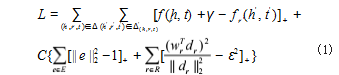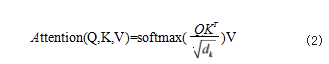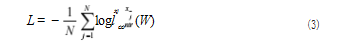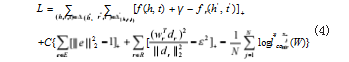SCI论文(www.lunwensci.com)
摘 要:翻译模型在进行知识图谱补全的过程中往往会忽略三元组中的语义信息。为弥补这一缺陷,本文构造了一种融合 自适应增强语义信息的知识图谱补全方法。通过微调 BERT 模型获取三元组中的语义信息,并对高纬度向量做降维处理,最后 运用注意力机制生成语义信息软约束规则,将该规则添加至原翻译模型中实现语义信息的自适应增强。经实验对比,本文所提 方法较原翻译模型在数值上约提升 2.6%,验证了方法的合理性与有效性。
A Knowledge Graph Completion Method with Adaptive Enhancement of
Semantic Information
YIN Zengxiang, JI Weidong
(School of Computer Science and Information Engineering, Harbin Normal University, Harbin Heilongjiang 150025)
【Abstract】:Translation models tend to ignore the semantic information in triads in the process of knowledge graph complementation. To remedy this shortcoming, this paper constructs a knowledge graph complementation method that incorporates adaptively enhanced semantic information. The semantic information in the triad is obtained by fine-tuning the BERT model, and the high-latitude vectors are dimensionally reduced. Finally, the attention mechanism is applied to generate soft constraint rules for semantic information, and the rules are added to the original translation model to achieve adaptive enhancement of semantic information. After the experimental comparison, the proposed method improves about 2.6% in value compared with the original translation model, which verifies the reasonableness and effectiveness of the method.
【Key words】:knowledge graph complementation;semantic information extraction;word vector dimensionality reduction;attention mechanism
0 引言
随着大数据时代的到来,数据之间的联系愈发成为 研究热点。使用传统方式对数据进行建模已经不再现 实。知识图谱作为自然语言处理领域中快速发展的分 支,可将符号化的知识构建成为三元组,以解决现实世 界中的许多问题。由于知识图谱天生的不完整性,多数 现有的知识图谱都是稀疏的,由此产生了新的任务 :知 识图谱补全,目的在于预测知识图谱中缺失的三元组。
近些年来,针对知识图谱补全任务专家学者提出了 许多解决方案。由 Bordes A 等人 [1] 提出的 TransE 模型, 将头实体和尾实体都表示成向量,用“头实体 + 关系=尾实体”去优化损失。ZhenW[2] 等人提出了 TransH 模型, 模型将三元组中的关系抽象成一个向量平面,将头结点 或者尾节点映射到这个超平面上,通过在超平面上的平 移向量计算头尾结点的差值,弥补了 TransE 模型在处 理一对多或多对多关系上出现的结果偏差。
考虑到对三元组中语义信息的运用, Yao L 等人 [3] 提出了 KG-BERT 模型, 采用由 Devlin J 等人 [4] 提出 的预训练语言模型 BERT 来补全知识图谱,将知识图谱 中的三元组视为文本序列, 并提出新框架 KG-BERT。 Wang B[5] 等人提出了一种 StAR 模型,采用确定性分 类器和空间度量进行表示和结构学习。它通过重用图形元素的嵌入来避免组合爆炸,从而减少了开销。
在知识图谱补全的过程中,三元组的结构信息与语 义信息能够起到不同作用。结构层面的补全方法由于仅 仅考虑三元组结构信息,忽略语义信息对补全的影响, 导致文本语义未能物尽其用。而语义层面上的补全方法 虽然能够对语义信息进行向量化,但是由于庞大存储与 运算的开销,影响了知识图谱补全效率。
针对上述问题,本文提出了一种融合自适应增强语 义信息的知识图谱补全方法(AESI-KGC)。主要贡献 体现在以下几点 :(1)构建了一种三元组语义特征的提 取方式,生成带有语义信息的三元组词向量编码 ;(2) 构造了一种降维方法,提高了模型训练效率 ;(3)结合 注意力机制构造了语信息义软约束规则。
1 融合自适应增强语义信息的知识图谱补全方法
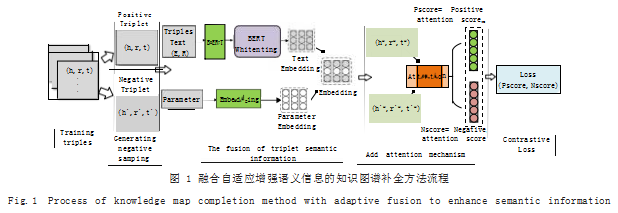
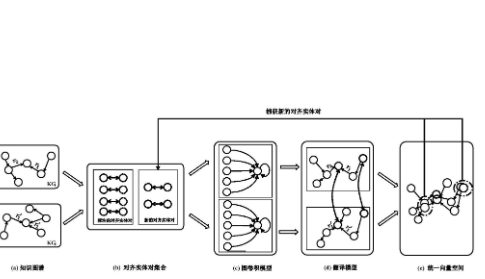
本文提出了一种融合自适应增强语义信息的知识图 谱补全方法,此方法由 3 个部分组成,分别是对三元组语义信息的提取,高纬度词向量的降维,语义信息约束 的构造,方法流程如图 1 所示。正三元组表示为(h, r, t)。
其中h表示头实体, t 表示尾实体, r 表示连接两个实体 的关系。负三元组表示为(h` , r` , t` ) , 带语义信息的三元组 表为(h* , r* ,t* ) 和(h`* , r`* , t`* )。Text Embedding 表示通 过 BERT 生成的语义信息向量,Parameter Embedding 表示参数嵌入向量, Pscore、Nscore 为正负三元组语义 注意力得分, Loss 为计算正负三元组语义对比损失函数。
1.1 基于翻译的距离模型 TransH
本文所提出的方法是在 TransH 模型的基础上添加语 义信息约束条件形成的。该模型的具体思路是将三元组中 的关系抽象成一个向量空间中的超平面,每次都将头结点 或者尾节点映射到这个超平面上,再通过超平面上的平移向量计算头尾节点的差值。损失函数如公式 (1) 所示 :
1.2 三元组语义信息的提取
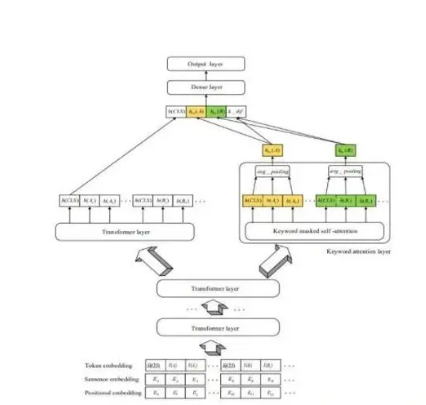
语义信息的融合采用 BERT 对三元组的语义信息进 行编码。BERT 的输入为三元组中实体和关系的文本信 息。采用字符串拼接的方式将“[CLS]+ 文本信息 +[SEP]” 拼接成为一个字符串。将该字符串通过单词词典生成 Token,以及每一个 Token 对应的表征,之后经过 BERT 的 MLM 生成双向语言表征。实体和关系的词向量是对每 个 Token 的倒数第二个隐藏层求平均,生成长度为 768 的向量,这样就获得了 BERT 生成的语义信息向量。
1.3 高纬度词向量的降维
上述方法中,获得了语义词向量。由于 768 维的词 向量对于后续语义注意力的计算有很大的内存挑战。因 此参考 Su J 等人 [6] 提出的 BERT-whitenin 模型对向量 进行降维,具体流程如算法 1 所示 :
令 k=128.输入为 BERT 生成的三元组语义向量, 通过上述算法,最终得到 128 维语义向量表示。
1.4 语义信息约束的构造
语义信息约束的构造采用由 Vaswani A 等人 [7] 提 出的注意力机制,具体做法为将语义信息向量与参数向 量进行加和得到关于参数的语义信息表示。Q、K、V分别为头、尾、关系向量。Q、K 与伸缩因子
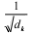
相乘
通过 Softmax 归一化后,与 V 相乘最终得到注意力输 出。具体计算方法如公式 (2) 所示 :
正负三元组在经过以上注意力的运算后得到关于语 义信息的注意力得分,获取二者的得分之后,我们采用 了一种全新语义信息对比损失函数,如公式(3)所示 :
其中 xj , xj(~) 表示的是来自同一语义下两种不同数据增强的输入向量。将正负样本的语义信息通过上述 的 Loss 函数进行对比损失优化,更改公式(1)的表达式,得到模型的最终 Loss 函数如公式 (4) 所示 :
2 实验与评估
2.1 实验数据集
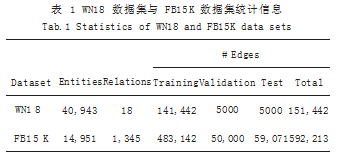
实验使用了两种数据集,分别是 WIN18 以及 FB15k。 如表 1 所示提供了实验所用数据集的统计信息。
2.2 实验结果分析
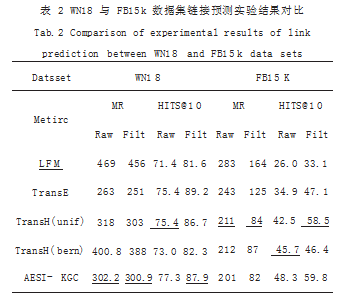
如表 2 所示是 WN18 和 FB15K 测试集的实验结果。 其中 HITS@10 数值以百分比表示,最佳分数用粗体表 示,次佳分数用下划线表示。
根据表 2 可知, TransE 模型在关系数量较少的 WN18 数据集表现中 MR 测试评分最好,其次便是 AESI-KGC 方法。相较于 TransH 模型,AESI-KGC 方法获得了次佳效 果。在 HITS@10 的测试实验中, 添加了 AESI-KGC 方法 比原始模型 TransH 在 Raw 的数值上提升了 2.3%,在 Filt 的数值上提升了 1.2%。在关系数量更多的 FB15K 数据集中, TransH 模型效果劣于 AESI-KGC 方法。添 加了 AESI-KGC 方法的模型在 MR 以及 HITS@10 实验 数值上均有一定程度地提升。在 MR 的实验中 Raw 条件 下提升了 10.Filt 条件下提升了 5.在 HITS@10 实验中, Raw 条件下提升了 2.6%,Filt 条件下提升了 1.3%。
3 结语
本文提出了一种融合自适应增强语义信息的知识图 谱补全方法(AESI-KGC)。将该方法添加至 TransH 模型中进行实验,实验结果表明,在增加了本文所提 出的方法后,原模型得到了进一步的改善,有效提升了 TransH 模型的补全成功率。
参考文献
[1] BORDES A,USUNIER N,GARCIA-DURAN A,et al. Irreflexive and Hierarchical Relations as Translations[J]. Compyter Science,2013
[2] WANG Z,ZHANG J W,FENG J L,et al.Knowledge Graph Embedding by Translating on Hyperplanes[C]// Proceedings oftheAAAI Conference onArtificial Intelligence, 2014.
[3] YAO L,MAO C S,LUO Y.KG-BERT:BERT for Knowledge Graph Completion[J].ArXiv Preprint ArXiv:1909.03193. 2019.
[4] DEVLIN J,CHANG M W,LEE K,et al.Bert:Pre-training of Deep Bidirectional Transformers for Language Understanding[C]//Conference on the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2019:4171-4186.
[5] WANG B,SHEN T,LONG G D,et al.Structure-augmented Text Representation Learning for Efficient Knowledge Graph Completion[C]//Proceedings ofthe Web Conference 2021:1737-1748.
[6] SU J L,CAO J R,LIU W J,et al.Whitening Sentence Representations for Better Semantics and Faster Retrieval[J]. ArXiv Preprint ArXiv,2103.15316.2021.
[7] VASWANI A,SHAZEER N,PARMAR N,et al.Attention is All You Need[J].Advances in Neural Information Processing Systems,2017:30.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/58910.html