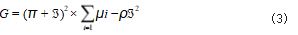SCI论文(www.lunwensci.com)
摘 要 :当前的中文命名实体快速识别层一般设置为单向目标,识别范围受限制,导致快速识别丢失率增加,为此提出对 基于深度学习的中文命名实体快速识别的设计与验证研究。根据实际的识别需求及标准,先进行识别特征的提取,采用多目标 的形式,打破识别范围的限制,设定识别节点及多目标识别层,构建深度学习中文命名实体识别模型,采用自适应交叉处理实 现中文命名实体快速识别。最终的测试结果表明 :对比于传统融合自注意力的 ALBERT 中文命名实体快速识别测试组、传统 BERT-DeepCAN-CRF 中文命名实体快速识别测试组,此次所设计的深度学习中文命名实体快速识别测试组最终得出的快速识 别丢失率被较好地控制在 21% 以下,说明此种识别处理方法的针对性与稳定性较强,对于复杂的识别环境仍然可以对所需要 抽取的数据信息进行精准定位,强化处理效果,误差可控,具有实际的应用价值。
Research on Fast Recognition of Chinese Named Entities Based on Deep Learning
YUAN Menglu, GUO Xiaoyan
(School of Science, Gansu Agricultural University, Lanzhou Gansu 730070)
【Abstract】:The current Chinese named entity fast recognition layer is generally set as a unidirectional target, and the recognition range is limited, resulting in an increase in the loss rate of fast recognition. Therefore, a research on the design and validation of deep learning based Chinese named entity fast recognition is proposed. Based on actual recognition requirements and standards, the recognition features are extracted first, using a multi-objective form to break the limitations of recognition range, setting recognition nodes and multi-objective recognition layers, constructing a deep learning Chinese named entity recognition model, and using adaptive cross processing to achieve fast recognition of Chinese named entities. The final test results show that compared to the traditional ALBERT Chinese named entity fast recognition test group and the traditional BERT-DeepCAN-CRF Chinese named entity fast recognition test group, the designed deep learning Chinese named entity fast recognition test group has a fast recognition loss rate that is well controlled below 21%, indicating that this recognition processing method has strong pertinence and stability, for complex recognition environments, it is still possible to accurately locate the data information that needs to be extracted, enhance processing effectiveness, and control errors, which has practical application value.
【Key words】:deep learning technology;Chinese naming;physical verification;quick identification;controllable identification;naming structure
0 引言
命名实体识别作为数据信息抽取的核心模块,近年 来,被广泛应用在智能问答、信息识别检索、机器处理 等工作的处理之中, 但是初始的中文命名实体快速识别方 法多为单向的,参考文献 [1] 和文献 [2],设定传统融合 自注意力的 ALBERT 中文命名实体快速识别方法、传统BERT-DeepCAN-CRF 中文命名实体快速识别方法。这一 类方法虽然可以实现预期的处理识别任务,但是实践过 程中缺乏针对性与稳定性,且较容易受到外部环境及特定因素的影响, 导致最终得出的识别结果出现误差 [3.4]
为此提出对基于深度学习的中文命名实体快速识别的研 究和验证。所谓深度学习,实际上是机器学习的一种,主要指的是学习样本数据的内在规律和表示层次,促使 机器可以像人一样思考与分析 [5]。将该项技术与深度学 习相融合,一定程度上可以进一步扩大实际的识别范 围,逐步形成一种更为灵活、多变的识别结构,在复杂 的背景环境下,可以更快、更及时地获取到精准、可靠 的识别结果,形成特殊的识别标注,为后续相关技术的 创新及发展提供参考依据及理论借鉴 [6]。
1 设计中文命名实体深度学习快速识别方法
1.1 提取识别特征
首先,中文命名实体是对群体数据信息中的特定实 体进行识别的,所以,可以结合实际的处理需求,预先 设定好初始的识别实体,并对其类别进行分化处理,大 致可以分为以下三种,分别是词级表示、字级表示以及 混合表示 [7.8], 从而实现对识别特征提取结构的设计与 分析,接下来,综合深度学习技术,设置中文命名实体 快速识别快速迁移矩阵,具体的框架如图 1 所示。
1.2 设定识别节点及多目标识别层
实现对识别特征的提取之后, 接下来,结合深度学 习技术,进行识别节点的部署及多目标识别层的设计。 通常情况下,为扩大实际的识别范围,明确识别目标, 均会选择部署识别监测点进行辅助处理,一定程度上可 以进一步强化识别的精度。在选定的语料库可控查询程 序中增设多个识别节点,通过核心节点下达指令,同时 确保每一个节点之间的距离一致,节点相互关联,建立 正向的识别处理关系。随后,结合深度学习技术,设置 多目标的中文命名实体识别层,分别是嵌入层、编码层 以及标签解码层。此时,结合实际的识别需求,进行识别单元值的计算,具体如公式(1)所示 :
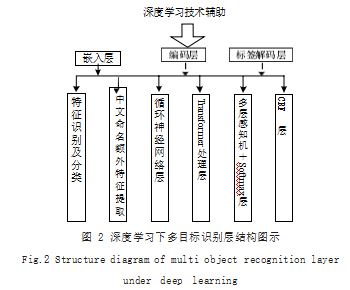
公式(1) 中 :K 表示识别单元值, ρ表示可识别范围, ϑ表示定向识别区域, t 表示深度学习次数, ℵ表示 转换比。依据得出的数值,结合设置的目标,细化分解 每一个识别层级,具体如图 2 所示。
根据图 2.完成对多目标识别层结构的设计与分析。在设定的矩阵中导入多种类的识别目标,建立循环 性的识别结构,为后续的标签解码分析奠定基础。
1.3 构建深度学习中文命名实体识别模型
结合深度学习技术,构建中文命名实体识别模型。 基于上述提取的识别特征,进行模型初始识别指标的设 置,如表 1 所示。
根据表 1.完成对中文命名实体识别模型指标的设 置。随即,以此为基础,结合深度学习技术,构建一个 循环式的实体识别模型内置结构,并设定具体的识别约束条件,如公式(2)所示 :
公式(2) 中 :W 表示识别约束条件, ε表示可控识 别区域, ϑ表示识别交叉单元值, W 表示深度学习识别 次数, ζ表示权重值, k 表示目标函数。将上述计算的 数值设置在模型内部,调整当前的识别机制,优化识别 的结构,以此来结合深度学习技术,强化模型的应用实 践能力。
1.4 自适应交叉处理实现中文命名实体快速识别
自适应交叉处理实际上是对得出的中文命名实体快 速识别模糊结果进行二次比照,针对存在异常的抽取区域作出合理修正,以此来确保最终得出结果的真实性与 可靠性,具体的自适应处理流程如图 3 所示。
根据图 3.完成对自适应交叉修正处理结构的设计 与应用。随即,利用上述构建的识别模型将修正之后的 结果与初始设定的结果标准进行比照,确定无误差之 后,输出最终的中文命名实体快速识别结果,完成基础 识别任务的处理。
2 方法测试
2.1 测试准备
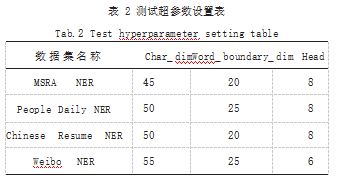
结合深度学习技术,对 H 语料库的中文命名实体快 速识别测试环境进行设定与搭建。H 语料库实际上是一 种公开性的料库,通过设置不同的限定条件和命名识别 指令进行数据及信息的定位、标注及抽取,以此来完成 最终的识别目标。首先,根据实际的识别需求及标准, 进行初始数据集的设置。选择该语料库中的 4 个类型的 数据信息集进行测定分析,分别为 MSRA NER(Levow et al)、People Daily NER(Li et al)、Weibo NER(Peng et al) 以及 Chinese Resume NER(Zhang et al)。每 一个数据集的识别要求及任务均是不同的,存在较大的 差异性。接下来,进行测试超参数的设置,具体如表 2 所示。
根据表 2.实现对选定数据集测试超参数的设置与 调整,形成一个稳定的测试环境。上述构建的 4 个数据 集中构建集成性的识别任务指令,指令的数量也设置为 40 条。4 种数据集均需要进行同步测定识别。接下来,结合深度学习技术,设计具体的快速识别框架,这部分 可以采用 Tensorflow1.13.1 框架, 结合选定的语料库 进行训练识别。依据初始设定的识别 Character 特征, 结合得出的数据和信息,计算出识别处理中的可嵌入维度,具体如公式(3)所示 :
公式(3) 中 :G 表示可嵌入维度, π表示特征维数, ℑ 表示转换识别比, µ表示识别单元值, i 表示识别频 率, ρ表示深度学习率。根据上述测定,完成对可嵌入 维度的计算。接下来,基于深度学习技术,调整实际的 快速识别框架,强化识别结构的处理效率,并扩大识别 范围。随即, 以此为基础, 设置 Droup_keep 为 0.25. BiLSTM 的单元识别层数设为 2. Epochs 设为 65.在 上述设计的识别模型中增设梯度截断结构和对目标识别 程序,以此来防止梯度爆炸,便于通过 Dropout 技术 来防止过渡拟合识别,确保最终识别结果的真实性与稳 定性,至此,结合深度学习技术,完成对基础测试环境 的搭建,接下来,进行具体的测试分析。
2.2 测试过程及结果分析
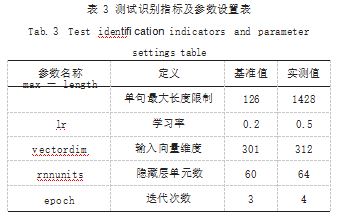
针对上述搭建的测试环境, 结合深度学习技术,对 H 中文语料库的命名实体快速识别方法进行测试与验证 研究。首先,对选定的 4 个数据集进行集中性的处理及 初始训练,形成一个统一的调整形式,随后,设置测试 识别相关指标及参数,具体如表 3 所示。
根据表 3.实现对测试指标参数的调整,随即,以 此为基础,将准备设定好的 40 条中文命名实体识别指 令依据分类逐一导入内置的控制识别程序之中,按照顺 序下达执行,最终进行快速识别丢失率的计算,具体如 公式(4)所示 :
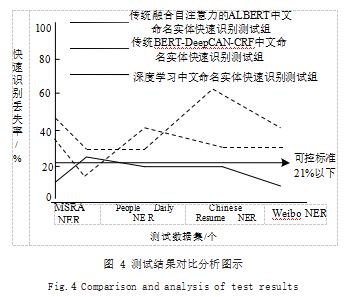
公式(4) 中 :P 表示快速识别丢失率, δ表示初始 识别范围, ν 表示定向识别偏差, ι 表示深度学习率。根根据图 4.实现对测试结果的分析和研究 :对比于 传统融合自注意力的 ALBERT 中文命名实体快速识别 测试组、传统 BERT-DeepCAN-CRF 中文命名实体快 速识别测试组,此次所设计的深度学习中文命名实体快 速识别测试组最终得出的快速识别丢失率被较好地控制 在 21% 以下,说明此种识别处理方法的针对性与稳定 性较强,对于复杂的识别环境仍然可以对所需要抽取的 数据信息进行精准定位,强化处理效果,误差可控,具 有实际的应用价值。
3 结语
总而言之,以上便是对基于深度学习的中文命名实 体快速识别的验证与研究。与初始的命名实体识别方式 相比对,此次综合深度学习技术,所设计的识别结构更 加稳定、多元,针对性较强,在较为烦琐的网络处理环境中,可以对需要抽取的数据及信息进行特殊标注,逐 步形成一个循环性的识别结构,从多个角度进行识别处 理及解析研究。此外,通过深度学习技术的辅助与支 持,针对大规模的识别任务,能够通过列表收集、特征 空间、资源消耗、运行时长等特点进行协同自适应识别 处理,进一步扩大当前的识别效率及质量,减少日常的 训练时间,为后续的处理奠定坚实的环境。
参考文献
[1] 游乐圻,裴忠民,罗章凯.融合自注意力的ALBERT中文命名 实体识别方法[J].计算机工程与设计,2023.44(2):605-611.
[2] 谢斌红,张露露,赵红燕.基于BERT-DeepCAN-CRF的中文 命名实体识别方法[J].计算机与数字工程,2022.50(12):2720- 2726.
[3] 郭小磊,张吴波.基于ERNIE-BiGRU-CRF-FL的中文命名实 体识别方法[J].山西大同大学学报(自然科学版),2022.38(6):23- 28.
[4] 韩晓凯,岳颀,褚晶,等.基于注意力增强的点阵TransFormer 的中文命名实体识别方法[J].厦门大学学报(自然科学版),2022. 61(6):1062-1071.
[5] 康怡琳,孙璐冰,朱容波,等.深度学习中文命名实体识别研究 综述[J].华中科技大学学报(自然科学版),2022.50(11):44-53.
[6] 张召武,徐彬,高克宁,等.面向教育领域的基于SVR-BiGRU- CRF中文命名实体识别方法[J].中文信息学报,2022.36(7):114- 122.
[7] 张汝佳,代璐,王邦,等.基于深度学习的中文命名实体识别最 新研究进展综述[J].中文信息学报,2022.36(6):20-35.
[8] 吕海峰,冀肖榆,陈伟业,等.基于ALBERT预训练模型的通用 中文命名实体识别方法[J].梧州学院学报,2022.32(3):10-17.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/65185.html