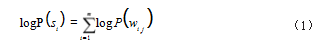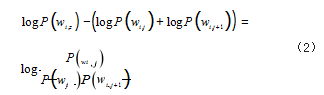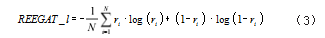SCI论文(www.lunwensci.com)
摘 要 :信息抽取技术是大数据时代精准获得信息的关键技术。在网络时代背景下,信息抽取的实时性、准确性和实名性 极为重要,因此,在信息抽取时,实现对多元信息的筛选分析非常关键。通过文献研究与实践分析可知,对比学习和图神经网 络技术的应用,有利于在信息抽取环节准确识别单词多义和单词缩写的信息,在实践中需分别构建模型,以便进一步实现信息 抽取功能。
关键词 :对比学习,图神经网络,关系抽取模型
Research on the Application ofInformation Extraction Technology Supported byComparative Learning and Graph Neural Network Technology
MAYiming
(Wuhan Donghu University, Wuhan Hubei 430212)
【Abstract】:Information extraction technology is a key technology for accurately obtaining information in the era of big data. In the context of the internet era, the real-time, accuracy, and real name of information extraction are extremely important. Therefore, achieving the screening and analysis of multivariate information is crucial in information extraction. Through literature research and practical analysis, it can be concluded that the application of contrastive learning and graph neural network technology is beneficial for accurately identifying polysemy and abbreviation information in the information extraction process. In practice, it is necessary to construct models separately in order to further achieve information extraction functionality.
【Key words】:comparative learning;graph neural network;relationship extraction model
在大数据技术的支持下,互联网平台上的信息交 互流通总量呈现出逐步加大的趋势。根据 IDC 发布的 《数据时代 2025》统计结果显示,全球数据的增长速度 呈现出逐步加快的趋势,增速迅猛。据报告数据统计, 截至 2025 年, 全世界每人每天的互联网互动次数可达 到 4909 次, 较之 2020 年上升 300%, 平均单次互动率 达到每 18 秒 1 次。为更好地满足用户对数据抽取数据 应用的需求,需要基于网络平台和对比学习图神经网络 技术实现对批量数据的精准分析,有效抽取,以便利用 信息,为用户提供更加科学、更加便捷的服务。
1 关系抽取方法的对比分析
关系抽取的过程需应用专业方法。现阶段关系抽取时常用的方法包括基于既定规则抽取、基于传统机器学 习抽取、基于深度学习抽取。抽取过程要经历学习和预 测两个阶段 [1]。其中,学习过程主要强调通过适当的训 练方法训练出与当前语料库关系相符合的抽取模型,预 测环节则主要是将已经训练好的关系抽取模型面向测试 文本完成预测过程。关于深度学习方法的应用,主要依 靠多样化的深度神经网络、卷积神经网络以及远程监督 技术做支持。不同类型的关系抽取方法在应用时各有优 劣,需要技术人员结合实践应用需求对不同类型的抽 取方式进行对比分析,以便进一步合理选择关系抽取方 法,进行应用如表 1 所示的三种典型关系抽取方法的优 劣要点信息统计表。
2 利用对比学习法构建命名实体识别模型
2.1 模型形式化
命名实体识别的主要目标在于从文本中直接抽取人 名、地名或机构名等专有名词的信息。从本质上来说, 模型形式化的过程是从文本语料库中抽取某个句子中的 所有单词和词组,并且正确进行实体标签的分配,例如 人名单词或词组, 一般会对应划分到人名实体类型中。
2.2 模型结构分析
在本文研究中,模型结构主要以 WCL-BBCD 模型 为主。其基本结构呈现出网络层级组织的特征。主要包 括三个基本组件 :(1)WCL 模型 ;(2)BBC 模型 ;(3) DB Pedia 知识图谱。其中, WCL 模型在应用时,主要 选择语义具有近似性的句子分别输入模型中得到不同句 子中的对应单词词嵌入向量。随后,应用损失函数衡量 其在向量表示空间内的相似程度。训练过程中,应用反 向传播模式,按照梯度下降算法对模型参数进行优化, 调整输出经过调整后的模型。而 BBC 模型的输入内容 为语料库中的文本 [2]。输入时,句子中的每个单词所属 的实体类型是其输入的主要内容。在模型中,包括了词 嵌入层、BiLSTM 层和 CRF 层三个基本结构。在具体 应用时,初步输入模块信息后,还需要通过科学方法对 模块信息和实体类型进行优化修改。
2.3 模型组件分析
模型组件结构的合理性对于模型作用的发挥有重要 影响。在本次研究中,模型组件主要是 WCL-BBCD 模型。
本文重点对 BERT 这一核心模型的组建架构进行分 析,此模型的性质为双向模型,模型结构中包括输入向 量、隐藏层向量两部分向量信息。不同类型的向量信息 通过模型结构的构件形成向量传递,部分向量还需要通 过求和得到有效的数据信息。在模型组件分析中,需首 先对模型架构进行充分明确,随后,再进一步对细节组 件的功能发挥效果进行研究。在这一模型中,句子的分 词需要依靠 Bert-tokenizer。
分析算法为 WordPiece 算法,此种算法的实施步骤具体有 :首先根据文本语料 库信息构建仅包含单个字符的词典 ;随后,将需要从词典中选择的两个词语合并成一个新的词语,这时的词语 被称为子词。若假设句子中的子词之间符合独立分布的 规律,则句子的语言模型 Si 的似然值就会与所有组词的 出现频率相等。具体计算公式如式(1)所示 :
在计算时,将处在相邻位置的子词 wi,j 和 wi,j+1 进行合并。合并后,可得到新词 wi z。在这种情况下,具体的语言模型似然值还可进一步获得变化值,变化值计算 公式如式(2)所示 :
在具体计算时需要注重应用好 WordPiece 算法对 子词进行选择与合并。选择时,需要选择 si 的语言模型 四燃脂变化值中的最大值进行合并,选择数量为两个。 这主要是由于这两个子词之间有非常紧密的关联,能够 反映出子词在很大概率上会同时出现在同一文本中。而 关于 BERT 模型的创新点,主要体现在训练方法方面, 在训练时主要通过捕捉单词和句子的嵌入向量达到训练 目标,并且随机将相关数据放入训练样本中,由 Token 进行遮盖,随机遮盖时,有 10% 的 Token 会在遮盖的 同时被替换为其他词语 ;另有 10% 的 Token 可不被替 换 ;其余的 80% 词汇都会被替换为 [MASK] 形式。
3 利用图神经网络法构建关系抽取模型
3.1 模型形式化分析
关系抽取过程的本质是将文本语料库中句子实体 间的关系通过正确划分形成对应标签。例如,在句子 中,人名和组织名属于从属关系,可在关系认证时将 其规定为包含关系。在模型形式化研究中,主要应用 REEGAT 模型实现词语嵌入编码器的操作,随后信息 可由 BERT 转化为 RoBERTa,虽经过转化,但两种模 型的输入信息仍然可保持一致,主要通过 TEi、SEi 以 及 PEi 三种 Embedding 相加获得。在下文的研究中, 通过应用 WCL-BBCD 模型中的符号进行进一步分析。
3.2 模型结构分析
模型结构在本文研究中分为三种形式 :(1)嵌入层。 嵌入层的基本结构包括 RoBERTa 模型以及 Embedding 模型。其中, RoBERTa 模型与 BERT 模型基本一致, 可实现双向输入, RoBERTa 模型输入的内容则主要为 文本 ;而 Embedding 则主要用于将关系类型进行标 注,并进一步实现对嵌入向量的训练。在输入关系的标签类别划分上,这一关系模型的输入关系标签为 id,输 出则表现为关系嵌入向量。(2) GAT 模型。此种模型主 要的功能在于加强词嵌入向量和关系嵌入向量之间的联 系紧密度。应用多头注意力机制分别从词汇嵌入向量和 关系嵌入向量两方面做加权计算。(3)实体嵌入组件, 实体嵌入组件,主要功能在于将 CAD 模型输出经过加 权后的 [3]。
3.3 模型训练分析
关系抽取模型训练中,首先需要对抽取任务的基本 性质进行明确。而关系抽取从本质上来说,属于对文本 进行分类的过程,在文本分类实践中,又包含多个分类 任务。在应用 REEGAT 模型进行模型训练时需要使用 交叉熵损失函数作为基本公式进行数据计算,具体计算 公式如式(3)所示 :
在公式(3) 中, N 表示训练样本数量, ri 表示句子 si 实体之间的关系结果数值, ri 表示具体 si 实体键关系 的预测结果。
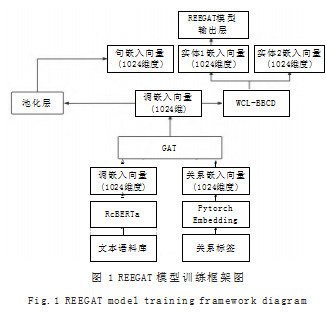
在开展模型训练时,主要采用 SGD 算法,对模型 参数进行优化训练模型的关键要点包括嵌入向量、实体 嵌入向量的构件、池化层的池化处理。池嵌入向量和关 系嵌入向量的构建文本语料库中的信息筛选与关系标签 标注。如图 1 所示为 REEGAT 模型训练框架图。
4 实验分析研究
4.1 数据预处理环节
此环节主要针对所有数据完成预处理过程,采用 IOB 标注法对原生英文数据进行标注。随后,再进一步实现 对数据信息的转化,转化时,需应用科学的转化算法, 分别从输入输出两个环节入手,进行数据的处理和转化。
4.2 模型有效性的实验结果
为验证模型性能需要实验分析,并且对比相关数 据词嵌入组件、CRF 组件、BiLSTM 组件需要联合应 用。在具体进行对比模型设置时,需要把握以下几方面 要点 :(1)是 BiLSTM 设置时,应使用独立组建构建 模型 ;(2)是 BiLSTM-CRF 设置时,需联合应用两种 组件来构建模型 ;(3)是在构建细节组建时,需要结合 嵌入组件中的包含元素分别与上述两个组件进行自主结 合,组件应用和组合方式需保证形式结构丰富全面 [4]。
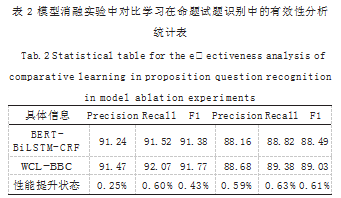
关于具体的实验结果。据对比分析可知, 经过模型 的重新构建和组合数据采集效率以及数据采集质量都获 得了显著提升。如表 2 所示为模型消融实验中对比学习 在命题实体识别中的有效性状态统计表。
通过表 2 分析可知, 在应用科学算法进行数据模型 结构的优化后,系统性能都得到了显著提升。由此可推 论,在应用图神经网络技术进行信息抽取时,相应的信息 抽取效果和系统运行性能也必然会得到显著提升。
5 结语
通过本文分析可知,在信息抽取过程中, 为提升抽 取精准性需应用科学算法对数据信息进行筛选分析,而 对比学习和图神经网络技术都需要搭建相应的数据平台, 并且通过应用科学有效的学习方法和计算方法对多元信 息进行筛选,尽可能通过精准筛选获得全面而准确的信 息。这是批量信息读取中需要达到的重要目标, 同时, 也是体现出信息抽取技术含量的重要方面。
参考文献
[1] 余英杰.基于卷积神经网络的图片深度学习和人工智能技术 在照片档案管理领域应用研究[J].中国档案,2023(1):31-33.
[2] 魏明珠,郑荣,高志豪,等.融合知识图谱和深度神经网络的产 业新兴技术预测模型研究[J].情报学报,2022.41(11):1134-1148.
[3] 王相海,赵晓阳,王鑫莹,等.非抽取小波边缘学习深度残差网 络的单幅图像超分辨率重建[J].电子学报,2022.50(7):1753-1765.
[4] 张嘉杰,过弋,王家辉,等.基于特征和结构信息增强的图神经 网络集成学习框架[J].计算机应用研究,2022.39(3):668-674.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/67867.html