SCI论文(www.lunwensci.com)
摘要:当今档案电子化过程中遇到的OCR识别倾斜和横向布局字体困难、印章遮挡导致OCR识别错误、OCR技术难以进行表格格式解析和表格内容识别等难题。为了解决这些问题,使用MobileNetV2网络实现了横向布局的档案扫描件角度转正,并应用U-Net网络和目标检测技术实现了印章去除技术,同时运用U2-Net网络实现了表格格式解析技术。此外,还引入了图片倾斜矫正技术和OCR文字识别技术,构建了全面的档案电子化系统。经实验验证,该系统能够高效地将纸质文档扫描成PDF,并对PDF中的文字进行解析、横向布局的页面矫正及对表格格式和内容进行解析。该系统结合高性能服务器和全天候队列数据处理,大大提高了海量档案电子化的效率,为企事业单位的档案管理带来了很大的便捷和效率优势。
关键词:图像分割;图像分类;档案电子化;OCR
Design of Electronic File System Based on End-to-end Model
Xiao Xueli,Leng Yingxiong,Xie Jiefang,Deng Yin,Zhou Yanji
(Dongguan Power Supply Bureau of Guangdong Power Grid Co.,Ltd.,Dongguan,Guangdong 523109,China)
Abstract:In the current process of digitizing archives,there are difficulties in OCR recognition such as skewed and horizontally arranged fonts,seal occlusion leading to OCR recognition errors,and difficulties in table format parsing and table content recognition using OCR technology.In order to solve these problems,MobileNetV2 network is used to realize the Angle correction of transverse layout file scanning,and U-Net network and target detection technology are used to achieve seal removal technology,and U2-Net network is used to achieve table format analysis technology.In addition,the technology of image tilt correction and OCR character recognition are introduced,and a comprehensive electronic file system is built.The experimental results show that the system can scan paper documents into PDF efficiently,parse the text in PDF,correct the horizontal layout of the page,and parse the form format and content.The system combines high-performance server and all-weather queue data processing,greatly improves the efficiency of electronic mass archives,and brings great convenience and efficiency advantages for the archives management of enterprises andinstitutions.
Key words:image segmentation;image classification;electronic records;OCR
0引言
档案电子化是数字化时代下的一个重要环节,各个行业都在不断推进档案电子化[1]项目。档案电子化为企事业单位管理带来了很大的便捷性和效率优势,但同时档案电子化也存在着困难和障碍:档案量过于庞大、保密要求高、文件存放位置太分散、文件标准化问题、图像扫描的精度问题、数据库完整性问题[2-4]。当前纸质档案电子化的方向主要包括以下3个方面:(1)数字化扫描和OCR技术[5]:通过高速扫描仪对纸质档案进行扫描,利用OCR技术[5-6]将扫描后的图像转换为可编辑文本,以提高档案的检索、维护和管理效率;(2)大数据云存储和共享:数字化后的档案文件可以通过网络存储在云端,并结合大数据技术进行管理和分析,同时,共享化的档案电子化方式可以使信息共享更为便利、高效和实时[2,7];(3)人工智能和智能化管理:人工智能与档案管理的结合,在档案归档、检索和管理方面都具有极大的优势,比如可以通过人工智能算法的应用,对档案信息进行智能分类和自动归档,提高管理效率和减轻工作负担。
为了解决现有纸质档案电子化问题,仅大数据云存储平台和智能化管理平台是不够的。通过构建大数据云存储平台和智能化管理平台只能解决未来新出现的档案数据的管理问题,而不能完全解决在过去产生的纸质档案电子化问题。因此,本文专注于纸质档案扫描成可编辑文件的需求,以及如何解决图像角度转正、印章去除、表格解析和文字识别等复杂问题。基于这些问题,本文设计了一个端到端的档案电子化系统,该系统结合了扫描工具、深度学习模型和硬件架构,并深入分析该系统的技术原理和处理流程。
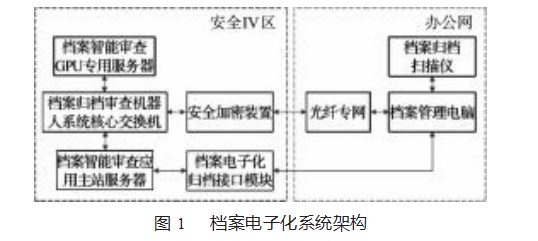
1档案电子化系统架构
本文的档案电子化系统采用多层架构设计,分别设有应用层、算法层、硬件层[8-9]。同时为满足数据的保密性要求,算法服务器和存储服务器需要存放在安全区内,数据的交互通过内部光纤专网进行传输。在办公区采用专用设备和专用电脑进行档案的电子化处理,进而实现数据的闭环式管理。
2图片矫正技术
2.1 MobileNetV2模型
MobileNetV2网络由Google团队在2018年提出,其是一种轻量级的卷积神经网络模型,它的设计旨在保持高精度的同时,减少模型的大小和计算量[10-11]。Mobile⁃NetV2采用一系列的大胆创新的设计,例如倒残差结构、线性瓶颈和多尺度特征融合等,使得它在移动设备和嵌入式设备上具有较好的性能表现,在实际的生产应用当中仅需极少的显卡性能即可满足需求[12]。
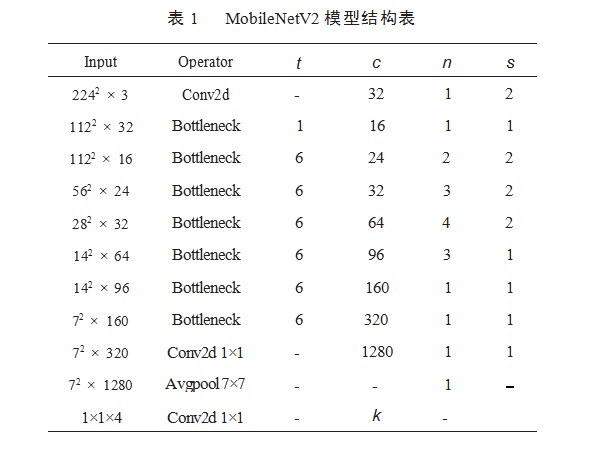
MobileNetV2的网络结构可以分为两个部分:特征提取部分和分类部分。特征提取部分由一系列的深度可分离卷积层组成,而分类部分则是一个全局平均池化层和一个SoftMax层。如表1所示,t为扩展因子,c为输出特征矩阵深度,n为bottleneck的重复次数,s为步距。
MobileNetV2网络采用的损失函数为交叉熵损失。交叉熵损失函数是一种用于衡量分类模型预测结果与真实结果之间差异的方法。它的计算方式是将真实结果转化为一个概率分布,然后计算预测结果与真实结果之间的交叉熵,即预测结果的概率分布与真实结果的概率分布之间的距离。交叉熵损失函数越小,表示模型的预测结果越接近真实结果。
2.2角度矫正和转正处理
在档案扫描成PDF时,由于扫描角度不正确的情况是指在电子文件转换过程中,扫描设备或人为原因,导致原始纸质文档在扫描时被倾斜或转了一个角度,造成PDF文档呈现的方向不正确,需要对其进行角度校正[13]。如果扫描的倾斜角度超过了一定范围,可能会对PDF文档的展示产生严重的影响。而PDF文档角度校正的方法一般有两种,一种是通过计算机程序实现自动校正,可以在扫描或导入PDF文档时使用或进行后期处理;另一种是手动校正,适用于需要高精度校正和复杂调整的场景。
同样的在实际的档案扫描场景中,经常遇到横向布局或者其他非标准布局的文档,这可能导致OCR文字识别错误,同时也会出现与原始表格格式相差甚远的情况。针对这种问题,提出了一种基于MobileNetV2神经网络的图片矫正模型。首先,通过旋转90°、180°、270°和360°的图片,构建了旋转方位不同类别的数据集,并对不同的旋转角度进行了类别编码。然后,将构建好的数据集送入神经网络中进行训练并预测图片的旋转角度,从而实现对图片的校正。
3印章去除技术
3.1 U-Net模型
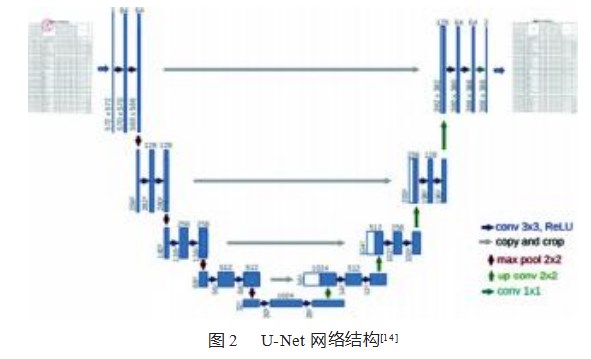
U-Net模型是一种用于图像分割的深度学习模型,由Ronneberger等[14]于2015年提出。它的结构类似于自编码器,由一个编码器和一个解码器组成,但是在编码器和解码器之间添加了跨层连接,使得解码器可以利用编码器中的低级特征来恢复高级特征。这种跨层连接的结构被称为U形结构,因此该模型被称为U-Net。如图2所示。U-Net模型的编码器部分采用了卷积神经网络,可以将输入图像逐渐缩小,提取出图像的低级特征。解码器部分则采用了反卷积神经网络,将低级特征逐渐恢复为原始图像,并且在每一层都添加了跨层连接,使得解码器可以利用编码器中的低级特征来恢复高级特征。U-Net的模型结构可以简单分为两个部分:下采样(编码器)和上采样(解码器),其中下采样部分用来提取图像的特征信息,上采样部分则用来恢复特征图的分辨率以得出图像的分割结果。下采样部分由逐层下采样的卷积层和池化层组成,这些层将输入图像逐步缩小,在过程中使用卷积滤镜提取特征信息。同时,每个下采样级别的特征图也会在下一个级别中作为输入,从而使网络获得更全面、更具有区分度的特征。因为它将原始图像编码成特征图,所以下采样部分也常被称为编码器。
与下采样部分相对应的是上采样(也称作解码器),解码器用来恢复分割图像的分辨率。解码器由卷积反卷积层和跳跃连接层组成。卷积反卷积层通过使用卷积滤镜进行上采样和卷积操作来恢复图像的分辨率,同时还对特征图进行修饰和调整以得到更准确的分割结果。而跳跃连接层则将特征图连接回解码器中,使网络能够利用不同层级中较细的详细特征进行分割,并解决了传统上采样方法中出现的模糊和空洞等问题。
U-Net的损失函数同样采用交叉熵损失函数,其公式与MobileNetV2模型的损失函数一致。但其与传统分类损失有差异的地方在于,U-Net要分割出多个类别的像素,因此其损失函数需要对每个像素的分类任务分别计算损失。须将每个像素看作一个独立的二分类任务,并将所有的分类任务损失相加求和,以得出总体的损失函数。
3.2文件印章剔除处理
目前,OCR技术只能对于未被印章遮盖的文字进行准确识别,而被印章盖住的文字往往难以精准识别,从而出现错误[15]。为了解决这个问题,需要寻找有效的技术手段,对印章进行剔除来保证准确的电子化过程。在本文中首先采用目标检测网络[16-18]定位印章的位置,并综合传统阈值法和分割网络U-Net进行印章的剔除。首先,通过PS技术处理原有数据集,将含有印章的数据进行去除,并构建了完善的印章数据集。然后,使用这个数据集去训练一个高性能的印章分割模型。最后,进行传统印章剔除的测试等,以验证模型的准确性和可靠性。通过这样的一系列流程,可以有效地解决档案电子化过程中印章干扰OCR识别问题。
4表格解析技术
4.1 U2-Net模型
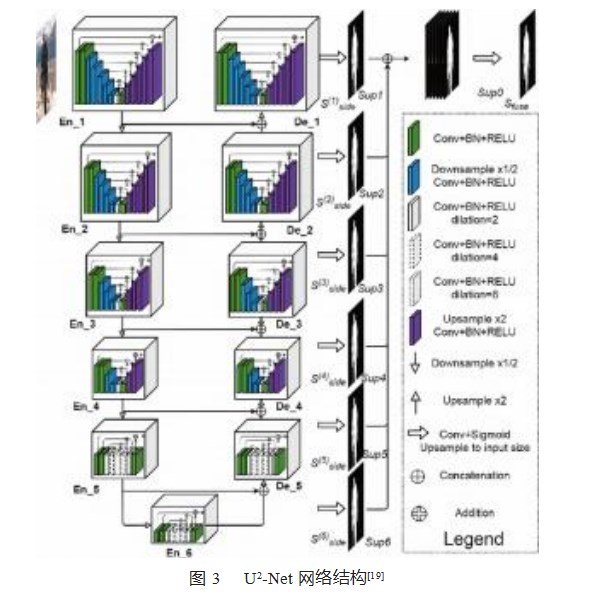
U2-Net模型是一种基于深度学习的图像分割模型,由国内学者于2020年提出[19]。该模型采用了U形结构,即编码器和解码器之间存在对称性,可以有效地提取图像特征和保留细节信息。该模型还采用了多尺度特征融合和反卷积等技术,进一步提升了分割效果。它是一种高效、准确的图像分割模型,具有广泛的应用前景。
U2-Net是基于U-Net改进的神经网络结构,主要用于图像分割,旨在提供更优异的分割结果。简单来说,U2-Net将图像分割分成3个阶段进行处理,并将子网络的输出作为下一个子网络输入的方式,以有效提取出更准确、更全面的图像特征。小U-Net主要用于提取图像区域之间的全局依赖关系和背景信息,由一些卷积层和池化操作组成。中U-Net主要用于提取图像区域之间的空间依赖关系,以及语义上更高级别的特征信息。大U-Net主要用于进行像素级别的检测并恢复细节信息。这种3段式的结构有助于增加网络的有效感受野和特征的多样性,从而使模型适用于不同的图像分割任务。
U2-Net模型的损失函数不同于U-Net,其损失函数由两部分组成,分别是二分类损失和边缘损失。其中,二分类损失采用了Focal Loss函数,可有效对抗类别不平衡问题;边缘损失则计算预测边缘和实际边缘之间的MSE误差,以促进分割结果的边缘化。U2-Net的损失函数综合了分类和边缘化的目标,相比于传统的交叉熵损失函数,可以更好地提升模型的鲁棒性和分割质量。具体的模型公式如下所示:
4.2表格解析处理
以往的档案电子化技术中,OCR文字识别一直是常用的手段,但其无法准确地识别和解析表格结构,而且还受制于表格边框的影响,导致误识别等问题[20]。为此,本文提出了一种基于U2-Net模型的表格解析器,以解决该难点问题[21]。具体而言,通过传统的阈值方法得到表格线制作数据集。接着,采用U2-Net神经网络进行训练,并用该模型预测表格,得到表格线图。接下来,在表格线图上找出所有单元格,并根据单元格坐标映射到Excel中。最后,利用OCR技术对每个小单元格进行文字识别,以还原整个表格的信息。
5档案电子化处理流程
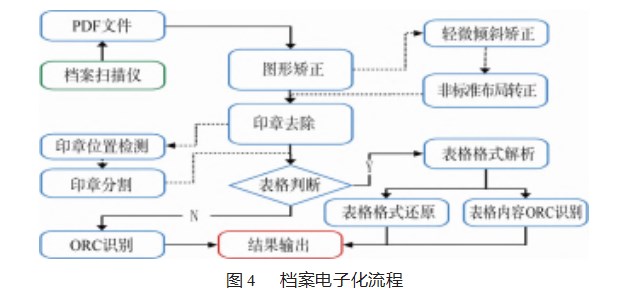
本文基于前文提到的技术研究,开发了一套端到端的档案电子化系统,旨在解决文档、表格、印章等问题。如图4所示,纸质档案的电子化流程:首先将纸质文档进行高效扫描,并对扫描得到的图像进行四角点定位与矫正,同时对表格方向进行分类并进行图片矫正操作。接着,该系统采用先进的印章定位与去除技术,对印章内容进行分割处理,最终使用U2-Net网络解析表格结构并进行内容的识别。如果图像中不含表格,则该系统会直接进行OCR文字识别,以实现高效文档电子化。通过该档案电子化系统,可以实现高效、准确、自动化的纸质档案电子化,实现对档案信息的可视化、可管理、可利用。同时,该系统的操作简单明了,不需要耗费大量人力和物力成本,可为各种行业提供解决方案,促进行业的数字化发展。
6结束语
本文提出了一种基于现代图像处理技术、神经网络的端到端纸质资料完全自动电子化系统。文章首先概述了现有档案电子化方案的现状,并列举了其中的痛点和难点。其次,本文详细分析了本系统的整体架构,并介绍了基于MobileNetV2的图片角度矫正技术、基于U-Net的印章去除技术、以及基于U2-Net的表格解析技术。最后,完整地介绍了整个档案电子化的处理流程。基于现代图像处理技术和神经网络的端到端档案电子化系统可以实现全自动、全时段的档案电子化处理。
通过该系统,可以实现对纸质档案的高效扫描以及对扫描文件进行数字化处理,从而达到电子化的目的。
具体来说,该系统可以对图像进行角度转正处理,去除印章、解析表格,实现文字识别并生成可编辑文档。这些功能的整合,使得纸质档案电子化的过程更为简便、高效和可靠。总之,端到端档案电子化系统提供一种有效的方案,可以有效地解决纸质档案电子化的问题,使得电子化过程更具有可操作性和持续性,为数字化时代的管理和存储提供了理想的解决方案。
参考文献:
[1]刘钧.企业档案数字化建设实践与思考[J].陕西档案,2022(6):44-5.
[2]杨爽.大数据背景下社保档案管理电子化探讨[J].秦智,2022(10):58-60.
[3]陈虹.医院财政票据会计档案电子化管理实践[J].商业观察,2022(27):81-4.
[4]罗亚利.英国国家档案馆数字档案保存风险评估模型研究及启示[J].浙江档案,2022(6):43-6.
[5]王学梅.OCR文字识别系统的应用[J].现代信息科技,2019,3(18):66-8.
[6]陆俊杰,魏亚东,李晓峰,等.基于OCR技术的航天器材料及器件试验数据识别系统[J].计算机测量与控制,2023,31(1):282-293.
[7]孙安."NoSQL"数据管理技术在档案大数据中的应用探析[J].管理工程师,2022,27(3):34-40.
[8]孟庆德,张春霞.基于虚拟化平台的档案实时更新系统设计[J].电子设计工程,2021,29(24):89-92,7.
[9]左晋佺,张晓娟.基于信息安全的双区块链电子档案管理系统设计与应用[J].档案学研究,2021(2):60-67.
[10]SANDLER M,HOWARD A G,ZHU M,et al.MobileNetV2:Invert⁃ed Residuals and Linear Bottlenecks[C]//2018 IEEE/CVF Con⁃ference on Computer Vision and Pattern Recognition,New York:IEEE,2018:4510-20.
[11]陈智超,焦海宁,杨杰,等.基于改进MobileNet v2的垃圾图像分类算法[J].浙江大学学报(工学版),2021,55(8):1490-9.
[12]孙小坚,林瑞全,方子卿,等.基于FPGA加速的低功耗的Mo⁃bileNetV2网络识别系统[J].计算机测量与控制,2023(5):221-227,234.
[13]王祥.基于不规则区域预测和控制点矫正的场景文字检测与识别[D].深圳:深圳大学,2020.
[14]RONNEBERGER O,FISCHER P,BROX T.U-Net:Convolution⁃al Networks for Biomedical Image Segmentation[J].ArXiv,2015,abs/1505.04597.
[15]王俊,苗军,卿来云,等.基于Pix2Pix网络的印章去除[J].北京信息科技大学学报(自然科学版),2021,36(4):39-43.
[16]杨锋,丁之桐,邢蒙蒙,等.深度学习的目标检测算法改进综述[J].计算机工程与应用,2023(11):1-15.
[17]乔炎,甄彤,李智慧.改进YOLOv5的安全帽佩戴检测算法[J].计算机工程与应用,2023(11):203-211.
[18]张昊,郑广海,张鑫,等.改进YOLOv5框架的血细胞检测算法[J].计算机系统应用,2023(5):123-131.
[19]QIN X,ZHANG Z,HUANG C,et al.U2-Net:Going Deeper with Nested U-Structure for Salient Object Detection[J].Pattern Recognit,2020,106:107404.
[20]高良才,李一博,都林,等.表格识别技术研究进展[J].中国图象图形学报,2022,27(6):1898-917.
[21]张云锦.文档图像表格提取算法研究[D].南昌:南昌航空大学,2020.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网! 文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/ligonglunwen/77261.html