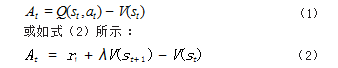SCI论文(www.lunwensci.com)
摘 要 :传统的学生素质素养评估方法往往基于专家经验或标准,难以全面、客观地评估学生的素质素养。基于人工智能 强化学习算法的学生素质素养预测机制是一种数据驱动的方法,它利用大量的学生数据进行模型构建和预测,经过不断地优化 算法和模型,提高模型的准确性和泛化能力,同时结合学生素质素养指标实现个性化的综合性分析,从而全面地评估与预测学 生的素质素养能力。此外,该预测机制能够根据学生的表现和反馈信息,不断调整和优化学生的能力模型,提高学生素质素养 评价的先进性,还能够通过建模实现对学生学习行为的精细化管理。最后,将基于强化学习的学生素质素养预测机制应用到实 际教学场景中,并对其效果进行评估和优化,推广其应用领域,同时将其转换为科研成果。
关键词 :人工智能,强化学习算法,素质素养
Research on Quality and Literacy Prediction Mechanism BasedonArtificialIntelligence Reinforcement LearningAlgorithm
JIN Hengqing
(Gansu Vocational College of Agriculture, Lanzhou Gansu 730000)
【Abstract】:Traditional methods for evaluating students' quality and literacy are often based on expert experience or standards, making it difficult to comprehensively and objectively evaluate students' quality and literacy. The mechanism for predicting students' quality and literacy based on artificial intelligence reinforcement learning algorithms is a data-driven approach, it utilizes a large amount of student data for model construction and prediction, continuously optimizing algorithms and models, improve the accuracy and generalization ability of the model, simultaneously combining student quality and literacy indicators to achieve personalized comprehensive analysis, to comprehensively evaluate and predict students' quality and literacy abilities. In addition, the prediction mechanism can be based on students' performance and feedback information, continuously adjusting and optimizing students' ability models, improve the progressiveness of students' quality assessment, it is also possible to achieve refined management of students' learning behavior through modeling. Finally, the prediction mechanism for students' quality and literacy based on reinforcement learning will be applied to practical teaching scenarios, and evaluate and optimize its effectiveness, promote its application areas, simultaneously convert it into scientific research achievements.
【Key words】:artificial intelligence;reinforcement learning algorithm;quality and literacy
1 科学依据和意义
1.1 应用前景
(1)为学生素质素养提供动态评估与监测。基于强 化学习的素质素养预测机制可以帮助学校和教育机构更 好地了解学生的学习状况和发展趋势,从而制定更有效 的教育策略和培养方案。(2)为学生学习支持和指导提供理论依据。基于强化学习的素质素养预测机制可以针 对每个学生的特点和需求进行个性化教育,为学生提供 更好的学习支持和指导,帮助学生更好地发挥自己的潜 力。(3)为教师培训与教育改革提供参考思路。基于 强化学习的素质素养预测机制可以帮助教师更好地了解 学生的学习需求和表现,提高教师的教育水平和教学质量,同时也为教育改革提供重要的参考。
1.2 学术思想
基于强化学习的学生素质素养预测机制的学术思想 是基于强化学习的算法和原理,将其应用于学生素质素 养的评估和预测,从而构建学生能力模型,提高学生的 素质素养。强化学习是一种基于试错的学习方法,它通 过智能体与环境的交互,使智能体逐渐学会如何采取最 优的动作以最大化累积奖励 [1]。在学生素质素养的评估 和预测中,可以将学生视为智能体,将学生与教育环境 视为环境,通过智能体与环境的交互,构建学生的能力 模型,并对学生的未来表现进行预测,从而提高学生的 素质素养。
1.3 特色与创新
基于强化学习的学生素质素养预测机制相较于传统 的学生素质素养评估方法,具有以下特色与创新之处 :
(1)基于数据驱动的方法。传统的学生素质素养评 估方法往往基于专家经验或标准,难以全面、客观地评 估学生的素质素养。而基于强化学习的学生素质素养预 测机制可以利用大量的学生数据,通过数据驱动的方法 建立学生的能力模型,更加客观和准确地评估和预测学 生的素质素养。(2)涵盖多个方面的评价。学生的素质 素养包括学习能力、认知能力、社交能力、情感能力等 多个方面,而这些方面往往相互影响、相互作用,难以 分开评估。基于强化学习的学生素质素养预测机制可以 将这些方面综合起来考虑,建立更加全面、细致的学生 能力模型。(3)应用人工智能的技术。强化学习算法具 有良好的适应性和泛化能力,能够自动学习最优策略, 不断优化学生的能力模型。这一特点使得基于强化学习 的学生素质素养预测机制更加灵活、高效,能够适应不 同的学生和环境。(4)实现指标的动态调节。基于强 化学习实验法的学生素质素养预测机制不仅能够评估和 预测学生的素质素养,还能够根据学生的表现和反馈信 息,不断调整和优化学生的能力模型,提高学生素质素 养评价的先进性。
综上所述,基于强化学习的学生素质素养预测机制 具有较强的科学性、实用性和创新性,是一种有前景的 研究方向。
2 研究内容和预期成果
2.1 研究内容
基于强化学习的学生素质素养预测机制的研究内容 主要包括以下几个方面 :
(1)数据收集与信息处理。采集大量的学生数据, 包括对学生教学活动的过程、评价、反馈等信息,并对数据进行预处理和清洗,保证数据的准确性和可用性。
(2)特征提取与学生建模。根据个性化的学生数 据,提取有意义的特征,并将学生建模成强化学习的智 能体,建立学生的能力模型 [2]。
(3)策略制定与决策优化。建立学生能力模型, 制 定相应的策略,实现对学生的指导和管理,并通过强化 学习算法不断优化策略,提高学生的素质素养。
(4)算法实现与性能评估。将研究内容实现成可操 作的算法,并通过对比实验和性能评估来验证算法的有 效性和优越性。算法将基于执行器、评价器的深度策略 梯度算法和深度确定性策略梯度算法。
1)基于执行器评价器的深度策略梯度算法。策略梯 度算法直接对智能体的策略进行优化,它需要收集一系 列完整的序列数据τ 来更新策略。在 DRL 中,对序列数 据进行收集往往很困难,并且以序列的方式对策略进行 更新会引入很大的方差。一种可行的方案是将传统强化 学习中的 AC 结构应用到 DRL 中。AC 结构主要包括执 行器和评价器两部分,其中执行器基于策略梯度算法更 新动作,评价器则基于值函数法对动作进行评价。AC 结 构的优点是将策略梯度中的序列更新变为单步更新,不 用等序列结束后再对策略进行评估和改进,这样可以减 少数据收集的难度,同时可以减小策略梯度算法的方差。
对于值函数部分, 也可以用优势函数来代替。优势 函数可以表示为如式(1)所示 :
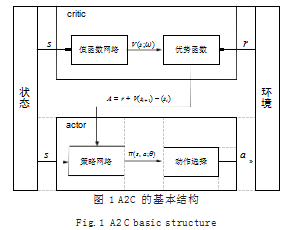
使用优势函数代替 Q 函数,可以提高“好”动作出 现的概率。使用优势函数可以进一步的减小算法的方差, 基于优势函数的 AC 结构被称为优势 AC(Advantage AC, A2C)算法。A2C 的基本结构如图 1 所示。
2)深度确定性策略梯度算法。策略梯度算法一般采
其中, τ 表示更新率,且值远小于 1.
同时, DDPG 算法还加入噪声来增加探索,进一步 提升算法的性能。DDPG 算法在一系列连续动作空间的 任务中都能表现稳定。相对于 DQN 来说, DDPG 在博 弈中能够取得更高的效率,训练时间更少。
(5)算法应用和技术推广。将基于强化学习的学生 素质素养预测机制应用到实际教学场景中,并对其效果 进行评估和优化,推广其应用领域。
综上所述,基于强化学习的学生素质素养预测机制 的研究内容涉及多个方面,需要结合实际教学场景,综 合运用多种技术手段,实现对学生素质素养的全面、准 确、有效的预测和提高。
2.2 研究目标
基于强化学习的学生素质素养预测机制的研究目标 主要包括以下几个方面 :
(1)实现对学生素质素养的准确预测。通过对学生 数据的收集、处理和分析,建立学生的能力模型,并基 于强化学习算法实现对学生素质素养的准确预测,提高 教学的精准度。
(2)实现对学生素质素养的有效提升。通过制定针对 不同学生的个性化学习策略,基于强化学习算法实现对学 生素质素养的有效提升,提高学生的综合素质和能力。
(3)实现对学生学习行为的精细管理。通过基于强 化学习算法的学生建模和策略制定,实现对学生学习行 为的精细化管理,为教学管理提供有效的决策支持。
(4)实现对人工智能技术推广与应用。将基于强化 学习的学生素质素养预测机制推广应用到不同教学场景 和不同学科领域,提高教育教学的效率和质量。
综上所述,基于强化学习的学生素质素养预测机制 的研究目标旨在提高学生素质素养的预测和提升效果, 为教育教学提供有效的决策支持和指导,促进学生全面、 健康、快乐地成长。
2.3 解决的问题
基于强化学习的学生素质素养预测机制旨在解决以 下几个方面的问题 :
(1)实现个性化分析。传统评价方法缺乏评价指标 的统一标准,在收集大量无用数据的同时缺乏准确率的 评价体系,而基于强化学习的学生素质素养预测机制能 够从学生的行为、表现和反馈等多维度数据中提取到有 用的信息,通过建立学生的能力模型,实现对学生素质 素养的准确预测。
(2)提升评价准确性。基于强化学习算法的特点, 针对实际应用场景进行优化,通过强化学习的学生素质 素养预测机制能够提高预测和提升效果。
(3)学习策略的优化。根据对学生教学活动中过 程、评价、反馈等信息的驱动,通过算法得出各个学生 的能力和特点的相关结论,从而制定个性化的学习策 略,实现对学生素质素养的有效提升。
(4)学生管理精细化。通过强化学习算法对学生的 行为进行精细化管理,及时发现和解决学生存在的问 题,提高学生学习效果和素质素养。
(5)算法的可解释性。依据强化学习算法的可解释 性和透明性,让教育从业者和学生能够理解和接受算法 的预测和提升策略,从而增强算法的可信度和可接受度。
综上所述,基于强化学习的学生素质素养预测机制 需要解决数据处理和分析、算法选择和优化、个性化学 习策略制定、行为精细化管理以及算法可解释性和透明 性等关键科学问题,才能实现对学生素质素养的有效预 测和提升。
3 拟采取的研究方法和技术路线
3.1 研究方法
基于强化学习的学生素质素养预测机制研究的方法主要包括以下几个方面 :
(1)数据采集和处理。首先需要收集和处理与学生 素质素养相关的数据,例如,学生的学习行为数据、活动 数据、考试成绩、家庭背景等,将数据进行预处理、清洗, 通过特征提取的转换后得到可以用于强化学习的数据。
(2)强化学习算法的选择。分析学生素质素养预测 需求和个性化的学生数据自身特点,选择适合的具体强 化学习算法,例如,Q-learning、Policy Gradient 等。
(3)建模与训练。根据收集到的数据, 利用强化学 习算法对学生进行建模和训练。通过参数的初始化完成模 型的搭建并以数据驱动模型的训练,最终学习到学生的能 力和特点,从而获得用于预测学生素质素养的模型 [3]。
(4)模型评估与优化。针对当前已有的学生素质素 养预测模型,确定模型与参数的合理性并对模型的性能 进行评估和优化,包括模型的准确性、稳定性和泛化能 力等方面。
(5)模型应用与成果转换。根据模型预测结论, 实 现个性化的学习策略推荐和学生行为管理系统等应用, 帮助学生提高学习效果和素质素养,也为教育管理部门 提供决策支持,最终依据模型应用效果转换为软著与专 利等科研成果。
3.2 技术路线
基于强化学习的学生素质素养预测机制的技术路线 有如下几个方面 :
(1)数据采集和预处理。包括从多个渠道获取学生 学习行为数据、学生活动信息、学生个人信息、教育背 景等相关数据,并进行数据预处理,包括数据清洗、数 据统计、特征提取等步骤,最终转换为能够用于模型训 练的数据集。
(2)建立强化学习模型。根据采集到的数据, 建立 基于强化学习的学生素质素养预测模型,包括环境建 模、状态表示、动作定义、奖励设计等步骤。选择适合 问题的强化学习算法进行建模, 如 Q-learning、DeepQ Network 等。
(3)模型训练与优化。利用采集到的数据对模型进 行训练,并对模型进行优化和调参,以提高模型的准确 性和泛化能力。同时,需要对模型的稳定性进行评估并 分析模型的可解释性。
(4)模型评估和应用。对训练好的模型进行评估, 包括准确度、召回率、F1 值等指标的评估。在评估过 程中,需要使用独立数据集进行测试,并采用交叉验证 等技术确保模型的泛化能力。最后将模型应用到实际场 景中,帮助学生提高学习效果和素质素养。
(5)模型迭代和更新。随着学生个体差异的变化以 及新的数据采集,模型需要进行迭代和更新。在模型更 新的过程中,需要采用增量学习等技术,使模型能够及 时更新,以适应新的数据和环境。
3.3 研究计划
基于强化学习的学生素质素养预测机制的研究计划 如表 1 所示。整个研究计划将采用敏捷开发的方式,每 个阶段的成果将经过实验验证和实际应用测试。
4.结语
综上所述,基于强化学习的学生素质素养预测机制 的研究需要建立一个高效的数据采集系统和完备的数据 库、强化的学习算法平台、高性能的计算机和 GPU 等 硬件设备、学科专家和教育专家的支持,同时还需充足 的资金和时间支持。
参考文献
[1] 万里鹏,兰旭光,张翰博,等.深度强化学习理论及其应用综述 [J].模式识别与人工智能,2019.32(1):67-81.
[2] 刘建伟,高峰,罗雄麟.基于值函数和策略梯度的深度强化学 习综述[J].计算机学报,2019.42(6):1406-1438.
[3] 孙长银,穆朝絮.多智能体深度强化学习的若干关键科学问 题[J].自动化学报,2020.46(7):1301-1312.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/68169.html