SCI论文(www.lunwensci.com):
摘 要:针对互联网时代面临的通过人工对海量新闻进行分类较为困难的问题,本文通过贝叶斯、RidgeClassifier 和 fastText 这三种分类器进行新闻文本分类,分析比较了这三种分类器对新闻文本分类的效果。实验结果表明,三种分类器均可 以实现新闻文本分类的任务,其中 fastText 方法在匿名新闻文本分类问题中各方面性能指标最优,本文从算法理论上分析了产 生这一差异的原因。
关键词:贝叶斯 ;RidgeClassifier ;fastText ;文本分类
A Comparative Study of Bayesian, Ridgeclassifier and fastText Algorithms in Anonymous News Text Classification
XU Weizhen
(College of Mathematics and Computer Science,Zhejiang Normal University, Jinhua Zhejiang 321004)
【Abstract】: The massive amount of news on the Internet makes manual news text classification an unrealistic task. In this paper, we classify news text by Bayesian, RidgeClassifier, and fastText classifiers and analyze and compare the effects of these three classifiers. The experiments show that these classifiers can achieve the task of news text classification. Among them, the fastText method has the best performance index in all aspects of anonymous news text classification , and the reasons for this difference are analyzed in the theoretical aspect.
【Key words】: Bayes;RidgeClassifier;fastText;text classification
0 引言
随着互联网时代的发展,人们获取新闻的方式由传 统的报刊和电视转变为各种电子设备,如手机、电脑 等。相比于传统纸媒时代,人们获取新闻变得更加容 易,但从海量新闻中比较精准地得到自己需要的新闻的 效率却大大降低,同时人工对新闻进行分类的难度随 之增加。文本分类在垃圾信息过滤 [1]、暗网非法活动检 测 [2]、社交平台文本情感分析 [3] 中发挥着重要作用。因此,利用自然语言处理中的文本分类技术对于新闻进行 分类是一个值得研究的问题。
在有监督学习的框架下,文本分类的方法可大致分 为三类 :传统的机器学习方法、利用继承技术进行模型融合的方法以及基于深度学习的方法 [4]。如文献 [5] 提 出一种基于改进的 TF-IDF 和贝叶斯算法的新闻分类方 法。文献 [6] 提出利用 Word2vec 模型融合 LDA 主题模 型扩展短文本的特征表征表示方法。文献 [7] 基于 CNN、 LSTM 和 MLP 模型提出的 DCLSTM-MLP 深度学习组合模型。
本文将 比较贝叶斯、RidgeClassifier 和 fastText在新闻文本分类中的分类效果。朴素贝叶斯假设每个属性独立地对分类结果产生影响 [8]。RidgeClassifier 使 用最小二乘损失来适应分类模型 [9]。fastText[10] 通过学 习单词特征进行文本分类。通过实验比较,从算法理论 层面分析了算法产生性能差异的原因,给出了应用建议。
1 分类器原理
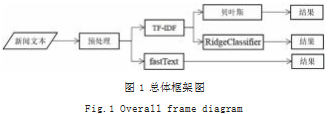
本文使用 TF-IDF+ 贝叶斯、TF-IDF+RidgeClassifier 和 fastText 模型对新闻文本进行分类研究,总体框架 如图 1 所示。
1.1 文本表示技术
计算机无法直接处理自然语言的文本,需要对输入 的文本信息进行合适的数值化表征,即文本表示技术。 文本表示技术包含基于词频的词袋模型、基于 TF-IDF 的词袋模型、Word2Vec 词向量等,本文采用基于 TF- IDF 的词袋模型。
TF-IDF(Term Frequency-Inverse Document Frequency,词频 - 逆文档频率 ) 可用于评估某个词对 所在文档的重要程度,若其在此文档中出现的频次较高 且在其他文档中出现的频次越低,则表示这个词更能代 表此文档。
TF(Term Frequency,词频 ) 表示某个词在某一文 档中出现的频率,具体的公式如下。
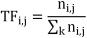
其中,TF
i,j 表示第j 篇文档中的第 i 个词的 TF 值, n
i,j 表示第j 篇文档中第 i 个词的出现频词, ∑
kn
i,j 表示 第j 篇文档中所有词的出现频次,k 表示第j 篇文档中 的词汇总数。
IDF(Inverse Document Frequency, 逆 文 档 频 率 ) 与某词在综合语料库中出现的频率相关,是在词频 的基础上,为每个词设置一个权重,如果这个词在这 篇文档中出现的频次较高且在其他文档中出现的频次较 低,那么这个词的权重较大 ;相反地,如果这个词在大 量的文档中出现,则说明它不能很好地代表所在文档的 特征,权重应设置的较小,公式如下。
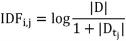
其中,IDF
i,j 表示第j 篇文档中第 i 个词的 IDF 值, |D| 表示语料库中文本的总数,|D
tj| 则表示语料库中含 词 t
i 的文本数量,为了防止分母为零的情况(即该词在语料库中不存在),取 1+|D
tj| 作为分母,取对数是为了防止
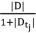
太小而不便于计算。
第j 篇文档中第 i 个词的 TF-IDF 值如下公式所示。
TF_IDF
i,j=TF
i,j ×IDF
i,j
1.2 贝叶斯分类器
朴素贝叶斯算法基于贝叶斯定理以及特征条件独立 假设,即假设每个属性对结果的作用都是独立的。其基 本思想是 :求出测试样本属于各个类别的概率,将概率 最大的那个类别认定为测试样本所属的类别。
设 x={a
1,a
2,...,a
m} 为一个待分类项,而每个 a 为 x 的一个特征属性。有类别集合 C={y
1,y
2,...,y
n} 计算每个 y 在 x 基础的概率分布,P(y
1 |x),P(y
2 |x),...,P(y
n |x) 如果 P(y
k |x)=max{P(y
1 |x),P(y
2 |x),...,P(y
n |x)}, 则 x ∈ y
k[10-11] 。 假设每个属性是独立的,根据贝叶斯定理我们可以得到 训练集中的条件概率,公式如下。
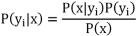
因为对于所有的类别来说 P(x) 都是相同的,所以 只需要求得 P(x|y
i)P(y
i) 的最大值。基于属性条件独立性假设,得到如下公式。
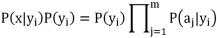 1.3 RidgeClassifier 分类器
1.3 RidgeClassifier 分类器
RidgeClassifier 分类器使用惩罚最小二乘损失来 适应分类模型 [9]。该分类器首先将二进制目标转换为 {-1,1},然后建立一个回归模型来预测目标变量,损失 函数是 RMSE+L2 Penality, 如果 回归的预测值大于 0,则将其预测为正类,否则为负类。对于多分类问题, 将问题视为多输出回归,预测类对应的输出值最大 [12]。 岭系数 (Ridge Coefficients) 使 Penality 的残差平方和 最小化,公式如下所示。
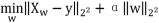
其中, α ≥ 0, α 是一个控制收缩范围的复杂度参数 : α 值越大,收缩量就越大,因此系数对共线性更稳健 [13]。
1.4 fastText 分类器
fastText 可以训练词向量并提供了文本分类模型。 其核心思想是 :将 N-gram 集合中字符对应向量与词汇 本身向量相结合来表示某个词,然后使用结合后得到的 向量做 softmax 多分类。整个模型分为三个部分 :模 型架构、层次 softmax 和 n-gram 特征 [14]。
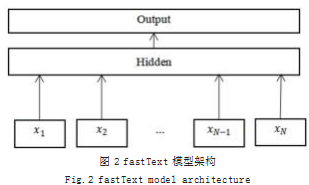
(1)fastText :fastText 模型架构如图 2 所示。
第一层的 x
1,x
2,...,x
N-1,x
N 是表示新闻文本信息的 n-gram 向量 ;第二层是隐藏层,对 n-gram 词向量求 平均得到特征词 ;第三层是分层 softmax。
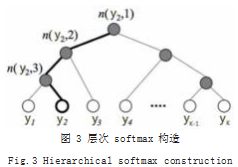
(2) 层次 softmax :层次 softmax 的构造如 图 3
分层 softmax 是根据所有类别的频率构造的哈夫 曼树,所有的叶子节点代表了 K 个不同的类别。每个 节点对应从根节点到该点的概率,从根节点到某个叶子 节点的路径长度为 L(y
j)。在计算 y=j 时的 softmax 值 P(y=j) 时,只需要计算一条路径上所有节点的概率。所 以 P(y=j) 的求解公式如下。
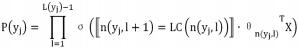
其 中,σ( · ) 表 示 sigmoid 函 数,LC(n) 表 示 n 节点的左孩子,
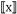
表示
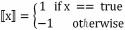
, θ
n(yj,l) 表示
中间节点 n(y
j,l+1) 的参数,X 是 softmax 的输入。
(3)n-gram 特征 :n-gram 的核心思想是将单词 当做一个由字符构成的序列来提取 n 元语法。例如,当 n=3 时,“apple”的 N-gram 为“ap”“pp”“pl”“le”“ap p”“ppl”“ple”。
2 数据集及预处理
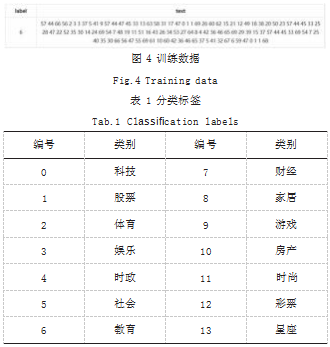
本文采用 Datawhale 与天池联合发起零基础入门NLP - 新闻文本分类挑战赛提供的新闻数据,共选取了 14 个类别 :财经、彩票、房产、股票、家居、教育、 科技、社会、时尚、时政、体育、星座、游戏、娱乐, 其中 19.5 万条用于训练,5 千条用于测试,共 20 万条样本。
新闻文本按照字符级别进行了匿名处理,处理后的 训练数据如图 4 所示,在数据集中标签的对应关系如表1 所示。
为了比较三种算法的效果,在同一个数据集上对三 种算法进行实验并对其结果进行分析比较。
3 实验结果分析
3.1 评估指标
文本分类中常用的性能评价指标有精确率(Precision)、 召回率(Recall)和 F1 值等。
假设 P(Positive) 表示正例样本 ;N(Negative) 表示负例样本 ;T(True)表示预测为正 ;F(False) 表示预测为负。因此,TP,FP,FN,TN 的含义如下 :
TP :被模型预测为正的正例样本 ;
FP :被模型预测为负的正例样本 ;
FN :被模型预测为负的负例样本 ;
TN :被模型预测为正的负例样本。
精确率(Precision)指所有被预测为正例样本中 被正确预测的样本比例,其公式为 :
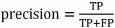
召回率(Recall)指所有正例样本中被预测为正例 的样本比例,其公式为 :
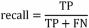
F1 值是精确率和召回率的加权调和平均,其公式为 :
 3.2 实验结果与分析
3.2 实验结果与分析
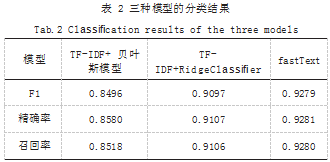
本文基于 NVIDIA Tesla GPU,Python 3 的实验 环境,利用精确率、召回率和 F1 值评价指标对分类效果进行对比分析。结果如表 2 所示。
由表 2 可知贝叶斯模型的分类效果相较于其他两 种 模 型 而 言 表 现 较 差。RidgeClassifier 和 fastText 的效果差异并不明显。贝叶斯模型的各类指标基本在 80% 左 右,RidgeClassifier 的 各 类指标基 本 在 91% 左右,fastText 的各类指标在 92% 左右。贝叶斯模型 比其他分类模型快,但其不能学习不同特征之间的相 互作用,因此对于特征关联较多的分类问题效果不理 想。RidgeClassifier 模型可以通过施加惩罚来调整模 型。fastText 模型专注于文本分类,在精度上往往能 与深度网络相媲美,但在训练时间上却大大少于深度 网络。综上所述,可以看到 fastText 的效果略微优于 RidgeClassifier 模型。
4 结论
本文采用 Datawhale 与天池联合发起零基础入 门 NLP - 新闻文本分类挑战赛提供的新闻数据对贝叶 斯 模 型、RidgeClassifier 模 型 和 fastText 模 型 进 行 了分类实验。对于贝 叶斯模型和 RidgeClassifier 模 型,选择 TF-IDF 模型表示特征向量,分别实现文本分 类 ;对于 fastText 模型利用开源 fastTxet 实现文本分 类。三种算法均可以实现新闻文本自动分类的任务。通 过实验数据的综合对比,可以观察到 fastText 算法模 型在精确率、召回率和 F1 值上表现优于贝叶斯模型和 RidgeClassifier 模型,F1 值达到 92%。新闻文本分类 具有广阔的应用前景,未来将会更多地与大数据、多媒 体结合,如何处理更高维度的海量数据将是一个非常具 有研究价值的方向。
参考文献
[1] 张建,严珂,马祥.基于神经网络的复杂垃圾信息过滤算法分 析[J/OL].计算机应用:1-8[2021-10-09] .http://kns.cnki.net/ kcms/detail/51.1307.TP.20210716.0959.003.html.
[2] 李明哲.基于Tor网站文本内容和特征的分类方法[J].网络安 全技术与应用,2021(8):36-39.
[3] 柳致远,范永胜,张万里,等.常见中文社交平台中网络欺凌 语言的检测分析[J]. 西南师范大学学报(自然科学版),2021,46(8):86-94.
[4] 胡盼盼.自然语言处理从入门到实战[M].北京:中国铁道出 版社有限公司,2020.
[5] 王彬,司杨涛,付军涛.基于改进的TF-IDF和贝叶斯算法的新 闻分类[J].科技风,2020(31):9-10.
[6] 付静,龚永罡,廉小亲,等.基于BERT-LDA的新闻短文本分类 方法[J].信息技术与信息化,2021(2):127-129.
[7] 宋英华,吕龙,刘丹.基于组合深度学习模型的突发事件新闻 识别与分类研究[J].情报学报,2021,40(2):145-151.
[8] 周志华.机器学习[M].北京:清华大学出版社, 2016.
[9] Tatiana C,N.R N,Ranjeeta B,et al.A new robust kernel ridge regression classifier for islanding and power quality disturbances in a multi distributed generation based microgrid[J].Renewable Energy Focus,2019,28(3): 78-99.
[10] 张超超,卢新明.基于fastText的新闻文本多分类研究[J]. 软件导刊,2020,19(3):44-47.
[11] 祁小军,兰海翔,卢涵宇,等.贝叶斯、KNN和SVM算法在 新闻文本分类中的对比研究[J]. 电脑知识与技术,2019,15(25): 220-222.
[12] Peng C,Cheng Q.Discriminative Ridge Machine:A Classifier for High-Dimensional Data or Imbalanced Data[J].IEEE transactions on neural networks and learning systems,2020,PP.
[13] 郁振庭.基于神经网络的词法分析研究[D].南京:南京大学, 2017.
[14] 王钟浩,崔珂玮,张鑫,等.基于fastText的地震信息文本分 类方法[J].现代信息科技, 2021,5(03):5-8.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/34762.html