SCI论文(www.lunwensci.com):
摘要:本文提出基于FastText分类语言模型来解决农业短文本分类问题。在数据处理好类别的情况下,利用实验对12万条农业数据集进行实验。并探究与典型深度语言模型(TextRNN、TextCNN、TextDPCNN、Transformer)进行对比分析其中的分类准确率和分类处理响应时间。实验结果得出结论,基于深度学习的FastText模型的农业短文本分类效果最好,FastText模型对比其他模型的准确率、精确率、召回率和F1值提高了1%~4%。FastText模型可以对中文农业短文本分类处理速度更好,更优于其他典型深度语言模型算法。
关键词:农业短文本分类;文本分类;语言模型;FastText
Classification of Agricultural Short Texts Based on FastText Model
WANG Fujian1,2,WEI Linjing1,AN Zhaoxian1,LIU Zhizu3
(1.School of Information Science and Technology,Gansu Agricultural University,Lanzhou Gansu 730070;2.Jilin Engineering Normal University,Changchun Jilin 130052;3.Linxia Agricultural Technology Extension Service Center,Linxia Gansu 731100)
【Abstract】:This paper proposes a FastText classification language model to solve the problem of agricultural short text classification.Under the condition of data classification,experiments were carried out on 120,000 agricultural data sets.And compared with typical deep language models(TextRNN,TextCNN,TextDPCNN and Transformer),the classification accuracy rate and response time of classification processing are analyzed.The results show that the FastText model based on deep learning has the best effect on agricultural short text classification,and the FastText model improves the accuracy,accuracy,recall rate and F1 value by 1%~4%compared with other models.FastText model can classify Chinese agricultural short texts faster than other typical deep language model algorithms.
【Key words】:classification of agricultural short texts;text classification;language model;FastText
0引言
时代的发展下,农业领域需要不断改革生产模式与创新,因为传统的农业模式已经不能满足不断变化的时代演变[1],全球各个国家积极在农业生产领域不断引入信息技术进行结合,是提升农业发展质量的关键所在[2]。自从人工智能这个概念兴起之后,众多学者根据机器学习方法[3]和典型深度学习方法[4],研究中文文本分类,使得自然语言处理[5]变得更加发展壮大,其中就有相关领域学者在农业文本分类上做了相关的研究。顾春燕等[6]使用朴素贝叶斯分类的机器学习方法,对文本信息进行分类研究。万家山等[7]基于深度学习对文本分类进行理论分析研究。
1材料与方法
本文采用的是Intel酷睿I5处理器、显卡GTX 2080TI等配置的实验环境,符合实验要求,数据集合是从“农业科技网络书屋专家在线系统”(http://zjzx.cnki.net/)中采集到的农业短文本训练需要的数据集。作为训练的原始数据,在“农业经济”“农业工程”“水产渔业”“养殖技术”“林业”“园艺”“农作物”的7个类别下,使用分类标签把文本内容的进行存储[8]。取得数据量为12万,通过数据的收集,然后进行清洗,最终整理的数据量为6.5万条,用于模型训练的农业短文本语料库。按照8:1:1的比例分配数据集,通过分配处理,可以得到训练数据集为80%,验证集10%和测试集10%。测试数据集、训练数据集和验证数据集均没有重复的交叉,符合评价指标。
2 FastText模型
FastText模型输入都是多个单词,利用特征来表示单个文档,是一种词汇嵌入[9],类似于n-gram模型特征,FastText的输入特征是神经网络映射后的向量,将单词的字符级别的n-gram[10]向量作为附属特征,输出是单词对应的类标,采用了分层Softmax[11,12],大大降低了模型训练时间。详细分析模型可以看出,从输入层输入到隐含层输出部分,主要做的事情是叠加构成所有词和n-gram的词向量,然后取平均。叠加词向量的核心思想,就是使用传统的词袋方法,让文本看成一个由词构成的集合,生成用来表征文档的向量。然后,从隐含层输出到输出层输出的这个过程,输入的是一个用来表征当前文本的向量,就像是Softmax线性多类别分类器。可看出FastText的中心思想是将整个短文本数据的词及n-gram向量叠加平均得到整个文本向量,然后使用字符级n-gram特征的引入以及用文本向量分层Softmax分类中。
3实验过程及结果分析
3.1实验设计
本文为了研究文本分类问题,拟定了基于不同数据量和不同的数据集,对FastText模型进行实验并与其他模型进行对比实验。实验使用的有效数据集,一共是6.5万条带有标签农业短文本信息,标签类别有7种,分别为“农业经济”“农业工程”“水产渔业”“养殖技术”“林业”“园艺”“农作物”。通过农业短文本数量按比例生成训练集、验证和测试数据集合,产生分类比例为8:1:1,为保证实验分类均等,每次会从各个类别中抽取等量的农业短文本。使用FastText模型分别与典型深度学习模型TextRNN、TextCNN、TextDPCNN、Transformer的训练结果进行对比分析。将数据分为训练集52000条,测试集6500条,验证集6500条,总计为65000条的数据集。
3.2实验结果与分析
不同数据集下各模型对比结果,在7个类别上的准确率(Accuracy)的表现,FastText模型95.15%、TextRNN模型93.38%、TextCNN模型94.12%、Text DPCNN模型92.68%、Transformer模型91.22%,表明5个模型在7个分类下各模型的性能有所差异。对比实验得出结果,各模型的准确率值均有不同,这可以反映出农业文本分类模型的性能与数据集数量和模型本身算法有一定的关系。
经过实验的结果,可以发现在数据集数量为65000条的时候,FastText模型的准确率为95.15%,高于其他模型,其中准确度最大差为3.93%,最小差为1.03%,可以分析看出FastTest在短文本数据的分类处理上比其他模型更优秀。
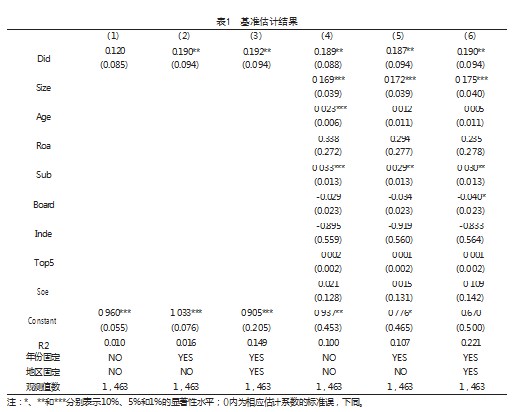
如表1所示可以发现,实验在各个模型在每种分类的计算结果,一共有3个指标,分别为精确率(Precision)、召回率(Recall)和F1值。观察实验5个模型在7个类别上的精确度均有不同,说明各模型在7个类别上的分类性能和数据量的不同,导致有所差异。从F1值分析发现各个模型差距在1%左右,但是从“类别”角度分析可知,对于“养殖技术”和“水产渔业”这2个类别的精确率较高。
4结论与展望
本文首先引出了研究的意义,说明农业信息化的研究应该更加深入,描述当今的研究基础,然后介绍了实验的环境以及要采用的方法,然后简要描述FastText模型介绍和相关思想方法,通过实验对比分析,详细介绍实验内容与设计,最终研究解决的是农业短文本在遇到分类问题,使用深度学习模型,通过对比证实了几种模型分类效果。使用FastText模型对比其他4种模型,得出结论FastText模型在农业领域处理中文文本分类问题下比其他4种模型更加优越,证明FastText模型有着更高的使用价值,可表明该模型可以满足实际的工业应用场景,对研究学者在准确性、响应速度和功耗上有一定参考价值,可以有效地解决农业文本分类问题。在技术的不断更新迭代过程中,相信未来会有更多的人投入农业领域的研究,为提高农业的发展具有深远意义。
参考文献
[1]谢义军.浅析农业信息化在我国现代农业发展中的作用[J].现代农业研究,2021,27(6):19-20.
[2]韦燕珍.浅谈农业信息化在现代农业发展中的重要作用[J].南方农业,2020,14(21):184-185.
[3]KANWAL S,HUSSAIN A,HUANG K Z.Novel Artificial Immune Networks-based Optimization of Shallow Machine Learning(ML)Classifiers[J].Expert Systems With Applications,2021,1-11.
[4]杜思佳,于海宁,张宏莉.基于深度学习的文本分类研究进展[J].网络与信息安全学报,2020,6(4):1-13.
[5]陈德光,马金林,马自萍,等.自然语言处理预训练技术综述[J].计算机科学与探索,2021,15(8):1359-1389.
[6]顾春燕.基于朴素贝叶斯的区域高校图书馆数字资源一站决策算法[J].软件工程,2022,25(1):33-36+40.
[7]万家山,吴云志.基于深度学习的文本分类方法研究综述[J].天津理工大学学报,2021,37(2):41-47.
[8]武渊,徐逸卿.基于多层异构注意力机制和深度学习的短文本分类方法[J].中北大学学报(自然科学版),2021,42(5):426-434.
[9]GU Y R,ZHOU P,YANG H G.News Recommendation Based on Time Factor and Word Embedding[J].TheJournal of China Universities of Posts and Telecommunications,2021,28(5):82-90.
[10]罗光华.一种基于NLq损失的Softmax分类模型改进[J].电脑知识与技术,2020,16(34):228-229.
[11]王晔,黄上腾.Apriori and N-gram Based Chinese Text Feature Extraction Method[J].Journal of ShanghaiJiaotong University,2004(4):11-14+20.
[12]曹佳.基于文本语义相似度的企业招聘系统的设计与实现[D].曲阜:曲阜师范大学,2020.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/50394.html