SCI论文(www.lunwensci.com):
摘要:如今,随着网络带宽的飞速增长,越来越多的人会倾向于使用视频通话的方式进行沟通。而随着全球新冠疫情的蔓延,为了保持社交距离,许多公司或团体开始依赖使用视频会议的方式开展工作。背景替换技术可以在视频会议的过程中,保护隐私和提高观众的专注度。本文将对两款基于深度学习的图像处理框架,应用在背景替换时的情况,进行对比和分析,并给出了针对于不同场景下如何选择的建议。
关键词:背景替换;视频会议;背景虚化;深度学习;动态背景
Analysis on the Background Replacement Technology in Video Conference
SHAO Xiaowen
(Renmin University of China,Beijing 100000)
【Abstract】:Nowadays,more and more people tend to use video calls to communicate since bandwidth of the internet has grown rapidly.To keep social distance,many companies or groups have begun to rely on video conference to carry out their daily job because the COVID-19 pandemic spread quickly.The background replacement technology can protect the privacy and keep the concentration of the audience during video meeting.The article will focus on two types of image processing frameworks based on deep learning.After comparing and analyzing,we will give the proposal on how to choose these two frameworks in various scenarios.
【Key words】:background replacement;video conference;background blur;deep learning;dynamic background
近年来,全世界有着越来越多的公司或团体选择使用了基于互联网的远程工作方式。当新冠疫情在全球蔓延传播时,视频会议成为了连接员工和保持团队居家办公的唯一适用的解决方案。在短短的几个月内,视频会议已经被应用到了我们每个人的各个方面,其中就包括了工作和生活。而除了与工作业务相关的会议外,全球各地的远程团队还在使用视频会议的方式来举办虚拟的生日派对、在线游戏等其他社交活动。这些正式或非正式的在线视频会议,导致了在视频会议场景中,设置动态背景图像需求的增加。对于正式的传统会议中,背景替换技术可以成为保护隐私或提高观众专注度的有效工具。如果是从公共场所或者在家中参加的在线会议,我们希望观众能将注意力保持在说话人的身上,而不是每个人的背景上。这时,可以使用背景替换技术对背景进行模糊,甚至替换为其他图片的处理方式。而对于非正式的聚会,使用虚拟动态背景也可以让整个会议或聚会的过程更加地欢乐有趣,具有更好地沉浸感。
1背景替换技术的简介
背景替换技术是指从一段视频中分别提取出前景和背景并与新背景进行合并的计算机图形学技术。这是一个非常具有挑战性的任务,由于人眼会对背景替换中产生的视觉错误极其敏感,这导致了前/背景的分离切割算法需要特别地精确,以达到逼真的效果。对于这项技术的研究已经有超过20年的发展历史,早期的方法是需要通过增加限制条件来协助解决,例如限制背景颜色的色键扣图方式,俗称为绿幕抠像[1]。由于在背景处使用了单一颜色,这种辅助方法可以有效地提高计算机算法识别背景的能力,从而达到精确分离前/背景的目标[2]。但是在现实生活中,视频中的背景非常复杂多变,不太可能是单一的纯色背景,所以基于复杂背景的分离技术,开始进入人们的视野中。
对于复杂动态背景的切分方法,主要存在两种主要的思路:基于光流的方法和基于运动估计的方法。这其中要么算法速度运行较慢,无法满足视频中实时运行的需求,要么则需要利用特殊摄像头或者双摄像头作为硬件进行输入,对运行环境要求过高。近年来,由于机器深度学习的迅猛发展,可以通过算法让计算机提前进行大量图形的训练学习。这样做以后,使得算法无论从识别速度、识别质量及性能要求,都有了很大的提高,并且大部分学习模型均可在现代网页浏览器中进行实时分割。本文将选取两种不同的使用了机器预学习分割模型的框架,分析其不同的实现原理和实验结果对比。
2动态背景替换技术的实现
2.1 BodyPix
2.1.1 BodyPix的简介
BodyPix是一款基于开源机器学习模型的计算机视觉处理框架。它可以直接应用在图像或者视频上,目的是将人物或者人体身体部位从背景中进行分割[3]。该框架是基于TensorFlow.js,从而可以在浏览器中直接运行。经过训练的BodyPix模型可以对人体和其二十四个身体部位(例如左手、右前小腿或者背部躯干等部位)执行分类。换句话说,BodyPix可以将图像的像素分为:代表人物的像素和代表背景的像素。其中,对于人物来说,还可以再归类到二十四个身体部位中的任何一个。
2019年,TensorFlow发布了第一代BodyPix,这是一款无需任何附加硬件,仅需一个普通视频摄像头,即可完成人体身体识别的框架。采用了预先训练好的模型,使得使用者无需花费高昂的时间和金钱成本去训练自己的模型。由于所有的分析都发生在用户本地,对个人隐私也起到了有力地保护。2021年,BodyPix的V2版本发布。该版本在之前的基础上,由原来只能支持单人识别扩展到了多人同时识别,并开始支持MobileNet和ResNet两款模型切换选择。对于拥有更强大GPU的计算机来说,可以选择更加准确的但运行代价更高的ResNet模型,而对于移动设备或者标准的消费级计算机来说,可以使用MobileNet从而实现更高效的运行。
2.1.2 BodyPix的原理
BodyPix使用了卷积神经网络算法,研究者分别训练了ResNet模型和MobileNet模型。由于MobileNet模型已经开源并可以在移动设备和消费级计算机中高效运行,本文将以MobileNet作为默认选择使用的模型。对于MobileNet模型,BodyPix使用了一个1×1的卷积层替代了传统分类模型中的末尾池和全连接层。
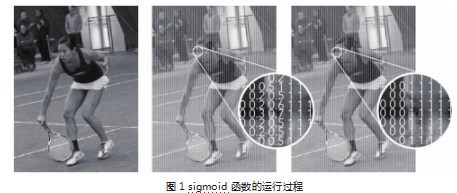
(1)人体分割。BodyPix的核心算法是人物分割,换句话说,就是对输入图像的每个像素执行二元决策,以确定这个像素是否属于人物。它的工作原理是:当一个图像导入至MobileNet网络后,sigmoid激活函数将输出值转换成0和1之间的某个数值,该值可以表明此像素点是否属于人物的可能性概率。分割阈值(例如0.5)用来判断可能性概率是否可以算作为人物,并将值从概率转换为一个确定性的二元值,也就是0或者1。下面的数据展示了算法如何应用到一张图像上。从左到右为:一张输入图像、在sigmoid函数后的预测概率以及根据阈值进行的二元判断的结果。(见图1)
(2)身体部位分割。为了评估身体不同部位的分割,研究者使用了相同的MobileNet方法。不同的是,这次会通过预测一个额外的24通道输出张量P来重复分割过程,其中24是身体不同部位的编号。每个通道都对是否属于某个身体部位的概率进行编码。具体来说,身体部位分割的任务可以表示为多通道的基于每个像素值的二元决策问题。对于每个部位通道,1表示一个像素属于此部位区域,0表示一个像素不属于该部位,输出张量P中有24个通道,因此需要在24个通道里面找到最优的部分。在推理计算的过程中,对于身体部位张量P的每个像素位置(u,v),根据以下的公式可以选择到可能性最高的body_part_id。
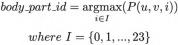
在运行后,得到的结果将会是一个和输入图像大小一样的二维图像,每个像素点都包含了一个整数,代表其具体的部位编号。通过将此编号设置为-1,还能将图像中的背景进行剔除。
2.1.3 BodyPix的使用
BodyPix的使用可分为三个主要步骤,它们是:
(1)设置输入源,并设置对应的分割模式和不同参数。这个环节需要注意的是,不同的参数将带来结果准确性和运行效率的差异。
(2)输入模型后,获得相应的数据结果。由于存在人物分割或者身体部位分割两种,所以得到的结果根据不同的模式也会略有不同。
(3)根据实际应用的需要,可以选择不同的数据应用。例如,如果需要实现背景去除或者模糊效果,可以使用数据进行遮罩层的重绘。如果仅仅需要标记身体的不同部位,也可以只用透明颜色块覆盖在原有图像之上。
2.2 MediaPipe
2.2.1 MediePipe的简介
MediaPipe是一款由谷歌开发并开源的数据流处理机器学习应用开发框架。它是一个基于图的数据处理管线,用于构建使用了多种形式的数据源,如音视频、传感器数据或者任何时间序列数据。使用MediaPipe,可以将机器学习任务构建为一个图形化模块表示的数据流管道,包括推理模型和流媒体处理功能。其提供的背景建模技术使用了Web ML技术,可以直接在用户个人浏览器中使用,开发这些特性的关键目标是在几乎所有现代设备(PC、移动端、服务器、嵌入式设备等)上提供实时的背景模糊和替换功能。这项技术是通过结合高效的设备端ML模型、基于we-GL的渲染技术以及通过XNNPACK和TFLite实现的基于Web的机器学习推断来实现的。
2.2.2 MediaPipe的原理
(1)Web ML技术方案概览。这项特性是由Media-Pipe开发的,用于实时流媒体的跨平台定制机器学习解决方案,它还支持诸如设备上实时的手部、虹膜和身体姿势跟踪等机器学习解决方案。由于任何终端设备上解决方案的核心需求都是实现高性能。为此,MediaPipe的Web管道利用了WebAssembly,这是一种专门为浏览器设计的底层二进制代码格式,可以有效地提高运行速度,尤其针对于那些具有庞大计算需求的任务。在运行时,浏览器会将WebAssembly指令转换为本地机器码,执行速度比传统的JavaScript代码快得多。此外,Chrome最近引入了对WebAssembly SIMD的支持,可以用每条指令处理多个数据点,这使得性能提升了2倍以上。其背景建模的解决方案是,首先利用算法处理每个视频帧,计算一个低分辨率掩膜,将用户从背景中分割出来。然后,进一步对掩膜进行优化,使其与图像边界保持一致。然后通过WebGL2使用这个掩膜渲染输出视频,从而达到背景模糊或替换的目标。
(2)分割模型的技术细节。在终端设备上的机器学习模型,一般需要超轻量级,以实现快速推理、低功耗和较小的模型存储。对于在浏览器中运行的模型,输入分辨率极大地影响了处理每个帧所需的浮点操作的数量,因此也需要很小。在将图像输入到模型之前,框架将其下采样到较小的尺寸。整体分割网络在编码器和解码器方面具有对称结构,解码器模块与编码器块模块共享对称层结构。具体来说,在编码器和解码器两个模块中都采用了有全局平均池化的信道,这对于CPU的高效推理是非常有利的。谷歌修改了MobileNetV3-small作为编码器,为了将模型尺寸减少50%,使用float16量化将模型导出到TFLite,结果精度略有下降,但对质量没有明显影响,得到的模型有193K个参数,大小只有400KB。
(3)渲染效果。一旦分割完成,框架使用OpenGL着色器进行视频处理和效果渲染。在精细化阶段,框架使用一个联合双边滤波器来平滑低分辨率的遮罩。模糊着色器根据分割的值按比例调整每个像素的模糊强度,以模拟背景虚化效果,类似于光学中的模糊圈。像素由它们的模糊圈半径加权,这样前景像素就不会渗入背景。框架使用可分离滤波器实现加权模糊,而不是用流行的高斯金字塔,原因是它可以消除人周围的晕轮效应。为了提高效率,模糊是在低分辨率下执行的,并与原始分辨率输入帧进行混合。对于背景替换,框架采用了一种称为光线包装的合成技术,用于混合分割的人像和定制的背景图像。光线包装有助于柔化分割边缘,允许背景光线溢出到前景元素上,使合成更加身临其境。
当前景和被替换的背景之间有很大的差异时,这也有助于最小化晕轮效应。
2.2.3 MediaPipe的使用
MediaPipe通过将各个感知模型抽象为模块并将其连接到可维护的图中来解决这些问题,可以将数据流处理管道构建为模块化组件图,包括推理处理模型和媒体处理功能。将视频和音频流数据输入到图中,通过各个功能模块构建的图模型管道处理这些数据,如物体检测或人脸点标注等,最后结果数据也可从图输出。这些功能可以帮助开发者专注于算法或模型开发,并使用MediaPipe作为迭代改进其应用程序的环境,其结果可在不同的设备和平台上共享。除了上述的特性,MediaPipe还支持TensorFlow和TF Lite的推理引擎,任何Tensor-Flow和TF Lite的模型都可以在MediaPipe上使用。
MediaPipe提供了MediaPipe Visualizer在线工具,它帮助开发者了解其计算单元图的结构并了解其机器学习推理管道的整体行为。这个图预览工具允许用户在编辑器中直接输入或上传图形配置文件来加载(见图2)。
3实验结果及性能对比
实验环境:实验软件环境为macOS Catalina(10.15.7),64位操作系统,并使用Google Chrome 91进行程序运行测试。实验的硬件环境是,CPU使用了Intel Core i9 2.8GHz 8核,显卡则为Intel UHD Graphics 630。
实验参数:实验中选择了当下流行几种标准的摄像头采样分辨率,以4:3作为长宽比。模型上则按照两款框架的默认选择,分别对应地使用了MobileNetV1和MobileNetV3,其他参数则全部使用默认配置。
实验数据:实验使用了互联网收集的标准人像用例视频库。将视频按照不同的分辨率进行了统一的裁切编码,并全部以MP4文件的形式进行导入。
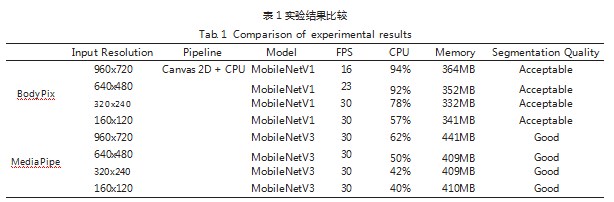
参考标准:关于分割质量,由于分割质量无法清晰准确地使用数据进行标准量化,所以使用视频同一帧进行对比的方式,并以分析判断的方式给出一个大致的质量结果。在硬件指标上,则选择FPS帧率、CPU占用百分比和内存占用情况来综合判断(见表1)。
结论分析:通过对实验数据的分析,MediaPipe在不同分辨率的情况下,帧率都可以保持在30FPS,这使得视频非常流畅平滑,而BodyPix则会根据分辨率的不同而改变,当分辨率小于640x480后,视频也可以较为流畅的播放;但如果高于,则会出现一定的掉帧卡顿现象。对于CPU的占用率来说,同等分辨率的情况下,MediaPipe也比BodyPix更为优异。内存使用上,两者相差不大,且不会根据不同的分辨率有较大的波动起伏。对于最终的分割质量上,根据对比不同帧的分割,MediaPipe在边缘的分割处理上,效果优于BodyPix,使得人物的边缘更加平滑和自然。从左到右为:原始图像,MediaPipe分割,BodyPix分割(见图3)。
4结语
本文通过研究横向对比两款不同类型的主流计算机视觉领域的机器学习框架,在背景替换技术中的应用效果,得到了具体细节的对比数据结果。根据分析并对比了测试数据和背景替换中的使用效果,BodyPix较为适合应用在进行人物整体或者身体部位的识别和应用,而对于MediePipe相对来说,更加适合视频通话时的背景模糊,在性能上也更为出色。
将机器学习模型应用于计算机图形识别领域,是机器学习的重要应用方向,而提供可以直接运行在移动终端或网页浏览器中的轻量化、高效率的算法框架,也是众多研究者和开发者共同的目标。诚然,这当中还存在一些尚待解决的问题,例如如何去除衣物对算法的干扰,如何解决手部移动时产生的边缘检测失败等。长期来看,准确性及性能优化将会是此类算法在未来一段时间内的重点关注方向。
参考文献
[1]许云鹏.绿幕抠像的前期准备及后期合成技巧[J].记者摇篮,2020(4):103-104.
[2]柯佳明.微课制作结合绿幕抠像技术的研究与应用[J].中国信息化,2021(2):45-47.
[3]李科,毋涛.基于BodyPix的非接触式人体测量[J].国外电子测量技术,2020,39(7):89-93.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/40187.html