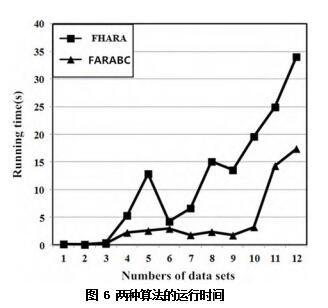
表 3 的折线图如图 6 所示。
Sonar 0.19 58,1,45,37,17,13
,10,19
Ionosphere 0.18 1,5,27,12,24,9,
34,3,8,7,17
58,1,45,37,17,13,
10,19
1,5,27,12,24,9,
34,3,8,7,17
Libras movement
0.03 56,83,18,13 56,83,18,13
WDBC 0.1 23,8,22,25,29,19
,10
23,8,22,25,29,19,
10
Credit Approval
0.16 14,7,10,2,6,5,8,3
,9,4,11,1,13,12
14,7,10,2,6,5,8,3
,9,4,11,1,13,12
对比两种算法运行时间的折线,可以看出
FARABC 算法折线整体处于 FHARA 算法折线的下方,这表明 FARABC 算法比 FHARA 算法具有更少的时间开销。其次,相较 FARABC 算法,FHARA 算法折线波动大,这说明 FHARA 算法的效率受样本分布的影响,这点符合 3.3 节性能分析中的结论。
两种算法的度量计算的总次数如表 4 所示。
表 4 算法的度量计算次数 次
表 4 的柱状图如图 7 所示。
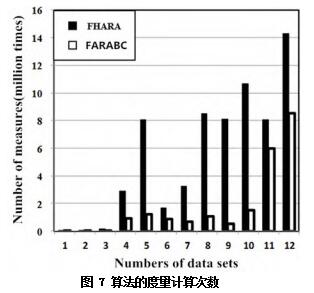
图 7 算法的度量计算次数
通过计算次数的对比,我们发现 FARABC 算法能明显地减少约简过程中度量计算的次数。
据上可知,和 FHARA 算法相比,FARABC 算法能有效且更快速地得到数据集的属性约简。
5.2.3FARABC 算法的效率
由于运行时间受系统误差的影响,且度量计算次数直接影响着算法的时间开销,本部分的分析建立在两种度量计算的次数上。对于各数据集,将其在 FARABC 算法下得到的计算次数除以其在
FHARA 算法下得到的计算次数,用得到的比值表示 FARABC 算法相对于 FHARA 算法的效率,其比值越低,说明 FARABC 算法的效率越高。将数据集按照类别数的大小进行升序排列,如表 5 所示。
表 5 度量计算次数的比值(单位:%)
编号 数据集 类别数 比值
1 Sonar 2 31.70
2 Ionosphere 2 15.17
3 WDBC 2 20.76
4 Credit Approval 2 12.49
5 German Credit 2 6.71
6 Iris 3 19.73
7 Wine 3 28.75
8 CMC 3 14.09
9 Zoo 7 82.39
10 Segmentation 7 73.67
11 Libras movement 15 50.42
12 Abalone 28 59.79
表 5 折线图如图 8 所示。
图 8 FARABC 算法的效率与 N 的关系
分析图 8 折线图可知,相对来说,前 8 个数据集的类别数 N 较小,其比值也较小,后 4 个数据集的类别数 N 较大,其比值也较大。
不失一般性地,通过以上分析可知:数据集的类别数 N 较小时,度量计算次数的比值较小,即FARABC 算法相对 FHARA 算法的效率较高。这说明FARABC 算法对类别数较少的数据集进行属性约简的效率最高,这点符合 3.3 节性能分析中的结论。
将前 8 个数据集得到的比值取平均值得 18.68, 由此得出结论:相比 FHARA 算法的时间开销,FARABC 算法的时间开销最好能缩减 5 倍左右。
5.3 实验结论
上述结论即证明,基于样本类别的正域计算能有效且更快速地得到数据集的属性约简,且对类别数较少的数据集进行计算时效率最高。
6结束语
本文提出了在邻域粗糙集的正域计算中,同类别样本间的度量计算对正域计算是无贡献的这一结论,进而提出了基于样本类别的正域计算。实验证明了该正域计算有效且更快速,但同时也分析了其适用的范围。对于基于邻域粗糙集的算法,特别是对于因迭代次数多、计算量大而造成时间开销大的算法,在处理样本类别数较少的数据集时都可以采用该正域计算进一步缩减算法的时间开销,优化算法的性能。针对类别数较多的数据集,如何进一步提高基于样本类别的正域计算的效率,我们将在后续的工作中对此问题进行研究。
参考文献:
[1]Pawlak Z, So-Winski R. Rough set approach to mul- ti-attribute decision analysis[J]. European Journal of Op- erational Research, 1994, 72(3): 443- 459.
[2]Zadeh LA. Towards a theory of fuzzy information granu- lation and its centrality in human reasoning and fuzzy logic[J]. Fuzzy Sets and Systems, 1997, 90(90): 111-127.
[3]Lin TY. Granular Computing on binary relations I:Data mining and neighborhood systems[J]. Rough Sets in Knowledge Discovery, 1998, 18(1):107-121.
[4]Hu Q, Yu D, Liu J, Wu C. Neighborhood rough set based heterogeneous feature subset selection[J]. Information Sciences,2008,178(18):3577–3594.
[5]王国胤. Rough 集理论与知识获取[M].西安:西安交通大学出版社, 2001:147—156
[6]胡清华,赵辉,于达仁.基于粗糙集的符号与数值属性的
快 速 约 简 算 法 [J]. 模 式 识 别 与 人 工 智 能 ,2008, 21(6):730-738.
[7]胡清华,于达人.应用粗糙计算[M].北京:科学出版社, 2012.
[8]Liu Y, Huang W, Jiang Y, Zeng Z. Quick attribute reduct
algorithm for neighborhood rough set model[J]. Infor- mation Sciences, 2014, 271(7): 65-81.
[9]刘勇,熊蓉,褚健. Hash 快速属性约简算法[J].计算机学
报, 2009, 32(8): 1493-1499.
[10]Meng Z, Shi Z. A fast approach to attribute reduction in incomplete decision systems with tolerance relation-based rough sets[J]. Information Sciences An International Journal, 2009, 179(16):2774-2793.
[11]刘遵仁,吴耿锋.基于邻域粗糙模型的高维数据集快速约简算法[J].计算机科学,2012,39(10):268-271.
《基于样本类别的邻域粗糙集正域计算》附论文PDF版下载:
http://www.lunwensci.com/uploadfile/2018/0811/20180811055436266.pdf
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/442.html