SCI论文(www.lunwensci.com):
摘要:在现代科学技术快速发展的背景下,人们在人工智能方面的研究越来越深入,深度学习的语音识别则是其中十分重要的一个。现阶段传统语音识别系统存在语音识别技术难以达到显著改善、语音识别系统不能够精准提取数据特征两方面问题,为了提高人工智能深度学习背景下语音识别效果,需要强化语音识别系统对特征的识别、重视语音识别模拟练习、增加声学与运动学特征改善语音情感识别。
关键词:人工智能;深度学习;语音识别;方法
Research on Speech Recognition Methods under the Background of Artificial Intelligence Deep Learning
GU Yawen
(Institute of Artificial Intelligence and Information Engineering,Jinken College,Nanjing Jiangsu 210000)
【Abstract】:In the context of the rapid development of modern science and technology,people's research in artificial intelligence is getting more and more in-depth,and deep learning speech recognition is one of the most important ones.At this stage,the traditional speech recognition system has two problems:The speech recognition technology is difficult to achieve significant improvement,and the speech recognition system cannot accurately extract data features.In order to improve the speech recognition effect under the background of artificial intelligence deep learning,it is necessary to strengthen the speech recognition system.Emphasis on speech recognition simulation exercises,adding acoustic and kinematic features to improve speech emotion recognition.
【Key words】:artificial intelligence;deep learning;speech recognition;method
0引言
在大数据、物联网以及云计算等信息技术飞速发展的背景下,基于深度学习的人工智能技术也得到了快速发展,并实现了从理论研究层面向实际应用层面的巨大转变,同时在人工智能技术的支持下,语音识别系统也从以往的“不能用”发展成为“可以用”,展现了非常高的应用价值与良好的发展前景[1]。现阶段从当下语音识别系统应用现状来看,尽管有越来越多的语音识别系统已经可以完成人与机器之间的对话,然而仍然有较多的语音识别系统不健全。所以为了进一步提高语音识别系统技术水平,能够将基于人工智能的深度学习应用到其中,有效改善语音识别系统对语音、语义等识别的精准性与有效性。于此同时,在实际研究工作中,开发人员还能够全面认识到理论研究结果与实际应用之间的明显差异性,了解具体应用中的主要问题,正确把握研究成果能否符合当下人们对语音识别系统的应用需求。将深度学习融入到语音识别系统中,主要是为了提高语音识别系统的实用性,让语音识别系统可以很好的满足现代人们的使用需求。
1语音识别发展概述
现阶段,语音情感识别方面主要面临两个方面问题,分别是怎样切实可行的界定和分类情绪、怎样创设情感模式。其中针对构建情感模式的问题,当下研究领域中主要分为了两大类情感描述模型,分别是离散情绪模型以及连续情绪模型[2],这两者在二维空间的具体分布状况如图1所示。
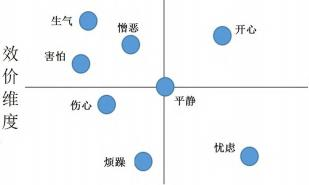
图 1 在二维空间上的情感分布示意图
在离散情绪模型中包含了多种情绪类型,比如说生气、开心以及平静等,因为人类情绪状况有着高度的复杂性,在开展离散情绪模型研究工作中,必须要将人类基本情绪状况当成是各项研究的基础。依照该研究原则,能够将人类情绪划分为主情绪与次情绪,这两种情绪中主情绪是人类群体所共同拥有的。此外,也能够将人类情感划分为基本情感与辅助情感,其中基本情感又可以再次划分为高兴、恐惧、轻视以及吃惊等,而辅助情绪是基本情绪的组合。从而能够看出,人们在进行情感分类过程中往往都会遵循特定的标准,并且大部分人都认可将悲伤、幸福以及愤怒规划为人类主要情感中[3]。
伴随着现代科学技术水平的快速发展,以往的语音识别模式已经不能够当代人们的使用需求,尽管在以前一些智能机器安装有语音识别软件,可以进行简单的人机对话,然而在算法等方面,语音识别技术遇到了非常大的障碍,很难进一步发展。在后续开展语音识别研究工作中,应当要重点开展语音信号发生、传输等方面的深入探究,推动语音识别技术的进一步发展。
2当下传统语音识别系统问题分析
2.1语音识别技术难以达到显著改善
尽管当下社会处于不断发展时期,然而在语音识别研究领域遇见了非常大的困难,很好获得实质性的进展。当下不管是智能手机还是智能机器人等都大量安装了语音识别系统,能够实现一些简单的人机交流,然而机器终究还是机器,即便可以识别语音也只可以识别一些简单、基础性的语音。而对于一些行业领域的专业术语则无法做到准确识别与理解[4]。针对该问题,相关开发人员在许多方面进行完善与创新,并使得语音识别系统在进行知识理解时能够实现对部分外语和方言的识别。然而怎样处理好噪声、系统鲁棒性以及语音复杂模型等部分依旧面临较大困境,还需要不断研究与完善。
2.2语音识别系统不能够精准提取数据特征
当下互联网技术得到了飞速发展,越来越多的设备开始连接到互联网中,智能系统慢慢成为了当下社会的主流,语音识别系统便是该主流中非常关键的研究成果。开发人员在实际开展语音识别研究工作过程中,往往会基于不同途径获取不同的语音数据,并对其进行全面分析与探究。然而该语音数据通过传统模式不能够实现语音识别系统的精准数据特征提取。换言之,在以往语音识别过程中,一般是通过人工实现特征提取,并开展相应的模拟练习,该方式会存在较多的人为因素,不仅需要投入大量的人力与物力,还难以达到较高的稳定性。深度神经网络能够实现特征的自主提取,并且在当下大数据处理中有着广泛的运用,为此依托于深度学习实现特征精准提取,并发展成为真正的人机交互是现阶段语音识别技术发展的重要方向[5]。
3人工智能深度学习背景下语音识别方法
3.1强化语音识别系统对特征的识别
语音识别系统中精准识别语音信号特征是开展后续工作的重要基础,其作用是促使语音信号中涵盖的各种信息实现量化,获取可以象征语音符号本省的特征,进行接下来的声学模型探讨与研究[6]。深度学习最早在图像识别领域得到了广泛运用并取得了较为理想的效果,之后将其引入到语音识别研究领域中,相比较于传统模式其也表现出非常大的应用潜力与优势。深度学习中有别于传统方式的训练模式能够为神经网络带来有效的初始权重与偏重,进而确保神经网络在进行实际训练中不会受困于局部最优解,并最终收敛于适宜的极限点[7]。深度神经网络能够获取到深度特征,确保在降维之后原有信息不会发生改变,拥有非常好的音素识别率。依托于神经网络对数据的深层次映射表达,能够挖掘到较多表征初始数据的深度本质属性,进而达到改善语音识别系统水平的目的。
3.2重视语音识别模拟练习
语音识别系统在获取外界语音信息之后,对其进行相应的预处理,之后深度神经网络依托于处理好的语音开展模拟练习,因为具有较多层次的网络模型,网络架构十分繁琐,在实际练习中要不断的进行不同参数的优化,为了有效防范神经网络反复作用于局部最优解与过拟合问题,需要引入自编码器模型。在开展语音识别模拟练习过程中,其根本目的是为了确保语音识别系统能够精准提取到需要的语音特征值,导入庞大语音数据进行反复练习,以此来提高语音系统识别速度与精准性[8]。在将练习模块融入到语音识别系统之后,还需要针对模板库中的文字实施识别操作,将一些较为相近的文字输入到其中,以此来加强语音识别系统中对文字的识别水平,防止产生一些低级别错误。进一步拓展语音识别模式,能够有效改善语音识别匹配程度,提高语音识别的精准性,为此融入语音模块也是实现语音识别系统训练的有效方式之一。
3.3增加声学与运动学特征改善语音情感识别
在现代人工智能技术不断发展背景下,人们对人工交互的期望值越来越高,期望在信息交流中能够融入一些情感,在这种情况下语音情感识别开始增加到语音识别系统中。探究语音中的情感信息同时将特征属性挖掘出来十分困难,依托于语音来获取人们说话的情感本来就存在较多问题点,因此结合人们说话时的面部表情、发音器官等信息,依托于声学与运动学实现语音情感信息提取与识别十分有必要。事实上对发音器官的运动学数据获取难度也非常大,以往的语音情感识别是建立在声学与统计学的基础之上,伴随着当代科学技术手段的提升,面部表情、发声器官等运动逐渐被应用到语音情感识别中。深度学习模块需要有海量数据信息作支撑,将发声器官与声学等运动特征数据加入到其中,能够有效提升样本数据规模,不断改进与调整情感语音识别模型。
4结语
总的来说,现阶段基于人工智能的深度学习语音识别方式还应当要不断完善与创新,从而不断推动人工智能水平的提高。另外,应当要加强对语音识别系统的推动,将其应用到更多行业领域与场景中,并对其语音识别方式进行持续改进,这样才可以真正改善语音识别的准确性,提高语音识别水平。
[1]侯一民,周慧琼,王政一.深度学习在语音识别中的研究进展综述[J].计算机应用研究,2017,34(8):2241-2246.
[2]王山海,景新幸,杨海燕.基于深度学习神经网络的孤立词语音识别的研究[J].计算机应用研究,2015,32(8):2289-2291+2298.
[3]戴礼荣,张仕良,黄智颖.基于深度学习的语音识别技术现状与展望[J].数据采集与处理,2017,32(2):221-231.
[4]彭玉青,刘帆,高晴晴,等.基于微调优化的深度学习在语音识别中的应用[J].郑州大学学报(理学版),2016,48(4):30-35.
[5]房爱东,张志伟,崔琳,等.基于人工智能的语音识别系统及应用研究[J].宿州学院学报,2019,34(8):62-65.
[6]赵涛,张羿,王永和,等.基于深度学习的人机语音交互平台[J].信息系统工程,2019(1):102-104.
[7]熊晓倩.基于人工智能下语音识别方法与装置及系统的研究[J].科技资讯,2018,16(3):17-18.
[8]蒿峰,王小海,庞传军.基于Word2vec的电网调度词汇词向量生成方法及语音识别应用[J].内蒙古电力技术,2020,38(5):72-76.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/41238.html








