着万物互联时代的到来,智能手机已经成为用户 日常通讯的重要工具之一。其中,手机短信凭借其运作 简易、舒适便捷等诸多优点,已成为用户之间沟通的重 要媒介。然而在短信业务迅速发展的同时也带来了一些 信息安全方面的问题。不法分子利用短信大量发送广 告、虚假信息、散布谣言、传播不良、色情信息等垃圾 短信。垃圾短信不仅污染了网络环境,占用了有限的网 络资源,造成网络拥塞,使运营商耗费更多的资源对其 进行处理,手机用户也要耗费大量的时间来删除垃圾短 信,垃圾短信已成为一种社会公害。如何对海量的垃圾 短信准确识别分类和有效处理仍是当前亟待解决的重要 课题。
目前常用的中文垃圾短信识别方法有基于规则的方 法、基于黑白名单的方法、基于内容的方法 [1]。规则法 要求人为提前进行规则制定,遇到新型垃圾短信需新增 规则才能识别,这种垃圾短信识别方法过于繁琐。黑白 名单法只能识别已经在名单中的号码,过于单一,无法 对陌生号码的信息进行识别,大多时间需人工干预。基 于内容的短信识别是将文本分类技术引入垃圾短信识 别,是目前国内外主流的垃圾短信识别方法。该方法 主要通过机器学习分类模型对垃圾文本进行分类,如 : TextCNN[2]、贝叶斯网络、支持向量机利用机器学习算 法提升了垃圾短信识别效率。然而,在一些一词多义等 复杂场景中,现有模型不能很好的表征文本特征。前述 针对垃圾短信文本的特征表示算法均是将其进行分词或者分字,处理对象为字符或者词语层面的特征,而由于 垃圾短信具有特征稀疏的特性,字符或者词语不能表示 短信的完整语义,因此导致短信的特征表示向量不能较 好地代表短信语义。因此,短信的特征表示是提高垃圾 短信识别性能的关键步骤。例如 :“我喜欢小米”,这里 的小米可能是指小米手机,也可能是吃的小米。Bert 模 型通过对未标注的文本信息进行深层双向表示获得上下 文语义信息,一词多意问题在 Bert 模型中得到了解决。 本文将 Bert 模型引入垃圾短信识别,提出本文数据预 处理结合 DMBert 模型的垃圾短信识别方法, 论文主要 贡献如下 :
(1) 将 Bert 技术引入到垃圾短信处理场景,解决了 以往垃圾短信处理中的特征表示存在歧义性、分类精度 低的问题 ;(2)提出动态 MASK 方法 ( 简称 DMBert), 提升了文本特性的表征能力 ;(3)与现有方法的实验对 比表明,DMBert 在垃圾短信识别中有一定的优势。
本文基于 Bert 的垃圾短信识别算法主要由短信数 据预处理、短信数据向量化以及短信识别三部分构成, 短信数据预处理的目的是将输入的短信数据整理成识别 所需的文本,降低其他符号对识别效果的影响,然后对预 处理后的短信数据进行向量化表示并形成特征向量, 最终 将特征向量输入搭建好的识别器以实现垃圾短信识别。
1 数据预处理
数据预处理是垃圾短信识别的关键步骤,预处理质 量的高低直接影响识别效率。数据预处理过程主要包括 删除重复语句、分词、删除无用词等。中文句子词语之间 没有显著的分隔符标识,相对英文句子,结构比较复杂。 理解中文句子,首先要理解中文词语,要对句子中的词进 行分割。分词质量直接影响文本分类效果。目前主流的分 词工具有、JIEBA 、NLPIR、THULAC 和 SNOW NLP 分 词器 [3]。其中, JIEBA 分词器根据文本内容自定义和修 改词典,在中文分词中被广泛应用。本文采用 JIEBA 分 词器对短信文本进行分词,降低无用词对分类器的干扰。
在原始数据集中包含许多重复语句和无用信息, 如特殊符号、标点符号、数字、表情、乱码等冗余信 息,这些冗余信息对分类模型产生不必要的噪音,影 响垃圾短信识别效果。本文的数据预处理包括两个部 分,首先删除数据集中重复语句,然后,去除“@、%、 &... ”“你”“地”“她”“和”等标点符号、特殊符号、 人称代词、副词、连接词。垃圾短信(文本信息)属于 非结构化的字符串数据,如何将汉字字符串信息编码成 计算机能识别的二进制数据是文本分类中的关键。传统 的中文文本编码方式有 :One-hot、词袋模型、TF-IDF、共生矩阵 (Co_ocurrence matrix) 等 [4],目前主流的文 本编码方式,即文本向量化(词嵌入)方法有两种,静 态预训练模型 Word2Vec、GloVe 和动态预训练模型 XLNet、Bert。Bert 解决了一词多义问题,在复杂场景 中具有较好的识别效果,本文采用 Bert 模型作为词向 量表征方法。
2 Bert 和 DMBert 模型
Bert(Bidirectional Encoder Representation from Transformers)模型于 2018 年由 Google AI 研究 院提出 [5],可为文本信息生成高质量的特征表征。Bert 是一个预训练自然语言处理模型,它通过对未标注的文 本进行深层双向表示获得上下文语义信息,在训练过程 中学习到文本的更多维、更深层次的内容。训练得到的 模型可用于文本分类等多个领域,相比于传统自然语言 处理(Natural Language Processing, NLP) 方法更加方 便、高效。Bert 模型的核心为 Transformer 框架, 输入 向量 X 由 Token Embedding、Segment Embedding、 Position Embedding 3 个向量构成。
其中 Token Embedding 包含字符的语义信息,Seg- ment Embedding 包含上下文信息,Position Embedding 包含位置信息。Transformer 由一堆编码器(Encoder)编 码组件和相同数量(与编码器对应)的解码器(Decoder) 组成。其中,单个编码器由注意力机制、前馈神经网络 组成,解码器由注意力机制、编码 - 解码注意力层、前 馈神经网络组成。
DMBert(Dynamic Masking Bert) : 在 Bert 开 始训练数据时,训练集中的每一个样本只进行一次随机 MASK, 这样该样本在所有的 Epoch 中重复, 在每一 个训练步中都是用相同的 MASK,这就是 Bert 的静态 MASK。在我们的 DMBert 中,训练集中的每一个样本 在每一个训练步都进行一次动态随机 MASK,这样每个 Epoch 的样本 MASK 是变化的,这就有效避免了训练 集数据的重复,动态 MASK 的操作,近似于对数据增 广操作。预测效果在 Bert 基础上有了进一步地提升。
2.1 Bert 预训练
预训练模型的目的是利用庞大的语料库训练出一个 尽量能够应对各种下游任务的模型,即通过预训练让模 型对每一个词,在各种可能的上下文环境中的语义和用 法留下记忆。Bert 通过两项任务对模型进行预训练,分 别为遮蔽语言模型(Masked Language Model, MLM) 和邻句预测(Next Sentence Prediction, NSP)。
Bert 用 MLM(Masked Language Model, 掩码 语言模型) 方法训练词的语义理解能力, MLM 是借鉴完形填空任务和 Word2Vec 中 CBOW 算法思想定义的 一种模型预训练任务。具体实现过程为 :随机抽取部分 词进行掩码操作,用 [Mask] 掩码字符来替换被抽取到 的单词,训练 Bert 模型来正确预测这些被掩码词。遮 蔽语言模型的训练集与测试集数据之间存在不可避免的 系统性数据分布差异,这会产生训练与预测数据偏差导 致的性能损失,为改善这一弊端, Bert 在样本中随机抽 取 15% 的掩码词后,对抽取的掩码 80% 的样本用掩码 标记 [Mask] 替换掩码词,对另外 10% 的样本不做任何 替换,对最后 10% 的样本从模型词表中随机抽取单词 来替换掩码词。
Bert 用 NSP(Next Sentence Prediction, 下句预 测)方法训练句子之间的理解能力,使模型能学会捕捉 句子间的语义联系。具体实现过程为 :模型的输入语句 由两个句子组成,其中有 50% 的概率将语义连贯的两 个连续句子作为训练样本(连续句对应取自篇章级别的 语料,以确保前后语句的语义强相关),另有 50% 的概 率将完全随机抽取的两个句子作为训练样本,模型要根 据输入的两个句子,判断它们是否属于真实的连续句对。
2.2 Bert 微调
微调阶段增强了 Bert 模型的鲁棒性和对上下文信 息的提取能力。预训练阶段 MLM 和 NSP 这两项任务 同时进行。使用训练好的 Bert 模型,同时加入一个全 连接网络进行微调,可以较为全面的提取输入文本序列 中包含的语言特征信息,便可以完成诸多 NLP 任务并 取得较好的结果。
Bert 模型使用 Transformer Encoder 结构作为特征提取器,而不拼接使用两个方向的 Transformer Decoder 结构作为特征提取,它可以提取字与字、词与词、句子 之间的特征关系,有较强的泛化能力。为了将 Bert 模型 应用于垃圾短信识别任务,本文在输出层后增加一个全 链接层即分类层,分类层的输出结构经过 Sigmoid 函 数获得各 Token 类别标签的概率分布。微调的过程在 数据集上进行有监督训练,以此改变预训练模型的权重 矩阵。
3 短信数据表示
本文使用 Bert 模型进行短信的向量表示,而在传 统方法中一般的短信表示流程如图 1 所示。
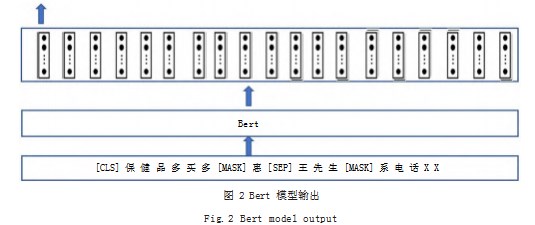
Bert 模型的输出有两种形式 :一种是字符级别的向 量,即输入短信的每个字符对应的向量表示 ;另一种是 句子级别的向量,即 Bert 模型输出最左边 [CLS] 特殊 符号的向量, Bert 模型认为该向量可以代表整个句子的 语义,如图 2 所示。
在图2中, 底端的[CLS]和[SEP]是Bert模型自动 添加的句子开头和结尾的表示符号, 可以看出输入字符 串中每个字符经过 Bert 模型处理后都有相应的向量表 示。当需要得到一个短信的向量表示时, Bert 模型输出最 左边 [CLS] 特殊符号的向量,由于本文使用 Bert 模型的 输出,因此相比一般短信表示流程,无需进行特征提取、 特征向量表示及特征向量拼接,具体流程如图 3 所示。
在本文中得到短信数据的向量表示后,可以根据需 要选取 Bert 输出最左边 [CLS] 特殊符号的向量或整个 短信字符串的向量输出来添加不同的分类器,对垃圾短 信数据进行分类。
4 实验介绍
4.1 实验数据及评价指标
实验数据集源于网络公开数据集 message80W1.共 有 80 万条。实验将数据按比例分为训练集、交叉验证集和 测试集 3 类,分割比例为 8:1:1.用训练集训练好 Bert 模 型后,即可用交叉验证集测试,根据输出结果改进模型。
样本根据其真实类别与学习器预测类别的组合划分 为真正样本 (True Positive), 真反样本 (True Positive), 假假正样本 (False Negative), 假反样本 (False Negative) 4 种情形, 令 TP、TP、TN、FN 分别表示其对应的样 本数, 则显然有 TP+FP+TN+FN= 样本总数。本文以查 准率、查全率和 F1-Score 作为算法对比的评价指标。
查准率 (Precision) :查准率表示真正样本在预测 为正样本中的比率,如式(1)所示 :
4.2 实验结果及分析
实验运行环境为 :CPU 为 i7-6800k, 内存为 16G, GPU 为 GTX2070. 显存为 8G, 操作系统为 64 位系统 Unbutu20.04. 编程环境为 Python3.8. 深度学习框架 为 Pytorch1.11.0.
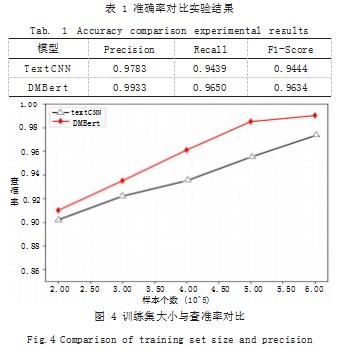
80W 个训练样本经过 8:1:1 比例分割后,60W 个 样本作为训练集,交叉验证集和测试集分别为 10W 个 样本。我们对本文提出的方法与经典的文本分类方法 TextCNN 在查准率、查全率、F1-Score 3 个指标上进 行实验对比。如表 1 所示展示了在 3 个评价指标上的实 验对比结果,结果表明 DMBert 模型相对 TextCNN 方 法有一定优势, DMBert 模型在每个训练步(Epoch) 动态生成词遮罩,使得训练模型具有更好的文本特征表 征能力。如图 4 所示展示了模型随着训练样本数增加查 准率的变化情况,从图 4 中可以看出,随着训练样本数 的增加,模型的查准率有所提升。
训练时间上 DMBert 模型在 60W 样本上花费 8h, 而 TextCNN 模型花费 50min, 说明 TextCNN 模型在 训练时间上优于 DMBert。
5 结语
针对现有垃圾短信识别方法在一词多义等复杂场景 中不能很好的表征词向量问题,提出了文本预处理结合 Bert 动态掩码的垃圾短信识别方法。在 message80W1 数据集上的实验结果表明, Bert 在训练时间上不占优 势,但结合预训练模型和动态掩码,得到更加符合短信 文本语义动态词向量,可以提升模型的学习能力,在特 征稀疏、复杂环境中有更多的优势。
参考文献
[1] 吴思慧,陈世平.结合TFIDF的Self-Attention-Based Bi- LSTM的垃圾短信识别[J].计算机系统应用,2020.29(9):171-177.
[2] QIN X F,PENG S L,YANG X,et al.Deep Learning Based Channel Code Recognition Using TextCNN[C]//2019 IEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN).IEEE,2019:1-5.
[3] 赖文辉,乔宇鹏.基于词向量和卷积神经网络的垃圾短信识 别方法[J].计算机应用,2018.38(9):2469-2476.
[4] 江伟.基于深度学习的文本分类[D].南京:南京理工大学,2018.
[5] DENLIN J,CHANG M W,LEE K,et al.Bert:Pre-training of Deep Bidirectional Transformers for Language Understanding[C]//Conference on the North American Chapter of the Association for Computational Linguistics: Human Language Technologies,2019:4171-4186.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/54397.html