



摘 要 :近年来, 机器学习越来越多地应用于各种生产和生活场景中。然而, 在现实中, 新的数据不断产生, 学习到新知 识的同时会忘记旧的知识,导致灾难性遗忘,而增量学习被用来解决该问题。本文介绍了增量学习的基本概念,以及三种主流 方法的特点及代表性方法,并对当前增量学习遇到的问题进行总结,最后对未来的研究方向做出展望。
0 引言
近年来,机器学习在生产和生活等领域得到广泛应用,在自然语言处理、图像识别、推荐系统等方面有突出的表现。传统的机器学习模型从独立且同分布的样本 中学习,如预先给出一组训练数据,通过使用一些学习 算法来训练模型,而这种算法需要在学习任务之前提供 整个训练数据集,大多都是以离线的形式进行训练的。 然而,在许多现实环境中,这种要求往往无法满足,原 因大致有三点 :(1)一些系统对其能存储的数据大小有 限制,不能采用联合训练策略,因为它们根本无法存储 所有获得的数据,只能为它们执行的任务存储有限的样 本,因此,学习必须是渐进式的。这种情况在机器人技 术中特别常见 [1],机器人在不同的时间或地点会面临不 同的任务,但仍能执行所有先前学到的任务。(2)还需要考虑数据安全或隐私限制。一些法律规定会限制对用 户信息的存储,信息无法被长久保存,模型必须在当前 阶段就充分学习样本信息。(3)还需要考虑训练成本。 随着时间的推移,大量数据不断产生,如果我们同时使 用过去和最新的数据训练模型,会导致训练的数据量不 断加大,训练时间不断增长,与模型快速刷新的目标相冲突。
随着技术的进步, 增量学习(Incremental Learning) 得到了广泛的关注,它在处理不断涌现的数据方面具有 独特的优势。增量学习在更新模型时只需要处理新的数 据,计算的效率更高,且无需存储全部历史数据,节约 资源。对于现实世界数据分析应用程序中的大规模机器 学习任务来说更加高效和可扩展。本文对增量学习的定 义进行了梳理,总结了近年来增量学习的三种主流方法,并结合当前遇到的问题,提出了一些未来可能的研 究方向。
1 增量学习的概念
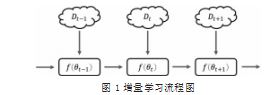
增量学习是一种机器学习范式 [2],研究的是如何从 流数据中学习的问题,在学习过程中不断输入新的数 据,预测当前学习内容的同时还要保留从以前学习到的 知识。Polikar 等人 [3] 对增量学习的概念进行规范, 随 后,增量学习被应用到了不同的领域。在某些研究中, 增量学习又被称为持续学习(Continual Learning)、 终身学 习(Lifelong Learning)、 在线学 习(Online Learning)。 一些学者也认为它们有细微的差别。He 等人 [4] 认为在线学习是增量学习的子领域,它还受到 运行时间和数据的限制。Hoi 等人 [5] 认为增量在线学习 指仅给出了一个用于一次更新模型的示例,而增量批量 学习指每次使用一批多个训练示例来更新模型。结合最 近的增量学习文献 [6.7], 我们给出增量学习的普遍定义 : 在更新周期 t,上一个周期的模型f (θt-1) 需要用新的传 入数据 Dt 更新。在f (θt-1) 对 Dt 进行训练后,更新后的 模型f (θt) 在下一个更新周期 t+1 之前,要对传入的数据 Dt+1 进行评估。如图 1 所示展示了增量学习设置的可视 化, 一个模型在连续的更新周期中,在接收数据的同时 时持续训练并测试。
根据不同周期传来数据的差异,增量学习分为三种 不同的场景,即任务增量学习、类增量学习和域增量 学习。任务增量学习(Task Incremental Learning), 是最简单的增量学习的场景。在这种场景下,无论是训 练阶段还是测试阶段,模型都被告知了当前的任务 ID。 类增量学习(Class Incremental Learning)的目标是 不断学习一个统一的分类器,直到可以识别所有遇到的 类,即增量地学习对象的新类,此场景是这三个场景中 最为复杂的,也是最接近现实中的学习场景。域增量学 习(Domain Incremental Learning) 有时也称为数 据增量学习,相较于任务增量学习,域增量学习在预测 阶段并不会告知任务的 ID。模型需要在不知道任务 ID 的情况下,将数据正确的分类。
目前增量学习遇到的挑战主要是灾难性遗忘 (Catastrophic Forgetting),即在新任务上训练过后,模型的参数会针对新任务进行优化,它在旧任务上的表现 效果就会降低。其次,增量学习还要求模型能快速适应 新知识,在新的数据到达后,能快速将其应用在模型 上。而如何在新旧知识之间进行平衡,是当前增量学习 主要的研究点。
2 现有的增量学习方法
为了减少灾难性遗忘, 一方面要提高模型的稳定 性,防止新的数据对已有的模型进行干扰,同时还要增 强模型的可塑性,能够从新的数据中整合提炼新的知识 保存进模型。近年来,国内外学者在增加模型稳定性和 解决可塑性困境中提出了大量方法,可以分为基于回 放、基于正则化以及基于架构的增量学习方法。
2.1 基于回放的增量学习
减轻灾难性遗忘的一种策略是将一部分旧任务的样 本存储在缓存中,在训练新任务时,将保存的旧样本与 新样本一起训练来防止遗忘旧知识。这类方法主要考虑 的问题有 :如何选取有代表性的样本、新旧样本的混合 方式、旧样本的保存形式、保存样本的内存大小等。根 据旧样本保存的形式,基于回放的增量学习分为保留原 始样本或重新生成样本。
2.1.1 保留原始样本
保留原始样本的方法通常在一个小的记忆缓冲区中保 存一些原始的旧样本。在选取代表性样本的时候,有多种 不同的方法。如蓄水池采样算法(Reservoir Sampling) 随机选择数据流中的样本,每个样本被选中的概率相 等 ;K-means 算法选择相似度大的样本,是常用的聚 类算法 ;而 Herding 算法使用迭代的方法选择最接近 原始平均向量的样本,保留了旧样本的特征。在旧样 本的使用上,大部分模型会将所有保存的旧样本全部 用于训练,而 MIR[8] 选择每个训练步骤后损失增加较大 的样本来训练样本记忆。对于旧样本的利用也是重点研 究的方向。Lopez-paz 等人 [9] 认为基于内存的增量学习 关键是只限制新任务更新而不干扰以前的任务,他们提 出了梯度情景记忆模型(Gradient Episodic Memory, GEM),在每个训练步骤中, GEM 确保每个先前任务 的记忆样本损失不会增加,而 A-GEM[10] 改进了 GEM, 确保所有过去任务的平均损失不会增加,同时 iCaRL[11] 和 EEIL[12] 结合知识蒸馏,将旧模型中的知识保留到新 模型中。
2.1.2 重新生成样本
在没有以前样本的情况下,重新生成样本是保留原始 样本的一种替代策略。除了要训练进行预测的主要模型, 重新生成样本的方法还需要训练一个单独的生成模型,这种方法可以在相同的内存中存储更多的样本数据。此外, 编码样本所在的特征空间是完全可微的,这使得可以使用 梯度方法来搜索大多数受干扰的样本,然而,这也增加了 持续训练生成式模型的复杂度。在 MIR 的基础上, Rahaf 等人也提出了自己的生成式模型方法 GEN-MIR,通过训练 一个自动编码器来存储和压缩传入的记忆,然后在自动编 码器的潜在空间中执行 MIR 搜索。DGR[13]、MeRGAN[14] 利用生成对抗网络(Generative Adversarial Nets, GANs) 来形成细粒度的样本。而 EEC[15]、GMR[16] 等则使用变 分自动编码器(Variational Autoencoder, VAE)来显 式地控制生成样本的标签。
2.2 基于正则化的增量学习
正则化技术对网络参数的更新施加约束,以减少灾 难性遗忘。该方法避免了存储原始数据,优先考虑隐私, 并减轻了内存要求。通过在损失函数中引入了一个额外 的正则化项,在新的数据上学习时巩固以前的知识。我 们可以进一步将这些方法分为权重正则化和数据正则化。
2.2.1 权重正则化
权重正则化侧重于防止与先前任务相关的权重漂移。 假定参数是独立的,在学习每个任务后,权重正则化方法 会评估神经网络模型所有参数对旧知识的重要性,在以后 的任务训练中,重要参数的变化会受到惩罚。最经典的 是弹性权重合并方法 (Elastic Weight Consolidation, EWC)[17], 它使用顺序贝叶斯推理, 将学习参数作为先 验知识来近似后验分布,根据 Fisher 信息矩阵找到学 习任务的重要参数,并在损失函数中添加二次项来减少 它们的变化。Zenke 等人 [18] 提出了路径积分方法,该 方法沿着整个学习轨迹累积每个参数的变化长度来近似 其重要性。MAS[19] 根据预测结果对参数变化的敏感度 来计算各参数的重要性。
2.2.2 数据正则化
数据正则化方法通过知识蒸馏将旧模型的知识转移 到新模型上,采取教师 - 学生模式,将先前学习的模型 作为教师,当前训练的模型作为学生来进行知识转移。 LwF[20] 是所有数据正则化方法的灵感来源,学习新样 本的同时使用旧任务的输出预测来计算蒸馏损失,然而 当任务之间的域转移很大时,模型效率会显著降低。对 此,基于编码器的终身学习 [21] 在 LwF 的基础上优化了 不完整的自动编码器,将任务特征约束在低维空间中。 2.3 基于动态架构的增量学习基于动态架构的增量学习方法通过动态增加网络的 容量来减少灾难性遗忘,该方法使得模型能够维持先前 的任务知识,同时扩展该模型以学习新任务。ACL[22] 方
法将模型分为任务共享组件和特定任务组件,特定任 务组件可以持续扩展。随机路径选择方法(Random Path Selection, RPS) [23] 预先分配多个并行网络来构 造一些候选路径,并为每个任务选择最佳路径。由于需 要引入较多的参数,基于动态架构的方法通常只用于简单的增量学习任务。

3 问题和挑战
目前的增量学习方法通常要求任务间的性质和难度差 异不能太大, 否则大部分增量学习方法的性能都会严重下 降,甚至低于简单的基线模型。另外,有不少研究表明, 目前还没有任何一种增量学习方法在任何条件下都能表现 良好,大部分增量学习方法对模型结构、数据性质、超参 设定都比较敏感,因此探索在所有任务设定中表现更稳健 的增量学习方法也是很有意义的。类增量学习还有类别偏 置问题 [24],分类后在新类上的权重会明显大于在旧类上 的权重。而使用蒸馏方法会出现遗忘后恶补的现象 [25], 在训练刚开始的时候旧类的特征空间会被遗忘,而经过 几十个 Epoch 之后,会重新回想起旧类。
4 未来研究方向
4.1 混合方法
目前对类增量问题表现最好的解决方案涉及各种技 术的组合,以避免灾难性的遗忘。大多数混合方法的一 个共同的关键点是在使用重放样本表示旧类别的情况下 对新类别进行微调。这种微调带来了更好的结果,但可 能需要大量的样本缓冲,同样,也需要大量的超参数, 这可能会阻碍其在现实世界中的应用。尽管目前的大部 分研究都呼吁单一使用基于正则化的技术,特别是知识 蒸馏,但呈现出最好的整体结果的方法通常将这种技术 与回放、自我标记和元学习相结合。
4.2 小样本类增量学习
在实际应用场景中,新类别刚刚出现时往往只有少 量的样本,可能需要模型从只有几个批次和几个未见过 的类别的数据流中学习。这种情况是因为它假定没有提 供大量的数据集,会使得传统神经网络的批量学习难以 应用,需要一种特殊的解决方案,因此,自然也就比普 通的增量学习范式更难。现有的实验结果显示,当遇到 少样本的增量学习时,模型更注重对新类的适应,而不 是避免对旧类的遗忘。
4.3 元学习
元学习是一种新兴的学习范式,是一种学习如何学习 的方法,在获取已有知识的基础上快速学习新的任务,可以 有效缓解大量调参和增量训练带来的计算成本问题。元学习 构建了一个潜在的框架来推进学习,近年来许多基于元学习的方法被提出,其中大多数都支持增量学习。MER[26] 将经 验回放与基于优化的元学习相结合,以最大化迁移和最 小化基于未来梯度的干扰。iTAML[27] 提出学习一种任 务不可知模型,该模型可以自动预测任务,并通过元学 习快速适应被预测的任务。这些工作显示了元学习的潜 力。我们预计这些技术将在未来几年得到进一步发展, 并将在更复杂的数据集上取得成果。
5 结语
本文针对增量学习的概念以及最新研究进展进行了 系统性的综述。将现有的增量学习方法分为三类,对每 一类型做了系统性的介绍,同时,对当前增量学习中遇 到的问题进行总结,并对未来增量学习的主要研究方向 进行展望。当前,增量学习在机器学习领域有较为广阔 的前景和潜力。未来,我们期待看到更多的研究将理论 和实践相结合,提出更为稳健和通用的增量学习算法。 这将有助于解决实际场景中不断涌现的新任务,使得机 器学习系统能够持续适应变化的环境,为其现实世界中 的应用带来更多可能性。
参考文献
[1] LESORT T,LOMONACO V,STOIAN A,et al.Continual Learning for Robotics:Definition,Framework,Learning Strategies,Opportunities and Challenges[J].Information fusion,2020(58):52-68.
[2] RING M B.Continual Learning in Reinforcement Environments[D].Texas,USA:University of Texas at Austin, 1994.
[3] POLIKAR R,UPDA L,UPDA S S,et al.Learn++:An Incremental Learning Algorithm for Supervised Neural Networks[J].IEEE Transactions on Systems,Man,and Cybernetics,Part C,2001,31(4):497-508.
[4] HE J,MAO R,SHAO Z,et al.Incremental Learning in Online Scenario[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR).Seattle,WA,USA: IEEE,2020:13923-13935.
[5] HOI S C H,SAHOO D,LU J,et al.Online Learning:A Comprehensive Survey[J].Neurocomputing,2021(459): 249-289.
[6] MI F,LIN X,FALTINGS B.Ader:Adaptively Distilled Exemplar Replay Towards Continual Learning for Session-based Recommendation[C]//Proceedings of the 14th ACM Conference on Recommender Systems.New York,USA:ACM,2020:408-413.
[7] BIESIALSKA M,BIESIALSKA K,COSTA-JUSSA M R.Continual Lifelong Learning in Natural Language Processing:A Survey[J].2020.
[8] ALJUNDI R,CACCIA L,BELILOVSKY E,et al.Online Continual Learning with Maximally Interfered Retrieval[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems,2019:11872-11883.
[9] LOPEZ-PAZ D,RANZATO M A.Gradient Episodic Memory for Continual Learning[J].Advances in neural information processing systems,2017,30.
[10] CHAUDHRY A,RANZATO M A,ROHRBACH M,et al.Efficient Lifelong Learning with A-GEM[J].2018.
[11] REBUFFI S-A,KOLESNIKOV A,SPERL G,et al.iCaRL: Incremental Classifier and Representation Learning[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu,HI,USA:IEEE,2017:5533- 5542.
[12] Francisco M Castro,Manuel J Marin-Jimenez,Nicolas Guil,et al.End-to-end Incremental Learning[C]//European Conference on Computer Vision (ECCV),2018:241-257.
[13] SHIN H,LEE J K,KIM J H,et al.Continual Learning with Deep Generative Replay[C]//31st Conference on Neural Information Processing Systems.Long Beach,CA, USA,2017:2994-3003.
[14] Tyler L Hayes,Giri P Krishnan,Maxim Bazhenov,et al.Replay in Deep Learning:Current Approaches and Missing Biological Elements[J].Neural computation, 2021,33(11):2908-2950.
[15] AYUB A,WAGNER A R.EEC:Learning to Encode and Regenerate Images for Continual Learning[C]// International Conference on Learning Representations, 2021.
[16] Pfülb,Benedikt,Alexander Gepperth,Benedikt Bagus. Continual Learning with Fully Probabilistic Models[J]. 2021.
[17] KIRKPATRICK J,PASCANU R,RABINOWITZ N,et al. Overcoming Catastrophic Forgetting in Neural Networks[J]. Proceedings of the National Academy of Sciences,2017, 114(13):3521-3526.
[18] ZENKE F,POOLE B,GANGULI S.Continual Learning Through Synaptic Intelligence[C]//International Conference on Machine Learning,2018:5590-6375.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!

可解释性是一个非常重要的标准。机器学习模型... 详细>>

如何设计有效的环境治理政策, 是学术界和政策... 详细>>
