SCI论文(www.lunwensci.com)
摘 要:本文旨在为国内图书馆开发一款免费的希腊文转写工具,从而提升希腊文转写的准确率和效率。综合运用文献分 析法、穷举算法和实证研究法,以 ALA-LC 希腊语罗马化表(2010)为研究对象,从大小写、字母位置、双元音、变音符号 等维度深挖算法规律。经项目合作者用 C# 程序语言编程实现后,编制数量充足的高质量单元测试验证算法的准确性和适用性, 并据此优化算法。经测试得出结论 :现阶段的转写平台能够较好地完成希腊文基础转写。综合测试是一项长期任务,需在积累 中完善算法实现算力新突破。
Design and Implementation of Algorithm for Transliteration Platform Based on ALA-LC Romanization Table for Greek
LI Yirui
(National Library of China, Beijing 100081)
【Abstract】: This article aims to develop a free Greek transliteration tool for domestic libraries, so as to improve the accuracy and efficiency of Greek transliteration. Comprehensively using documentary analysis, exhaustive algorithms and empirical research, taking the ALA-LC romanization table :Greek(2010) as the research object, the algorithm is deeply explored from the dimensions of upper and lower case, letter position, diphthong, diacritic and so on. After the project collaborators programed and implemented it in C# programming language, a sufficient number of high-quality unit tests have been prepared to verify the accuracy and applicability of the algorithm, and the algorithm has been optimized accordingly. After testing, it is concluded that the transliteration platform at this stage can complete the basic Greek transliteration well. Comprehensive testing is a long-term task, and it is necessary to improve the algorithm in the accumulation to achieve new breakthroughs in computing power.
【Key words】: ALA-LC Romanization Tables :Greek(2010);transliteration;algorithm
引言
近年来,国内的外文编目基本遵循主流国际标准,且 积极关注图书馆前沿理论的发展与应用。《国际编目原则 声 明》(The Statement of International CataloguingPrinciples, 简称 ICP)(2016 版) 第5.3.2.2条例 [1] 提出转写 (Transliteration)规范检索点需遵循相应的国际标准。 《资源描述与检索》(Resource Description and Access, 简称 RDA) 建议编目员如实转录文献资源的原始文字, 但要使用罗马化(Romanized) 形式的检索点 [2]。希腊文 属于非拉丁文字,依据 ICP 条例和 RDA 规则,国内希 腊文编目需要对检索点文字进行罗马化,即转写。经充 分调研,国际图书馆界应用较广的希腊语罗马化方案是ALA-LC 希腊语罗马化表(2010)。Worldcat 网站 的希 腊文书目数据多采用该表进行罗马化。美国国会图书馆 (Library of Congress, 简称 LC) 现有专为 MARC 数据 开发的希腊文转写软件。2022 年 4 月, LC 面向全球发布了关于开发 BIBFRAME 转写程序的招标合同。该合 同指出为支持多种系统组件并辅助终端用户,需要对部 分非拉丁文字数据元素进行转写 [3] , 且 BIBFRAME 编 辑器 [4] 目前不支持希腊文转写,而国内希腊文编目暂无 自动转写工具,需要人工转写,但是人工转写的准确率和 效率远低于自动转写。文化和语言背景差异大,希腊文编 目专业性强,从事希腊文编目的工作者数量少。经调研测 试,网络上现有的网页工具并非按 ALA-LC 希腊语罗马 化表(2010)开发,少量以该表开发的 GitHub 共享程 序的算法又无法满足希腊文编目的实际需要。因此,专 为国内希腊文编目工作者开发一款能自动转写希腊文的 工具刻不容缓。本文从希腊文编目的转写需求切入,以 ALA-LC 希腊语罗马化表(2010)为研究对象,通过对 其内容和特点的剖析,试编写一套实用的希腊文转写算 法,经项目合作者用 C# 程序语言编程实现后,用充足 的高质量希腊文数据作为单元测试实例来验证转写算法 的准确性和适用性。
1 研究方法
希腊文转写平台开发包含算法设计、编程实现、算 法测试、完善算法 4 个主要部分。其中编程实现主要由 合作程序员独立完成。本文综合运用文献分析法、穷举 算法和实证研究法完成希腊文转写平台算法的设计和验 证。首先,根据多年图书馆希腊文编目经验,使用文献 分析法深入调研 ALA-LC 希腊语罗马化表(2010)的 背景、发展和应用,再分析该表的内容与特点,从而揭 示深层转写规律,为撰写算法文档提供基础。其次,运 用穷举算法试挖掘此表包含的所有转写结果,包括未明 确表述的转写结果。大致按希腊字母顺序分组编写算法, 重点是检验第一步总结的内容特征,挖掘、提取共性特 征并转换为算法。然后,再通过编写单元测试验证算法 的准确性和适用性,这部分工作由人工转写和程序测试 相互检验。合作者面对相同的需求文档,但分别使用各 自领域工作技术完成转写。编目人员完成人工转写, 并 通过查阅数据源判断转写结果的准确性。程序员能够熟 练调用函数,通过计算机程序判断代码的准确性,从而 能够为算法的准确性和适用性提供双重保险。根据算法 包含的转写结果种类,选取足量的高质量希腊文数据进 行算法测试。最后,综合分析测试结果,据此调整和完 善算法。
2 研究对象
2.1 简介
20 世纪 60 年代,随着美国地名委员会 / 英国官用地名常设委员会(The United States Board on Geographic
Names/The Permanent Committee on Geographical Names, 简称 BGN/PCGN) [5]、国际标准化组织 (ISO)[6] 先 后颁布了各自的希腊语罗马化方案后,美国图书馆协会 - 美国国会图书馆(American Library Association-Library of Congress, 简称 ALA-LC) 在一封电子邮件中提及了 1972 年使用的某个希腊语罗马化表 [7]。1997 年,ALA 和 LC 联合出版了《ALA-LC 罗马化表:非罗马文字转写 方案》(AlA-LC Romanization Tables: Transliteration Schemes for Non-Roman Scripts) [8] ,其中包含希腊 语罗马化表(1997)。2010 年,ALA-LC 发布了电子版 希腊语罗马化表(2010) [9]。前期调研表明, ALA-LC 希 腊语罗马化表(2010)被北美和其他地区图书馆广泛接 受并沿用至今。2011 年 11 月, LC 政策和标准部开展了 一项与罗马化有关的项目。该项目指出创建罗马化数据 是为帮助 LC 及有相同需求的图书馆弥补语言技能和系 统功能不足 [2]。LC 不少书目数据和规范数据都包含罗马 化部分,这些罗马化部分由信息组织者创建,被广泛应 用于多个部门。全球最新的信息组织宝典— RDA 不仅 包含非拉丁文字的罗马化通用规则, 也包含了希腊文文 献处理细则。BIBFRAME 及其编辑器 Marva 的研发同 样为非拉丁文字罗马化留足了扩展空间。Marva 至今仍 未推出希腊文罗马化功能。
2.2 内容特点
ALA-LC 希腊语罗马化表(2010)的内容包括希腊 字母转写为拉丁字母、转写注释、转写实例和希腊数字 转写。其中,希腊字母细分为 24 个常用字母和 2 个古 体字母。转写注释界定了希腊语细分时间点以及对变音 符号的转写说明。此表列举的希腊数字均由希腊字母和 希腊数字符号组成,如 α' (=1)和 ,α(=1000)。
常用希腊字母转写特点:(1)语种细分。此表以 1453 年为时间点,将希腊语细分为古希腊语(到 1453 年)和现代希腊语(1453 年后)。只有希腊字母 Β/β 按 语种细分时有两种转写结果,古希腊语转写为拉丁字母 B/b,现代希腊语转写为拉丁字母 V/v。(2)字母组合。 希腊字母 Γ/γ、Μ/μ、Ν/ν 与特定希腊字母组合时, 转写 结果不同。如希腊字母 ΓΓ 转写为拉丁字母 NG, γχ 转 写为拉丁字母 nch。(3)变音符号和字母组合。有气号 (dasia)和希腊字母 Ρ/ρ 组合转写为拉丁字母 RH/rh。 (4)字母位置。如希腊字母 μπ 位于词首转写为拉丁字 母 b, μπ 位于词中和词尾时转写为拉丁字母 mp。(5) 长元音。希腊字母 Η/η 和 Ω/ω 都是长元音,分别转写 为带长音符的 Ē/ē 和 Ō/ō。(6)双元音。希腊字母 Υ/υ 分别与 Α/α、Ε/ε、Η/η、Ο/ο、Ι/ι、Ω/ω 组合为双元音时,该字母转写为拉丁字母 U/u。(7)字母数量。部分希腊 字母转写后变为两个拉丁字母,如希腊字母 Φφ 转写为 拉丁字母 PH/ph。有的希腊字母组合转写后变为一个拉 丁字母,如希腊字母 ντ 位于词首时转写为拉丁字母 ḏ。
此表转写实例情况全面,以古希腊语(包括中世纪 希腊语)和现代希腊语为时间段分别举例,转写实例体 现了转写注释包含的不同情况。此外,转写实例基本表明 了 LC 处理希腊文转写对大小写、标点符号采取的方式。 2.3 转写规律
根据 ALA-LC 希腊语罗马化表(2010)的内容特 点,除该表明确指出的转写规则外,试深入总结了如下 转写规律。
2.3.1 大小写
转写后的拉丁单词、词组或句子遵循英文大小写通 用规则,如人名、地名等大小写规则。(1)字母。单独 一个或两个希腊字母的大小写决定了转写后拉丁字母的 大小写。如希腊字母 Α 转写为拉丁字母 A,希腊字母组 合 Γκ 位于词首时转写为拉丁字母 Gk。(2)单词。希 腊单词 ΑΣΚΡΑΙΟΥ 转写为拉丁单词 Askraiou。由此可 知,全部大写的一个希腊名词转写后,只有词首拉丁字 母大写,其余拉丁字母均为小写,一个全部小写的希腊 单词转写为全部小写的拉丁单词,一个只有首字母大写 的希腊单词转写后,拉丁单词只有首字母大写。(3)词 组或句子。希腊文词组或句子转写后拉丁字母大小写遵 循英文通用规则和上述已总结的规则。一个全部大写的 希腊文词组或句子转写后,词组或句首拉丁字母需大 写,一个全部小写的希腊文词组或句子转写后,词组或 句首字母无需大写,一个大小写混合的希腊文词组或句 子,希腊字母大小写决定了转写后拉丁字母大小写。
2.3.2 变音符号
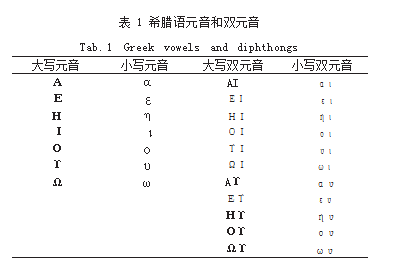
ALA-LC 希腊语罗马化表(2010)注释部分的主要 内容是转写希腊文时变音符号的处理方法。(1)有气 号。当有气号与希腊语元音或双元音同时出现时,有气 号转写为拉丁字母 H/h, 且前置于转写后的希腊语元音 或双元音。如表 1 所示穷举了无变音符号的希腊语元音 和双元音。希腊语双元音可视为一个整体,将有气号转 写为拉丁字母 H/h 并前置于转写后的双元音字母。当 有气号和希腊字母 Ρ/ρ 一同出现时,转写后的拉丁字母 H/h 后置于拉丁字母 R/r。(2)其他变音符号。省略有 气号以外的变音符号。(3)此表省略了需自主判断添加 有气号的情况。
2.3.3 字母位置
除了上述有气号的特殊转写方法, ALA-LC 希腊语罗马化表(2010) 还提出了如下和字母位置相关的转写 方法。希腊字母组合 γκ 位于词首和词尾转写为拉丁字 母组合 gk,位于词中转写为拉丁字母组合 nk。希腊字 母组合 μπ 位于词首转写为拉丁字母 b,位于词中和词 尾转写为拉丁字母组合 mp。希腊字母组合 Ντ 位于词 首,转写为拉丁字母 Ḏ。希腊字母组合 ντ 位于词中和 词尾转写为拉丁字母 nt。
2.3.4 双元音
ALA-LC 希腊语罗马化表(2010)明确了希腊字母 υ 和其他元音字母组合成双元音(αυ、ευ、ηυ、ου、υι 和 ωυ) 时, 该希腊字母转写为拉丁字母 u。结合上文 对有气号的论述,特别设计了双元音穷举算法。试涵盖 有气号和希腊语双元音字母组合时全部的转写结果。
根据表 1 穷举的元音和双元音字母, 将带有气号和 带其他变音符号的不同情况进行排列组合,以此试穷举 希腊语变音符号与双元音组合的所有情况。以 ΑΙ、αι 为例,具体算法如下。此算法的大小写规则和 LC 有所 区别,即全部大写的希腊字母和词句目前转写为全部大 写的拉丁字母。
(1)大写希腊字母 Α :
①大写希腊字母带有气号集合(upper_alpha with_ dasia) :Ἁ Ἃ Ἅ Ἇ ᾉ ᾋ ᾍ ᾏ (8 个) → HA。本集合中 任意 1 个字符转写为拉丁字母 HA。
②大写希腊字母无有气号集合(upper_alpha_without_ dasia) :Α Ά Ά Ὰ Ᾰ Ᾱ Ἀ Ἄ Ἂᾎ ᾼ Ἆ ᾈ ᾌ ᾊ (15 个) → A。 本集合中任意 1 个字符转写为拉丁字母 A。
(2)小写希腊字母 α :
③小写希腊字母带有气号集合(lower_alpha with_ dasia) :ἁ ἃ ἅ ἇ ᾁ ᾃ ᾅ ᾇ (8 个) → ha。本集合中任意 1 个字符转写为拉丁字母 ha。
④小写希腊字母无有气号集合(lower_alpha_without_ dasia) :α ά ά ὰ ᾰ ᾱ ᾷ ἀ ἄ ἂ ᾆ ᾶ ᾳ ᾴ ᾲ ἆ ᾀ ᾄ ᾂ (19 个) → a。
本集合中任意 1 个字符转写为拉丁字母 a。
(3)双元音 ΑΙ、αι 等 :
⑤大写希腊字母带有气号集合(upper_iota with_ dasia) :Ἱ Ἵ Ἳ Ἷ (4 个)。
⑥大写希腊字母无有气号集合(upper_iota_without_ dasia) :Ι Ί Ί Ὶ Ϊ Ῐ Ῑ Ἰ Ἲ Ἴ Ἶ (11 个)。
大写首字母可取 :
集合(upper_alpha_without_dasia)中任意字符。
第二字母可取 :
集合(upper_iota with_dasia) ;
集合(upper_iota_without_dasia) ;
集合(lower_iota with_dasia) ;
集合(lower_iota_without_dasia)中任意字符。
小写首字母可取 :
集合(lower_alpha_without_dasia)中任意字符。
小写第二字母可取可取 :
集合(lower_iota with_dasia) ;
集合(lower_iota_without_dasia)中任意字符。
使用不同的字符集合, 会产生如下 6 类不同的转写 结果 :
集合(upper_alpha_without_dasia)+ 集合(upper_ iota with_dasia) → HAI ;
集合(upper_alpha_without_dasia)+ 集合(upper_ iota_without_dasia) → AI ;
集合(upper_alpha_without_dasia) + 集合(lower_ iota with_dasia) → Hai ;
集合(upper_alpha without__dasia) + 集合(lower_ iota_without_dasia) → Ai ;
集合(lower_alpha_without_dasia) + 集合(lower_ iota with_dasia) → hai ;
集合(lower_alpha_without_dasia) + 集合(lower_ iota without__dasia) → ai。
上述转写结果是否有拉丁字母 H 或 h 由双元音第 二个字母是否带有气号(dasia)所决定。因此,双元 音第二个字母包含气号(dasia),罗马化结果为 HAI、 Hai、hai ;反之, 罗马化结果为 AI、Ai、ai。根据大 小写转写规则,罗马化后首字母大小写取决于希腊双元 音首字母大小写。因此,双元音首字母为大写,转写结 果首字母为大写 ;反之,转写结果首字母为小写。
3 算法测试
3.1 单元测试
通过编程实现算法设计后,继续编制覆盖全部算法 的测试数据,以此验证算法的准确性和适用性。单元测试分为前期测试、基础测试和综合测试。前期测试以单 个或少量算法点为主 ;在此基础上,基础测试选用实 例单词,按希腊字母顺序分组编写。根据算法设计部 分,每个希腊字母都包含互斥的转写规则 ;综合测试分 两个阶段,第一阶段用例取自 ALA-LC 希腊语罗马化表 (2010)的实例部分,第二阶段以应用 ALA-LC 希腊语 罗马化表(2010)的图书馆为样例来源,尽量选取有转 写参照的样例。为保证用例的真实性和有效性,单元测 试用例几乎全部取自专业的希腊文文献,少部分取自互 联网。
前期测试目的是搭建基本算法框架,保证独立的算 法点能够在程序中实现。
在基础测试部分,编写了 6 组基础单元测试,每 4 个希腊字母为一组。按照 ALA-LC 希腊语罗马化表 (2010)体现的算法特点,每一个希腊字母的基础测试 又分为古希腊语测试和现代希腊语测试。基础测试按字 母顺序分别总结了每个希腊字母的算法点,包括大小 写、字母位置和变音符号等。基础测试部分按元音字母 分别编写了 11 组双元音相关测试,重点是有气号、双 元音的处理方法。按上述双元音的算法设计,由人工将 希腊语双元音分别排列组合后产生了大量的转写结果。 同时,程序员按上述算法编程后,运行程序便可清楚看 到单元测试的缺陷和漏洞。通过人工和程序相结合的方 式进行双重验证能够有效保证算法的合理性和准确性。
综合测试部分首先测试了 ALA-LC 希腊语罗马化表 (2010)的转写实例。如表 2 所示实例包含 28 例古希腊 文(含中古希腊文)实例和 40 例现代希腊文实例,这 些实例几乎包含了此表全部转写点。
3.2 测试结果分析
前期测试结果存在的问题是人工转写失误,包括相 似字母判断错误、遗漏转写字母等。对双元音算法揭示 不完整,穷举不全面。在此测试基础上,经过完善和改 进算法后,进行了升级的基础测试。由表 2 可知,基础 测试样本总数为 512 个希腊单词,古希腊文和现代希腊 文各有 256 个单词。其中古希腊文单词的人工转写正确 率是 98%,有 6 个错误 ;程序转写正确率是 99%,有 3 个错误。现代希腊文单词的人工转写正确率是 100% ; 程序转写正确率是 99%,有 3 个错误。希腊文人工转写 正确率是 99%,有 6 个错误 ;程序转写正确率是 99%, 有 6 个错误。
基础测试的转写结果表明,人工转写和程序转写的 正确率相同。总结基础测试错误样例,如表 3 所示,人 工转写错误类型均为失误。程序转写错误类型是算法规则不完善。此项目人工算法的更改在时间上优先于程序 算法,人工算法更新后转写结果得以及时调整。而由人 工算法设计者将算法变更转达程序员后,程序员需要一 段时间修改并测试程序,因此,人工完善算法比程序优 化算法提前。所以,表 3 的程序转写算法错误严格意义 上是算法更新时间滞后导致的结果。从准确性方面看, 程序转写准确率明显高于人工转写。此处程序转写标点 符号算法是指除有气号以外的其他变音符号都不参与转 写。希腊字母 iota 有一个算法点在基础测试期间被删 除了,但程序算法未及时更改。此处的标点符号算法是 同一种类型,字母算法也是同一种类型。以上错误都可通过算法完善而消除。
在顺利通过基础测试的基础上, 继续测试 ALA-LC 希腊语罗马化表(2010)的实例部分,以此作为第一阶 段综合测试。实例部分包括希腊单词、词组及短句,并 且融合了大小写、标点符号等 LC 转写的惯用规则,测 试难度增大。这部分测试的参照组是 LC 转写结果,测 试组是程序转写结果。需要说明的是在程序开发初期, 大小写规则与 LC 有所区别,这将导致部分与大小写相 关的转写结果不一致。
将第一阶段综合测试的转写错误按原因归类,如 表 4 所示。程序转写的错误类型分为 7 类。变音符号、 标点符号和大小写规则 3 类错误属于原有算法漏洞。原 有算法不够完善,需要根据具体错误补充遗漏的算法。 后 2 类错误表明需补充希腊数字的转写算法,并修改有 误的旧算法。与其他规则矛盾类型是指部分双元音的转 换结果与 LC 原有双元音规则不一致。该表未指明这是 否是特殊情况,有待观察。除此类错误外,其他 6 类错 误都可通过改进算法后消除。
4 结论及探讨
国内希腊文编目遵循国际主流的编目理论与实践经 验。国内希腊文编目需要遵循国际标准完成转写。希腊 文转写平台(项目网址 :https://github.com/tsing 26/ Greektrans)是专为国内图书馆开发的有利工具,是 以 ALA-LC 希腊语罗马化表(2010)开发的免费转写 工具,它的本质是通过程序实现基于英文开发的文字 转写体系,即用英文字母表示希腊文字的过程。根据 ALA-LC 希腊语罗马化表(2010)的特点,希腊文转写 平台算法重点挖掘了变音符号、双元音、字母位置、大 小写和标点符号的转写规律。双元音部分结合变音符号 的变化,试穷举了所有可能的组合结果。通过编写单元 测试验证程序算法的准确性和适用性。单元测试主要分 为基础测试和综合测试。单元测试结果表明,基础测试 部分程序转写的准确率明显高于人工转写。基础测试的 错误都可通过改进现有算法而更正。第一阶段综合测试 的结果表明,程序算法的准确性和适用性与参照对象基 本趋于一致。在变音符号的具体应用层面需要进一步观 察和总结规律,从而完善现有算法,使转写结果的适用 性更强。另有一类错误是与原有转写规律矛盾,这类问 题也需要继续积累,从而发现其中规律。而其他错误类 型都可通过完善现有算法得以解决。因此,现阶段的希 腊文转写平台能够较好地完成希腊文基础转写。对于算 法点较复杂的综合测试,还有较大提升空间,也需要在 今后的实际转写中不断积累和总结。
ALA-LC 希腊语罗马化表(2010)并未完全向用户 揭示隐含算法,因此,完善希腊文转写平台必然是一项 长远的工作。不仅需要研究员对希腊语有较深的造诣, 能够及时总结较为特殊的算法点,更需要持之以恒的务 实态度,不断在实例中深挖规律。同时也会认真听取广 大用户的使用意见,从而提升平台的转写质量。综合测 试的难度需要在不断完善中逐渐提高,当第一阶段的算
法经过完善后,开发团队会继续进行下一阶段的综合测 试。在平台功能开发层面,项目团队未来计划增加软键 盘功能区,为用户提供特殊字符的输入便利性,以此提 高希腊文输入的准确性。
参考文献
[1] IFLA.国际编目原则声明(ICP)[EB/OL].陈琦译.[2022-1201].https://www.ifla.org/files/assets/cataloguing/icp/ icp_2016-zh.pdf.
[2] Library of Congress.Romanization Landscape[EB/ OL].(2011-11-17)[202205].https://www.loc.gov/catdir/ cpso/romlandscape_Oct2011.html.
[3] Library of Congress.BIBFRAME Transliteration Utility Development[EB/OL].(2022-04-08)[2022-12-02].https:// www.highergov.com/contract-opportunity/bibframe- transliteration-utility-development-lgd20220123-s-06834/ #documents.
[4] Library of Congress.Marva[DB/OL].[2022-12-03]. https://bibframe.org/marva/editor/.
[5] BGN/PCGN.Romanization of Greek[EB/OL].[2022-12- 05].https://assets.publishing.service.gov.uk/government/ uploads/system/uploads/attachment_data/file/693694/ ROMANIZATION_OF GREEK.pdf.
[6] International Organization for Standardization. ISO/R 843:1968[S/OL].[2022-12-05].https://www.iso.org/ standard/5214.html.
[7] ALA/ALCTS/CCS/CC:DA Task Force for the Review of the Romanization of Greek.CC:DA/TF/ Review of the Romanization of Greek/3[EB/OL].(2010-05-18)[2022-12- 07].https://docslib.org/doc/1070990/task-force-for-the- review-of-the-romanization-of-greek-re-report-of-the- task-force.
[8] Library of Congress,American Library Association. ALA-LC Romanization Tables:Transliteration Schemes for Non-Roman Scripts[M].Washington:Library of Congress, 1997.
[9] Library of Congress,American Library Association. ALA-LC Romanization Tables:Greek(2010)[EB/OL].[2022- 12-08].https://www.loc.gov/catdir/cpso/romanization/ greek.pdf.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/57641.html