SCI论文(www.lunwensci.com):
摘要:在骨架序列的动作识别中,为了更好的突出身体中不同部位的关联性,提出一种将人体骨架图定义为有向图来提取身体部位中的关键信息。首先找到每个关键部位的顶点,对任意的骨架关节点进行拼接工作;其次对给定的张量乘以对应部位的关联矩阵并执行聚合函数;最后根据依靠图卷积网络对得到的邻接矩阵进行空间流和时间流的卷积,并在训练阶段增加Res结构增强模型的稳定性。结果表明:该方法在NTU-RGBD数据集上的CS和CV子集上取得了87.6%和96.5%的准确率,更好的提高了视频中人体动作的准确率。
关键词:计算机视觉;图神经网络;骨架序列;动作识别
Action Recognition of Graph Neural Networks in Human Skeleton Sequences
LIU Xiaoqun,HAN Zhiheng
(Hebei Institute of Architecture and Engineering,Zhangjiakou Hebei 075000)
【Abstract】:In the action recognition of skeleton sequence,in order to better highlight the correlation of different parts of the body,a method is proposed to define the human skeleton graph as a directed graph to extract the key information in the body parts.Firstly,find the vertices of each key part,and splicing any skeleton joint points;Secondly,multiply the given tensor by the correlation matrix of the corresponding part and perform the aggregation function;Finally,according to the adjacency matrix obtained by relying on the graph convolution network convolution of spatial stream and temporal stream is performed,and the Res structure is added in the training phase to enhance the stability of the model.The results show that the method achieves 87.6%and 96.5%accuracy on the CS and CV subsets of the NTU-RGBD dataset,which better improves the accuracy of human actions in videos.
【Key words】:gomputer vision;graph neural network;skeleton sequence;action recognition
0引言
行为识别是计算机视觉中一项具有挑战性的研究方向,它是指在静态或动态的一系列信息中,通过某种特征提取方法,从所选对象及其周围环境中识别出特征对象的行为动作。动作识别可以使用基于RGB视频、图像和基于骨架数据特征提取。其中,骨架序列由视频中关节点在人体做出一系列行为动作时,通过学习前一段时间人体动作姿态来识别人体会做出的反应动作。与传统的RGB数据相比,基于骨架信息的数据没有把人作为一个运动整体来看,而更注重人体关节之间的联系性。因此,基于骨架信息的行为识别适应性强,不易受光照变换、环境遮挡以及人体外貌体型变化的影响。
早期骨架识别模型利用手工提取特征的方法,但是由于手工提取往往表现的特征有限且需要专业人员对参数优化有一定的敏感度。随着深度学习算法在计算机视觉方向上的发展,目前主流的识别方法有:(1)卷积神经网络(CNN)[1,2];(2)循环神经网络(RNN)[3];(3)图卷积神经网络(GCN)[4,5]。在基于神经网络有关动作识别算法的研究中,CNN通过将空间中的一个切片骨架数据转换成图像形式,再利用CNN在图像上提取相应的深度学习特征。Xu[6]等人提出3D卷积网络,考虑了在不受控制的环境中动作的完全识别情况。根据之前手工提取特征的缺陷,通过创造一个立体的卷积核并结合动作的相邻帧的运动轨迹,同时对空间和时间的纬度进行目标特征检测提取。最终的特征表示是组合所有输入帧生成的多通道信息。Ding[7]等人基于骨架特征在卷积神经网络使用不同的编码方法将五个空间骨架特征编码成图像,并研究了用于特征提取的不同关节对性能的影响。Simonyan[8]提出了双流网络结构,将RGB图像和光流分别输入到Alexnet神经网络中,并融合从RGB帧中提取图像信息的空间流以及从密集光流中提取运动信息的时间流。Li等基于双流网络的思想为了进一步提高系统的性能,构建了三流网络结构,将骨架的关节信息、骨架段信息和骨架的运动信息结合起来进行动作识别。
这些网络输入的骨架数据,在考虑划分区域时仅考虑了肢体间的相邻节点,忽视了不同身体节点之间的关联性。例如人体节点的手部相距很远,但实际动作“拍手”“鼓掌”“交叉”等两只手部的关系却很重要。针对上述问题,Shi等人将骨架数据表示为有向图的思想,本文提出一种不同身体部位的整体划分,使每个部分与其他部分产生关联。以提取的骨骼、关节和运动信息,基于GCN提取到的特征进行预测。
1多流自适应图卷积网络设计
1.1图卷积神经网络
对于人体行为来说,每个不一样的动作,在时间与空间上都存在着隐藏信息序列。在基于时空信息的人体动作过程中,每个动作在空间域表示为若干点的集合和时域中行为相邻若干帧之间的关联性。对于一个含有N个关节点和T帧的骨架序列G(V,E),骨架序列可以表示为X∈RN×T×d,d表示序列的纬度。
图卷积可定义为如式(1)所示:
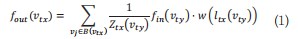
其中,v表示时空图上的顶点;B(vti)={vty|d(vty,vtx)≤D}是vtx的卷积采样区域,代表着vtx的所有邻居节点vty的集合,d(vty,vtx)表示从节点vty到vtx的任何关节的距离,本文中关节点采样路径长D=1;fin表示特征映射;w表示为权重函数;映射函数lti可以为特征向量分配权重;归一化项Ztx表示顶点vtx所在B(vtx)子集的基数。
使用邻接矩阵表示为如式(2)所示:
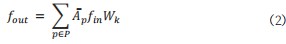

1.2基于身体部位的时空图卷积
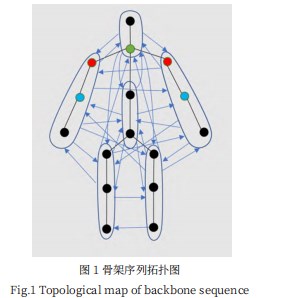
如图1所示,在基于骨架信息识别任务中,本文使用G=(P,E)表示骨架序列,其中P是一组表示身体某部位的结点,E为一组有向边。在时间维度上表示为S={G1,G2,G3…GT},T为视频长度。本文首先通过构建不同身体部位的每一帧来进行空间卷积,分别得到身体部位的空间特征和内在联系,描述骨架图的拓扑结构。
对于PGCN模块包含两个更新函数hp、he和聚合函数ge+、ge-。更新函数用于更新基于连接的部分和边的属性,聚合函数用于聚合连接到一个身体部分中边包含的属性。每个部分的处理过程表示如式(3)所示:

其中每个部位pi,所有指向它的边都有聚合函数ge-处理,处理结果为ei-;所有从pi发出的边都由聚合函数ge+处理,处理结果为ei+;pi、ei-、ei+被连接起来输出到更新函数hp,处理结果为pi';对于每条边ej,它的源部和目标点和自己一起被聚合函数he处理,处理结果为ej'。
图卷积的邻接矩阵可以表示为图的拓扑结构,增强了网络结构的灵活性。根据式(3),找到每个关键部位的顶点,对任意的骨架关节点进行拼接工作。其关键是在于寻找每个部位的出边与入边,对于每个部位来说,其关联矩阵是一个Np×Ne矩阵。对给定的C×T×Np的张量乘以对应部位的关联矩阵并执行聚合函数。步骤为:
步骤1:给定顶点部位的C×T×Np的张量fp,重塑为CT×Np乘以对应部分的关联矩阵Np×Ne,则可以得到CT×Ne张量。
步骤2:将输入特征映射到映射函数fin,并对每个部位进行加权,经过归一化和矩阵相乘得到定点部位的邻接矩阵。
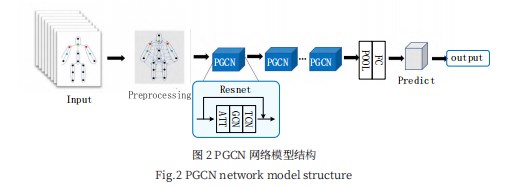
步骤3:执行1D卷积操作,再经过空间卷积和时间卷积后传入批标准化层和ReLU层形成PGCN块,经过9个这样的单元后,通过Pooling层和全连接层得到每个序列的特征向量,相邻PGCN块之间采用Resnet的结构,提高网络的稳定性。最后用SoftMax函数进行分类,得到最后的标签。
如图2所示,输入的骨架数据首先进行归一化,然后在经过9个PGCN单元,其中PGCN单元中包含空间处理模块GCN与时间处理模块TCN,通过一个Pooling层与全连接层后用SoftMax函数进行分类,得到最后的标签。每一个PGCN采用Resnet的结构,前三层的输出有64个通道,中间三层有128个通道,最后三层有256个通道,在每次经过PCGN结构后将随机丢弃一些特征。
2实验结果分析
2.1数据集与评价指标
NTURGB+D数据集,共有60个类别,56880个动作片,每个骨架序列有25个人体关节。该数据集有两种训练基准:(1)CS(Cross-Subject):包括40320个剪辑的片段作为训练集和16560个剪辑的片段作为测试集;(2)CV(Cross-View):包括37920个片段为训练集和18960个片段作为测试集。数据集采用每个序列300帧,深度学习框架为Pytorch1.6,优化策略为SGD,Batch Size为10,Epoch设置为90,学习率设置为0.1,在20、40、60、70、80、90分别衰减0.01。本文采用评价指标Top1-1识别准确率。
2.2实验结果分析
本文在NTU RGB+D数据集上的跨项目(CS)和跨视角(CV)的精度分别为87.2%、94.5%。如表1所示,相比AS-GCN分别提高了1.1%、0.3%。所对比的实验方法为:(1)基于RNN的方法Deep-LSTM;(2)基于CNN的方法TCN;(3)基于GCN的方法ST-GCN、AS-GCN。实验数据表明在通过关联矩阵的处理,无论是在参数量方面还是精度方面,更优秀的拓扑结构往往能产生较好的结果。
3结论
划分区域的一些拘束性,本文提出了基于身体部位的时空卷积识别方法。本方法将身体部位定义为有向图来提取骨架序列的关联性动作并定义其关联矩阵,将空间和运动信息融合在双流框架中并通过实验结果证明本模型的有效性。此外,在本文中仅使用了NTU-RGBD验证了本次的实验方法,在之后的工作中本模型会在Kinetics数据集上做进一步的讨论。
参考文献
[1]LIU M Y,LIU H,CHEN C.Enhanced Skeleton Visualization for View Invariant Human Action Recognition[J].Pattern Recognition,2017,68:346-362.
[2]LI C,ZHONG Q Y,XIE D,et al.Skeleton-based Action Recognition with Convolutional Neural Networks[OL].(2020-09-06)[2022-04-27].https://arxiv.org/pdf/1704.07595.pdf.
[3]SHAHROUDY A,LIU J,NG T T,et al.NTU RGB+D:ALarge Scale Dataset for 3D Human Activity Analysis[C]//Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition.Los Alamitos:IEEE Computer Society Press,2016:1010-1019.
[4]SHI L,ZHANG Y F,CHEN J,et al.Skeleton-based Action Recognition with Directed Graph Neural networks[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition,Long Beach,2019:7912-7921.
[5]LI M S,CHEN S H,CHEN X,et al.Actional-structural Graph Convolutional Networks for Skeleton-based Action Recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Los Alamitos:IEEE Computer Society Press,2019:3595-3603.
[6]JI S W,XU W,YANG M,et al.3D Convolutional Neural Net-works for Human Action Recognition[C]//IEEE Transactions on PatternAnalysis and Machine Intelligence,2013.
[7]DING Z W,WANG P C,OGUNBONA P O,et al.Investigation of Different Skeleton Features for CNN-based 3D Action Recognition[C]//2017 IEEE International Conference on Multimedia&Expo Workshops(ICMEW),2017:617-622.[8]Karen Simonyan,Andrew Zisserman.Two-stream Convolutional Networks for Action Recognition in Videos[C]//Neural Information Processing Systems.Montreal,Canada,2014:568-576.
[9]YAN S J,XIONG Y J,LIN D H.Spatial Temporal Graph Convolutional Networks for Skeleton-based Action Recognition[C]//AAAI Conference on Artificial Intelligence.New Orleans,USA,2018:7444-7452.
[10]SONG S,LAN C,XING J,et al.An End-to-End Spatio-temporal Attention Model for Human Action Recognition from Skeleton Data[C]//Proceedings of the 31st AAAI Conference on Artificial Intelligence.Palo Alto,CA:AAAI Press,2017:4263-4270.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/46493.html