SCI论文(www.lunwensci.com):
摘要:针对数据挖掘课程学科交叉、知识点多、教学点分散地特点,以及现有课程教学学时短等问题,提出了一种基于“问题引导+案例分析”的教学模式提高教学质量,并以关联规则章节中的基于用户的协同过滤算法为例,来介绍该教学模式。
关键词:案例;问题引导教学;数据挖掘;教学模式
本文引用格式:覃凤萍,等.基于“问题引导+案例”的数据挖掘课程教学模式设计[J].教育现代化,2020,7(45):169-171.
一引言
随着各行各业技术的发展,这个时代的数据量是已经发生跨越式的增长。(1)天文数据:2000年,斯隆数字巡天项目启动,位于美国新墨西哥州的望远镜收集到的数据快速增长,到了2010年该项目数据量高达1.4×242字节。预计到2025年,全球天文数据采集量将达到每年2.5×1010 TB。(2)互联网数据:但是2017年,淘宝每天产生的数据都高达7TB,如果统计整个互联网数据,数据量将会更大。(3)物联网数据:阿里云预计2020年物联网连接设备将达到200亿台上,物联网中的每台设备都会产生大量的数据。
如此庞大的数据,蕴含着巨大的价值,随着大量数据存储和采集技术的发展,不同的机构都可以较容易地收集到大量地数据,但针对大量数据的信息分析成为一个较为困难的事情。针对大量数据的分析,传统的数据分析技术存在不足,主要体现在对这些大数据无法分析或者处理性能低等。另外,即使有些数据量较小,但也可能因为数据的一些特点,不适用传统的数据分析方法。在这种情况下,大数据技术的出现很好地解决了大量数据的计算问题,针对大量数据的挖掘工作也取得长足的工作。
二 教学现状
数据挖掘(Data Mining)是20世纪80年代出现的一种技术。一般是指从大量数据中通过算法搜索出隐藏其中的信息的过程,并且这个过程是自动的,这些信息的表现形式可以为规则、概念、模型、模式等。数据挖掘是一种综合技术,对业务数据进行处理的过程中,需要用到很多领域的知识,如数据库、统计学、应用数学、机器学习、模式识别、数据可视化、信息科学、程序开发等领域的理论和技术[1]。它的核心是利用算法模型对预处理后的数据进行训练,训练后获得数据模型。
数据挖掘是计算机类的一门专业核心课程,其教学不仅要传授学生学科专业知识,还要培养学生能够将所学的理论知识去构建问题的抽象模型,并在此基础上设计和分析解决实际问题的能力。目前该课程教学过程中存在以下问题。
(1)数据挖掘是一门设计多学科知识的课程,且该课程具有知识点多和教学点分散的特点。该课程在我校整个学期的学时只有48学时,设计的授课内容有数据挖掘的十大经典算法及其应用,如果按照传统的教学方式,授课教师很难在规定的学时内完成所有内容的教授。
(2)目前在数据挖掘课程的实验设置上更多的是数据挖掘经典算法的单独设计和实现,缺少解决实际问题相关的实验,这样学生很难把在课堂上学的各类数据挖掘算法与实际生活联系起来,从而不能对各个行业的海量数据进行分析和挖掘。
三 基于“问题引导+案例”的教学模式优势
基于“问题”的教学方法不像传统教学那样教师在讲台上单一的讲解大量学科知识,而是以实际生活中的各种问题结合教材的知识点以问题的形式呈现给学生,让学生在寻找解决问题的过程中掌握知识,培养技能的一种学习方法[2]。问题引导教学法为了学生提供了一个交流探索的平台,学会思考,学会创造,提高了学生在教学过程中的参与感,促了学生创造思维的发展。数据挖掘课程内容涉及机器学习算法、统计学概率论等知识,对于计算机本科专业的学生来说,学习起来还是有相当难度的,而采用问题引导教学方法,使得学生在问题的解决中有效快速的掌握课程的核心知识。
案例教学是一种新型的,着重关注于学生创新能力和解决问题能力培养的教学方式,以案例为基础、以知识为核心进行教学过程组织的教学模式,有利于提高学生分析问题和解决问题的能力[3]。在案例教学过程中,教师在设计教学内容上要为每一个章节的知识点准备特定的案例,学生根据案例来分析和思考问题,在寻求问题解决方案的过程中去掌握该知识点涉及到的概念、公式、算法等理论知识。一般教师挑选的案例会易于理解和贴近实际问题,这样学生不仅学习到原理而且为他们将来的实践打下基础。由于有了案例的铺垫,当学生走上工作岗位,对真是数据及逆行分析挖掘时,他们能较容易地进行知识迁移,将案例映射到实际问题中。
基于“问题引入和案例”教学法是指在数据挖掘教学的过程中,教师以问题引入的方式来学习每个章节中的经典算法,并把整个算法的实际案例的讲解和处理贯穿整个章节知识教学过程中。采用这样的教学方法可以避免过去对每个章节学习太多算法,从而导致学生所学知识理解不透彻的弊端。通过代表性算法实现具体案例的教学模式,能够把《数据挖掘》课程的知识点具体化,使得学生对知识体系有更深刻的认识,从而能够培养学生正确、全面地认识大数据分析于挖掘过程,为其将来解决现实中地实际问题打下坚实地基础[4]。教师在课堂开始就引入问题,且整个案例围绕着问题来精心设计的,与章节知识紧密相关,能够保持学生的求知欲。整个教学过程中学生都带着问号学习,大大提高了学生学习兴趣。为了提高计算机专业学生的编程能力,我们基于Python语言,选择Anaconda和PyCharm作为开发工具,对数据挖掘技术课程中的关联、分类、聚类和预测挖掘进行教学设计。在每个章节案例讲解完后,学生编程实现该案例,通过此部分的实践,可以有效地提高学生的编程能力同时让学生体会到算法设计对问题求解有效性的评估[5]。
四 课程教学示例
(一)算法及案例设计示例
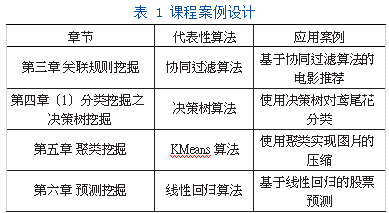
表1为数据挖掘课程部分章节中设置的代表性算法和应用案例,数据挖掘课程的案例设计设置均以此为模板。
(二)教学过程设计
我们以《数据挖掘》课程中的关联规则章节为例,来详细说明基于“问题引导+案例”的教学过程设计。关联规则最初是针对购物篮分析(Market Basket Analysis)问题提出的。假设商店经理需要了解顾客的购物习惯,以及知道顾客在一次购物的同时还会购买哪些商品,这时就需要对顾客的零售物品进行购物篮分析。关联规则就是通过发现顾客放入“购物篮”中的商品之间的关联,分析顾客的购物习惯,物品间的某种联系被称为关联[6]。零售商通过发现该关联从而发现顾客频繁的购买了那些商品,帮助其以后制定更好的营销策略。如果单纯从概念讲解和条件概率计算公式着手教授本节内容,学生很难去理解,很快就对所学知识失去兴趣,而且学完之后,对关联规则的挖掘过程比如第一阶段从资料集合中找到所有的高频项目组和这些高频项目组中产生关联规则的过程可能不会理解得很透彻。协同过滤算法是一种典型的关联规则算法。我们选择一个非常贴近实际生活的案例 如何使用协同过滤算法推荐电影来解释我们的基于“问题导入+案例”的教学设计模式,并在每个教学环节中引入问题来设计教学过程。教学过程见表2。
(1)问题引入。课堂开始,直接跟学生提问题,在平时生活中都喜欢用什么样的APP来听歌呢?是QQ音乐还是网易云音乐?大家在使用这些软件的时候有没有遇到推荐?推荐结果如何?是自己喜欢的吗?大家还在哪些地方见过类似的推荐的?亚马逊或者当当网买书的推荐?豆瓣电影的推荐?头条新闻的推荐?我们选择引入问题的这些应用场景都时学生生活中经常遇到的,这样学生很能产生代入感,他们不由自主地会思考自己平时看一部电影或是在淘宝购物时的决定跟哪些数据相关联。
(2)协同过滤算法。为了了解什么是协同过滤,我们引入一个简单的生活问题来了解该概念:如果现在我们现在想看一部电影,但又不知道具体看哪部的情况下,一般我们会问周围的同事或朋友,他们最近有没有看到好看的电影,有什么值得推荐给我们的,但是朋友有很多,不是每个朋友都去问的,我们一般更倾向于从跟我们兴趣一样的朋友那里问。从而了解基于用户的协同过滤算法是利用具有相同经验的,兴趣相投的群体的喜好来向用户进行推荐他感兴趣的东西。
(3)案例分析。在这里我们具体分析一个案例来了解一下基于用户的协同过滤算法和基于物品地协同过滤算法:假设有A-G,7个人分别看了如图所示的电影并且给电影有如下评分(5分最高,没看过的不评分),我们目的是要向A用户推荐一部电影。首先我们引导学生来理一下思路:我们要基于A看过的电影,向A推荐他未看过的电影我们根据协同过滤的三步来分析这个问题,首先我们根据用户A的评分发现,他偏爱像老炮儿这样性质的电影;然后我们要根据他的爱好找到类似用户;如何寻找类似用户呢?如何找到和用户A一样偏爱老炮儿这种电影的用户呢?从数学的角度出发,我们可以理解为计算两个用户之间的相似度,越相似,证明他们口味越接近。那么问题来了,相似度计算方式很多,我们采用什么样的相似度计算方法呢?
(4)理论回顾。很多同学会说采用效果最好的相似度计算方法,那怎么知道哪种相似度计算方法最好呢?这需要大家在学习和使用过程中去分辨。这里我们使用“欧式距离”作为相似度计算方法。在这一环节我们采用推演的教学方式将欧式距离的理论知识复习了一次,使得学生能进一步回忆起知识点,而不是仅仅简单地列出公式。
(5)映射理论与案例。把每一部电影看成N维空间中的一个维度,这样每个用户对于电影的评分相当于维度的坐标,那么每一个用户的所有评分,相当于就把用户固定在这个N维空间的一个点上,然后利用欧几里德距离计算N维空间两点的距离。距离越短,说明品味越接近。
(6)实验案例。为了能够让学生透彻理解协同过滤算法在电影推荐中的应用,我们给出了该案例具体实现代码,让学生在课堂上自己动手做一做,教师就学生地遇到的问题进行解答,以及点评部分同学的作业。
(7)总结。总结协同过滤算法的大致步骤,帮助学生理清思路,区分基于用户的过滤算法(User-based Collaborative Filtering)和基于物品的过滤算法(Item-based Collaborative Filtering)的特点和不足。基于用户的过滤方法相对容易实现,它的推荐结果主要关注于与用户兴趣接近的小群体和用户的历史兴趣,适合规模小,变化频繁的内存数据集[6]。而基于物品的协同过滤算法主要反映用户自身的兴趣传承,针对大数据集生成的推荐列表的速度快速,且当数据集为稀疏数据时,准确率高。
五 结语
针对数据挖掘课程学科交叉、知识点多、教学点分散的特点,以及现有课程教学学时短等问题,提出了一种基于“问题引导+案例分析”的教学模式。我们将问题引入和案例分析结合起来设计了以关联规则章节中的基于用户的协同过滤算法的整个教学环节,实践证明能够有效地帮助学生更好地理解数据挖掘课程中的经典算法和模型,让学生对常用的python第三方模块sklearn、pandas等有了一定认识。当然课程教学实施的过程中也暴露出了一些问题,有待我们将来进一步改进。
参考文献
[1]梁亚声.数据挖掘原理、算法与应用[C].北京:机械工业出版社.
[2]邓娜,林松,熊才权,等.基于案例和悬念的数据挖掘教学模式设计[J].计算机教育,2018(11):97-99.
[3]张噗.“案例驱动+项目导向”的Java程序设计课程教学模式研究[J].计算机教育,2017(2):58-61.
[4]邓娜,王春枝,叶志伟,等.工程认证环境下基于Boppps模型的数据挖掘课程教学设计[J].计算机教育,2017(12):113-115.
[5]徐周波,古天龙,常亮.突显能力培养的离散数学逆向案例教学改革探索[J].计算机教育,2017(12):69-72.
[6]吴健生,许桂秋,等.数据挖掘与机器学习[C].北京:人民邮电出版社.
[7]李婷,张继周.大数据环境下本科生数据挖掘课程建设研究[J].教育现代化,2017,4(40):230-232.
[8]裴琴娟.基于数据挖掘法的高职教学质量评价体系的研究[J].教育现代化,2017,4(37):282-283.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网! 文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jiaoyulunwen/31262.html