



摘 要 :学生在线学习行为与成绩之间存在密切关联,为了挖掘学生学习行为特征间的隐含关系,研究采用改进的关联规则挖 掘算法对其进行相关性分析。实验结果表明,研究设计的算法在精确率及召回率指标上表现较好,相比传统的关联规则挖掘算法运 行速度更快, 用时降低幅度达 26.49%。该方法从多维度实现了学习行为的分析与关联, 为教学决策和研究提供了科学的支持和指导。
0 引言
计算机技术与互联网平台的发展加快了教育领域数 字化、信息化的变革与转型,在线教育的发展规模逐渐 扩大 [1]。网上教学模式不受时间与地点的限制, 提升了 学习的灵活性和便捷性。然而,在线学习对学生的学习 动力和自律性要求较高,缺乏教师监督的课堂导致线上 教学模式教学效果不佳。在线教育平台保留了大量的学 生学习行为数据,分析学生学习行为可以更好地理解学 生的学习需求, 识别学生的学习模式和规律 [2]。但现有 行为分析方法,并不能与复杂的学习行为分析完全适 应,容易忽视学习行为之间的潜在关联,对学习行为的 全面性把控较差 [3]。因此, 研究优化网上学习行为分析 思路,基于改进的 Apriori 算法对网上学习行为进行关 联分析,挖掘学习行为之间的潜在关联特征。该研究有望深入研究学习行为与学习成果之间的关系,为教育研 究和政策制定提供科学依据。
1 学生线上学习行为关联特征挖掘模型设计
1.1 关联规则及关联特征挖掘模型设计
学生网上学习行为包括课程登录次数,视频访问次 数、时长、完成率,论坛发帖量、回帖量以及在线测试 完成率等。数据挖掘是从海量数据中发现和挖掘有用 的、隐含的、非显而易见的模式、关系或知识的过程, 是通过分析海量数据寻找其中隐藏的有价值的信息来帮 助决策和预测的技术 [4]。关联规则是数据挖掘中的一种 常见模式,通过一定的规则找到数据之间的关联定义为 关联规则。数据挖掘利用关联规则可以发现隐藏在数据 背后的关系和模式,对学生学习行为的分析可帮助教育 管理者做出更好的决策 [5]。
关联规则包含支持度与置信度两个重要度量指标, 事务数据库 D 定义为 {T1.T2. … ,Tn},{T1.T2. … ,Tn} 中单 个项集为 Item={I1.I2. … ,In},事务T ⊆ Item。若存在项集 X, X ⊆ I,项集的支持度计算如式(1)所示 :

式(1) 中, count (X ⊆ T )表示支持数, Support(X) 表示某个项集在数据集中同时出现的概率,即支持度。 当项集满足 Support(X) 大于最小支持度时,为频繁项集 FI。当 FI 的超集不再大于最小支持度时,该频繁项集 为最大频繁项集。
Apriori 算法的关联规则定义如式(2)所示 :
关联规则的置信度指一个项集出现时,另一个项集也同时出现的概率。计算过程如式(3)所示 :
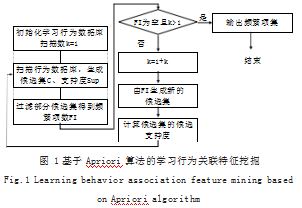
研究采用 Apriori 算法设计学生行为关联特征挖掘 模型, Apriori 算法通过多次扫描数据集,逐步生成频 繁项集,利用频繁项集生成关联规则。Apriori 算法简 单易懂、易于实现,能够处理大规模数据集。Apriori 算法的核心思路如式(4)所示 :
Apriori 算法对学习行为关联特征的挖掘需首先扫 描整个行为数据信息库,构建学生学习行为集 C1.并 计算支持度。在学习行为集 C 中计算得到满足最小支持 度要求的频繁项集 FI1.基于频繁项集 FI1 两两组合生 成学生行为集 C2.计算支持度得到频繁项集 FI2.并不 断重复该过程,经过数次迭代直到没有新的频繁项集产 生。然后根据频繁项集生成关联规则,根据最小置信度 要求筛选出满足要求的关联规则。
Apriori 算法较好地挖掘了学生学习行为的关联特 征,计算流程如图 1 所示。但传统的 Apriori 算法仍存在一些缺点,算法扫描次数较多,计算复杂度较高,存 在大量项集和事务的情况下,会产生大量的候选项集, 算法效率降低。
1.2 基于加权规则改进 Apriori 的学习行为关联特征挖掘模型设计研究从两个方面对传统的 Apriori 算法进行了改 进, 一方面通过为不同项目分配权重修剪 Apriori 搜索 空间 ;另一方面通过快速通用计算引擎 Apache Spark 实现了 Apriori 算法的并行计算。
权重向量为 W={w1.w2. … ,wn}, 第 i 个事务中第f 个 项目记为 Ti [if],每个项目均对应一个权重 w,表示为 Ti [if [w]]。项目权重取值为 [0.1] 区间内的实数,根据教 育经验及行业知识对不同项目的权重进行赋值。当事务 权重值在设定事务数据库中时,项集 Y 对事务 Ti 的权重 计算过程如式(5)所示 :

式(6) 中, NY 表示项集 Y 在事务数据库中出现的 次数 ;n 表示数据库中的记录的总数量。该过程主要是 汇总事务数据库中包含该项目的事务项集的所有权重。
式(7)表示X ∪Y 与X 的加权支持度之比。
Apache Spark 是一个开源的分布式数据处理和分 析框架,具有高效的大规模数据处理能力和丰富的数据 处理功能,广泛应用于大数据分析、机器学习、实时 数据处理等领域。Spark 在内存中即可完成数据的快速 处理, Spark 的核心是弹性分布式数据集(Resilient Distributed Dataset, RDD),RDD 是一个分布式的、可并 行处理的数据集合。Spark 包含较多的应用程序编程接口, 包括 Spark Core、Spark SQL、Spark Streaming、MLlib 和 GraphX 等模块,可以适用于不同的数据处理和分 析需求。Spark Core 层是 Spark 的核心模块, 提供了 RDD 的基本功能和数据操作能力。研究在 Spark 中实 现 Apriori 算法是使用 Scala 语言编程实现的,首先使 用flatMap() 函数将事务集以 RDD
2 学生线上学习行为关联特征挖掘模型应用效果测试分析
2.1 学习行为关联特征挖掘模型性能测试
实验设置在五节点集群环境下,加权算法的权重在 [0.1] 区间内随机取值,选择蘑菇数据集用作性能测试。 选择精确率、召回率、运行时间作为评价指标,对比传 统 Apriori 算法、基于布尔矩阵约简的 Apriori 改进算 法(Reduction Compression Matrix Apriori, RCM_ Apriori) 以及最大期望算法。实验结果显示, 研究设 计的并行加权算法在精确率与召回率指标上取值表现较 好,精确率取值 0.9 时,召回率取值为 0.886.精确率 与召回率这对矛盾指标实现了较好的平衡,优于其他数 据挖掘算法。并行加权 Apriori 算法的时间增长缓慢, 算法性能稳定,算法最高用时降低幅度达到了 26.49%, Spark 并行框架改善计算效率明显。
2.2 学习行为关联特征挖掘模型应用效果分析
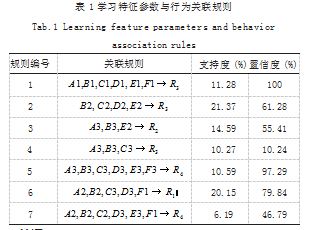
采用某在线学习平台近半年 2647 组学习行为数据 进行网络安全风险关联特征挖掘分析,经数据抽取、清 洗、规范处理,在多次统计分析后,设置最小支持度为 10%,最小置信度设置为 50%。根据数据挖掘结果学习 行为分为机械式 R1、灵活式 R2、深度式 R3 以及被动 式 R4.课程登录次数 A、视频访问次数 B、访问时长 C、论坛发帖量 D、回帖量 E 以及在线测试完成率 F 分别分为高、中、低三个等级,用数字 1、2、3 表示,部 分学习特征参数和学习行为的关联规则挖掘结果如表 1 所示。由表 1 可见,研究设计的方法在网上学习行为关 联特征挖掘上应用效果较好,有效识别学生的学习模式 和规律,有效分析学生学习的偏好和束缚条件。
3 结语
为了加强在线学习行为的监管能力,提高网上学习 效果,加强在线学习适应度,帮助教育机构优化教学资 源和教学策略。研究基于改进的 Apriori 算法建立了网 上学习行为关联特征挖掘模型。实验结果表明,研究设 计的并行加权 Apriori 算法精确率取值 0.9 时,召回率 取值为 0.886.精确率与召回率平衡较好 ;算法在运行 耗时上优势明显,耗时最高降幅达到了 26.49%。该方 法在网上学习行为分析中应用效果较好,有效挖掘了学 习行为特征与学习行为之间的关联规则。研究设计的学 生网上学习行为关联特征挖掘模型为个性化学习、资源 分配、教学决策和研究提供了有效支持和指导,有助于 提高教学效果和学习体验。但研究考虑的学习行为特征 参数较少,今后还需进行更全面的因素分析。
参考文献
[1] 刘静,由志勋.基于深度学习与数据挖掘的在线学习预测评 估模型设计[J].电子设计工程,2023,31(15):131-134.
[2] 朱冰洁,史同娜,施镇江,等.“金字塔”式网络学习平台构建 与学习行为分析[J].实验技术与管理,2021,38(8):208-212+216. [3] 许瑞斌.数据挖掘技术在高校教学质量评价中的应用研究 [J].教育研究,2021,4(5):28-30.
[4] 陈晓玲,李剑锋,付强.基于数据挖掘的文献平台用户行为分 析[J].吉林大学学报(信息科学版),2021,39(3):357-361.
[5] 王霞,曹丽娜,杨凤丽.基于改进Apriori算法的网络入侵数据 挖掘仿真[J].计算机仿真,2022,39(10):309-312.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!

可解释性是一个非常重要的标准。机器学习模型... 详细>>

如何设计有效的环境治理政策, 是学术界和政策... 详细>>
