SCI论文(www.lunwensci.com)
摘 要:针对传统非机动车头盔检测算法目标漏检率高,在密集骑行场景下检测精度低等问题,提出了一种基于改进 YOLOv5s 的非机动车头盔佩戴检测算法。该算法采用 Kmeans++ 算法聚类生成锚框,增强网络的稳定性; 接着使用轻量级 通用上采样算子 (CARAFE) 对高阶特征图进行上采样操作,增大感受野,充分利用特征语义信息; 同时在 Backbone 模块和 Head 端前引入坐标注意力机制 (coordinate attention,CA),在保证轻量化的同时,进一步提高算法的检测精度; 最后利用 DIoU-NMS 对目标检测模型的输出后处理,降低密集场景下模型的漏检率,改善遮挡物体的检测能力。与 YOLOv5s 算法相 比,改进后的算法精确度、召回率、平均精度分别提升了 2.3%、1.5% 和 1.5%,能够实现对非机动车头盔佩戴的高精度检测。
Improved YOLOv5s Algorithm for Helmet Wearing Detection of Non-motorized
Vehi
ZHANG Zihan, YUAN Dong, ZHANG Jingwei, AI Changqing
(College of Mechanical and Electrical Engineering, Hohai University, Changzhou Jiangsu 213022)
【Abstract】:As to the problems of high target missed detection rate and low detection accuracy of traditional helmet detection algorithms of non-motorized vehicle in the scene with many targets, an improved algorithm based on YOLOv5s is proposed for detecting helmet-wearing of non-motorized vehicle. The algorithm uses Kmeans++ to cluster in order to generate anchor boxes to improve the stability of the network. Then, the lightweight universal upsampling operator (CARAFE) is used to upsample the higher-order feature map, so as to enlarge the receptive field and fully utilize the feature semantic information . Meanwhile, the coordinate attention (CA) attention mechanism is introduced in front of backbone module and head end to further improve the detection accuracy while ensuring lightweight.Finally, the output post-processing of the target detection model by DIoU-NMS is used to reduce the missed detection rate of the model in dense scenes and improve the detection ability of occluded objects. In contrast to the YOLOv5s algorithm, the accuracy, recall rate and mean accuracy of the improved algorithm have been improved by 2.3%, 1.5% and 1.5%, respectively. The proposed algorithm can realize the high precision detection of non-motorized vehicle helmet wearing.
【Key words】:helmet detection;YOLOv5s;Kmeans++;CARAFE;attention mechanism;DIoU-NMS
引言
随着国家推广绿色出行理念,电动自行车成为主要 的出行交通工具之一。由于部分电动自行车驾驶员缺乏 安全意识,不佩戴头盔,存在安全风险。据研究表明, 正确佩戴头盔能降低 42% 的死亡率和 69% 的受伤率 [1] , 为骑行人员提供安全保障。因此,国家颁布了相关政策及法律法规,并采用人工监管方式规范非机动车骑行人 员的行为。但此方法存在众多问题,不仅需要大量投入 执法人员,而且监管效率低、覆盖面不够广泛,难以满 足现阶段精准、规范执法需求。因此,利用以深度学习 为代表的人工智能算法对非机动车头盔佩戴进行检测具 有较大现实意义。
目前,主流的头盔佩戴检测算法分为两类:一类是 双阶段式检测算法; 另一类是单阶段式检测算法。双 阶段式目标检测算法主要以 R-CNN[2] 系列模型为代表。 储开斌 [3] 等使用主要样本注意力机制和可变形卷积模块 对 Faster R-CNN 算法进行改进,检测安全头盔,并采 用 Ablu 数据增强算法提升网络的泛化性,改进的算法 在小目标识别方面实现提升,但模型的复杂度较高,难 以实现安全头盔实时监测。
单阶段式目标检测算法以 SSD[4]、YOLO[5] 系列模 型为代表。王新 [6] 等使用轻量级网络 EfficientNetV2 替换 SSD 中的特征提取网络,并且改进特征金字塔结 构,简化网络模型,进一步改善 SSD 算法对头盔的检 测能力,但仍低于原始 YOLOv5 算法的准确率; 冉险 生 [7] 等引入改进的 Mobile Ne Xt 网络替换 YOLOv2 骨 干网络,使用 h-swish 激活函数,并在输出层前应用 正则化模块,提高小目标头盔的识别精度,但在密集骑 行场景下网络性能有待提升; 朱硕 [8] 等优化特征提取 模块,引入 CBAM 注意力机制,并将 YOLOv5 算法和 Sort 目标跟踪算法融合,模型依次完成电动车目标识 别、头盔佩戴识别及目标跟踪三个部分,使得算法识别 准确率高、目标性强,但算法流程长,难以满足目标检 测的实时性。
综上所述,在密集骑行场景下目标检测算法仍存在 精度与模型复杂度难以平衡、准确率低以及漏检率高等 问题。为了改善网络性能的稳定性,引入 Kmeans++ 算法聚类生成锚框;针对难以检测的头盔等小目标,使 用 CARAFE 对高阶特征图进行上采样操作,增大感受 野; 为了改善网络的目标检测精度,在模型结构中添 加 CA 注意力机制;针对密集场景的误检漏检问题,使 用 DIoU-NMS 损失函数对目标检测模型的输出进行后 处理。实验结果表明提出的网络模型在满足轻量化的同 时,提高目标检测精度,降低目标漏检率,可以满足头 盔检测的实际需求。
1 YOLOv5 算法原理
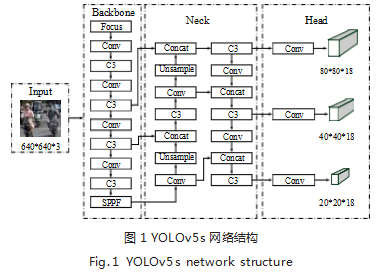
YOLOv5 目标检测模型官方给出了四种网络模型结 构, 包括 YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x[9]。 这四种模型结构主要区别在网络的深度与宽度不同。 YOlOv5 主要由输入层 (Input)、主干网 (Backbone)、 特征提取网 (Neck)、输出层 (Head) 组成。
Input 模块主要包括 Mosaic 数据增强、自适应锚 框计算及自适应图片缩放三个部分。
Backbone 模块由 Focus 结构、跨阶段局部网络 (cross stage partial,CSP) 以及快速空间金字塔池化层(spatial pyramid pooling - fast,SPPF) 组 成。 其 中, Focus 结构通过切片操作增加通道数, CSP 结构使网络 在轻量化的同时保持准确率, SPPF 模块实现了深层语 义信息与浅层语义信息的融合 [10],进一步提升网络性能。
Neck 模块由 FPN 和 PAN 两层组成, FPN 层负责 传递语义信息, PAN 层则负责传递定位信息,将不同 检测层的特征聚合,增强模型的特征提取。
Head 模块采用 GIoU_Loss 做 Bounding box 的损 失函数,输出检测对象的目标分数和边界框位置信息 [11]。
YOLOv5 是一个高性能、通用的目标检测模型 [12] , 其网络结构如图 1 所示,但在密集骑行等特殊场景下仍 存在检测精度低、漏检率高等问题,需要对模型的结构 以及后处理方法进行调整和改进。
2 算法改进策略
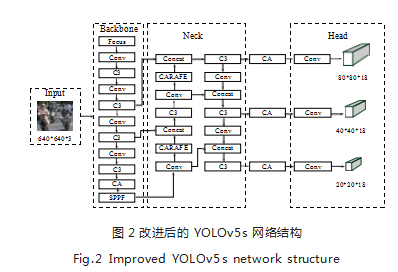
2.1 总体结构
所提出的改进后 YOLOv5s 总体结构如图 2 所示。 针对适合本文数据集的锚框,利用 Kmeans++ 算法对 数据集重聚类; 在 Backbone 模块中使用 CARAFE 算 法替代最近邻插值算法,提高网络提取语义信息的能 力;然后在 SPPF 模块以及 Head 端前添加 CA 注意力 机制,在模型轻量化的同时提高目标识别的精度;最后 在后处理中使用 DIoU-NMS 算法代替 NMS 算法,降 低模型的目标漏检率。
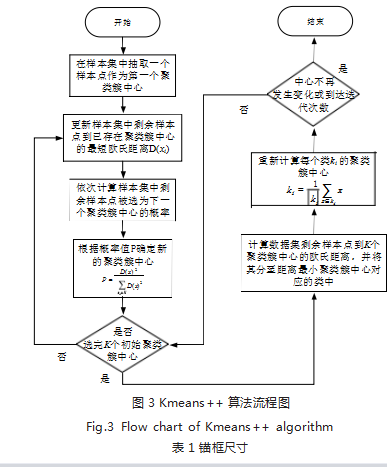
2.2 Kmeans++ 算法聚类锚框
YOLOv5 网络采用 Kmeans 算法聚类生成锚框, 并且采用遗传算法在网络训练过程中不断调整锚框。由 于算法在聚类前需要完成 K 个簇中心的初始化,因此其 存在收敛情况过度依赖簇中心初始化结果的问题,严重 影响网络性能的稳定性。Kmeans++ 是对 Kmeans 随 机初始化方法的优化 [13]。其流程如图 3 所示。
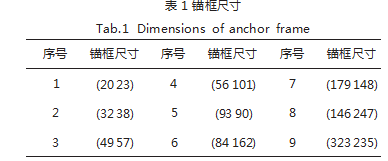
采用 Kmeans++ 算法对数据集重聚类, 数据如表 1所示。
2.3 轻量级通用上采样算子
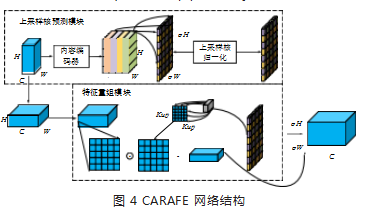
传统 YOLOv5 模型使用最近邻插值算法对高阶特征 图进行上采样操作,无法充分挖掘特征图的语义信息, 并且感受野较小。在 YOLOv5 模型中引入 CARAFE[14] , 可以实现在满足轻量化的同时,增大感受野,获得更多 的语义信息。CARAFE 主要由上采样预测模块和特征重组模块 [15] 组成,其结构如图 4 所示。
图中, C、H、 W 为特征图尺寸参数, σ 为倍率, kup 为重组内核尺寸。CARAFE 具体步骤如下:
Step1: 为了减少参数和计算量,通过 1×1 卷积将 原来的 C 个通道压缩到 Cm;
Step2: 利用内容编码器中一个卷积核大小为 Kencoder × Kencoder 的卷积层预测上采样核, 得到尺寸为 σH×σW×K2up 的上采样核,其中 Kencoder 为编码器参数;
Step3: 将 Step2 得到的上采样核归一化,且确保卷 积核权重和为 1;
Step4: 将输入特征图中 kup ×kup 的区域与预测出的 上采样核做点积操作,输出重组后的特征。
2.4 注意力机制
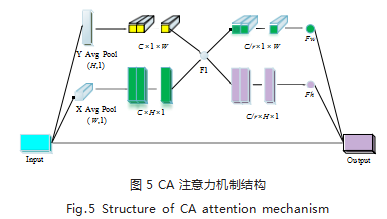
近来,SENet[16] 模块被广泛应用于轻量级网络的注 意力机制中,其仅考虑到通道间的关系,忽略空间位置 关系;CBAM[17] 模块则考虑到空间位置关系,注重提高 各个特征在通道和空间上的联系,但卷积只能提取局部 关系, 缺乏长距离关系提取的能力 [18]。协同注意力机 制网络 (coordinate attention,CA)[19] ,引入一种新的 注意力结构,该结构不仅考虑到空间和通道信息,还考 虑到长距离依赖问题,使得模型在轻量化的同时实现精 度的提升,其结构 [20] 如图 5 所示。
网络中的任意中间特征张量 X 可以表示为:

的特征图 Fh 和 Fw。此外, 使用 Sigmoid 激活函数, 获 取注意力权重 gh 和 gw:
2.5 后处理方法的改进
非极大值抑制 (NMS) 主要是用于基于深度学习的 目标检测模型输出的后处理,从而除去冗余的检测框, 获得正确的检测结果 [21]。YOLOv5 使用 NMS 算法对模 型输出的结果进行处理,此算法将 IoU 值作为唯一考 量,当 IoU 值大于设定的阈值时,模型将此候选框与置 信度最高的候选框视为同一个候选框,将其删除。在检 测目标数量多且存在重叠情况时, NMS 算法会存在严 重的漏检情况。
由于检测目标为非机动车头盔,存在检测目标数量 多且重叠情况。因此,选择 DIoU-NMS 算法进行模型 的后处理。
3 实验与分析
3.1 实验环境及数据集
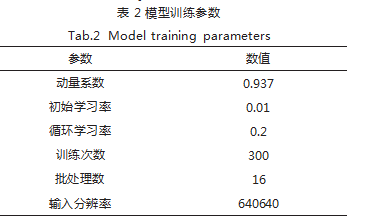
本文实验在 Windows 10 系统计算机上进行, CPU 型 号为 Intel(R) Xeon(R) Gold 6248R CPU @ CPU 3.00GHz,GPU 型号为 NVIDIA GeForce RTX 3090. 编译语言为 Python3.8.5. 深度学习框架为 Pytorch1.13.1. 模型 的训练参数如表 2 所示。
由于尚无公开可用的非机动车头盔数据集,通过网 络爬虫以及道路实拍视频截取制作了头盔图像数据集。 通过 LabelImg 软件完成对数据集的标注,重点对非 机动车以及是否佩戴头盔进行识别。数据集中的图片数 据包含白天、傍晚不同时间段以及远近视角,具有普适 性。其中训练集 500 张,测试集 100 张。部分数据集图 片如图 6 所示。
3.2 目标检测系统
所设计的非机动车头盔佩戴检测系统包括视频检测 模块和实时检测模块两个部分。检测系统使用所提出模 型训练得到的权重文件识别目标。部分系统界面如图 7 所示。
3.3 模型评价指标
使用精度 (Precision, P)、召回率 (Recall, R) 和平 均精度均值 (mean Average Precision, mAP)3 个指标 进行模型评价。精度是目标的预测是否准确的评价,计 算公式如式 9 所示:
3.4 实验评估与分析
3.4.1 不同 YOLOv5 模型对比实验
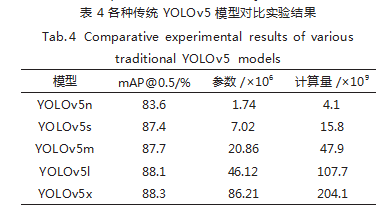
根据模型的复杂程度,被划分 YOLOv5n、YOLOv5s、 YOLOv5m、YOLOv5l、YOLOv5x 五种模型结构。实验 将模型检测精度、参数量和计算量作为评价指标,依次 训练五种模型,实验数据如表 4 所示。
从表中可以看出, 随着模型深度和宽度的增加,模 型的检测性能不断提升,同时参数量和计算量也不断增加。由于 YOLOv5n 模型的深度和宽度较小, mAP 值仅有 83.6%,相较于其它四种模型精度较低,不 易满足目标检测精度要求;YOLOv5s 模型的精度与 YOLOv5m 模 型 较 为 接 近,mAP 值 仅 低 0.3%, 但 YOLOv5m 模型的参数量和计算量近似于 YOLOv5s 模型的 3 倍;YOLOv5l 和 YOLOv5x 模型的精度相较 YOLOv5s 模型有明显的提升,但参数量和计算量过大, 难以满足实际性检测的要求。
根据评价指标的数据,综合考虑所研究非机动车头 盔目标检测要求及精度、模型复杂程度等多方面因素, 选择参数量和计算量较小且满足精度要求的 YOLOv5s 作为原始模型。
3.4.2 模型训练
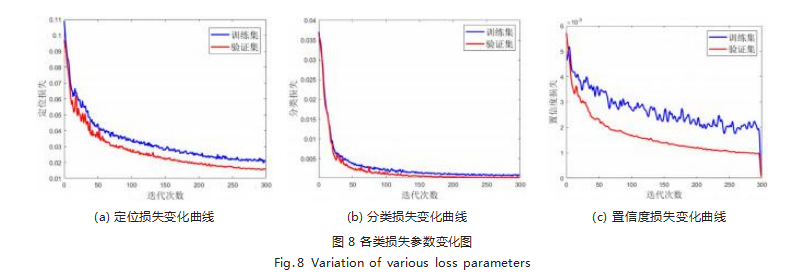
根据上述参数设置,在非机动车头盔数据集上对改 进的 YOLOv5s 模型进行训练,各损失训练结果如图 8 所示。
从图中可以看出, 定位损失、分类损失及置信度损 失曲线不断下降直至收敛,实验数据表明网络模型具有 较好的收敛能力和学习能力。
3.4.3 对比实验
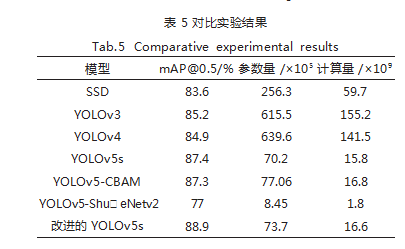
为了对改进的 YOLOv5s 算法进行更加充分的评估, 选取 SSD、YOLOv3、YOLOv4、YOLOv5-CBAM 以及 YOLOv5-ShuffleNetv2 等主流的目标检测算法作为对 照,各个模型均利用非机动车头盔数据集进行训练,并 对比各评价指标,实验结果如表 5 所示。
分析数据可得,改进的模型在综合性能上具有明显的 优势。相比 SSD 算法,不仅平均检测精度提升了 5.3%, 而且模型的参数量和计算量明显降低;相比 YOLOv3 和 YOLOv4 算法,不仅平均检测精度提升了 3.7% 和 4%, 而且模型的复杂程度降低;相比 YOLOv5-CBAM 算法, 改进算法在模型容量低的同时检测精度更高;YOLOv5- ShuffleNetv2 算法实现模型的轻量化,但检测精度仅 有 77%,难以满足精度要求。
综上所述,提出的改进算法在保证轻量化的同时, 具备较高的检测精度,进一步证明了改进算法相较于其 它算法的优越性。
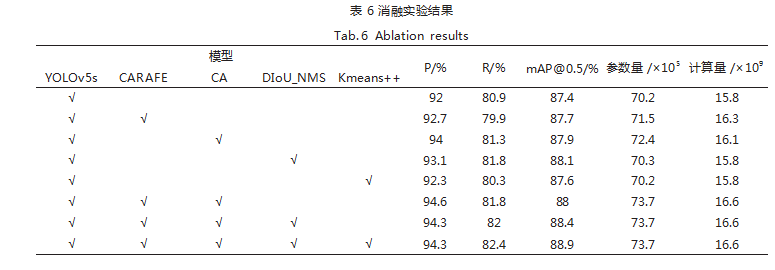
如表 6 所示, 当 YOLOv5s 模型加入 CARAFE 时, 在上采样操作中充分获取语义信息,召回率出现下降, 但精确率有所提升,并且 mAP 值提高了 0.3%; 加入 CA 注意力机制后,提升了网络目标检测能力,精确率、 召回率以及 mAP 值分别提升了 2%、0.4% 和 0.5%; 加入 DIoU_NMS 后,增强了模型对密集骑行场景的检 测能力,使得精确率、召回率和 mAP 值均得到一定程度提升;在使用 Kmeans++ 算法对数据集重新聚类后, 不仅使网络性能更稳定且得到的锚框尺寸更贴合实际 头盔检测,精确率和 mAP 值分别提升 0.3% 和 0.2%。
改进算法综合各个模块的优点,相比 YOLOv5s 网 络,在保证轻量化的同时,精确率、召回率和平均检测 精度分别提升 2.3%、1.5% 和 1.5%。所提出的 4 种优 化模块均取得较理想的提升效果,并且优化模块组合时 效果最佳。
如图 9 所示, 图中展示算法改进前后的精度对比情 况,可见所提出的改进算法对三种目标检测对象均具有较高平均检测精度,整体提升 1.5%。
3.4.4 模型检测效果可视化分析
为了更好地验证改进的 YOLOv5s 模型相较于原始 YOLOv5s 模型的提升效果,将两模型检测效果进行可 视化分析,模型效果对比如图 10 所示。
通过检测效果可以看出,改进模型减少了原始 YOLOv5s 模型对于中小目标的漏检,提升了目标检测 精度。
4 结论
提出了一种基于改进 YOLOv5s 的目标检测算法, 旨在提升原始算法在密集骑行场景下的精测能力,降低 目标漏检率。
首先,引入 Kmeans++ 算法聚类生成锚框,增强 网络性能的稳定性; 其次,使用 CARAFE 对高阶特征 图进行上采样操作,增大感受野,充分利用特征语义信 息;然后, 在 Backbone 模块和 Head 端前加入 CA 注 意力机制,提升网络对目标的定位能力,保证轻量化 的同时提升精度; 最后,在后处理方法上引入 DIoU- NMS,这一做法能降低模型的漏检率,改善遮挡物体的 检测能力。

根据实验数据可得,改进后的 YOLOv5s 算法在准确率、召回率、mAP 等性能指标相较于原始算法均有 一定提升,并且在目标密集场景下漏检情况有所改善。 在未来的研究工作中,将扩充数据集增加样本丰富性; 在保证精度的情况下,缩小模型体积,提升目标识别的 实时性。
参考文献
[1] LIU B C,IVERS R,NORTON R,et al . Helmets for Preventing Injury in Motorcycle Riders[J].Cochrane Database of Systematic Reviews,2008.1(2):CD004333.
[2] Girshick R,Donahue J,Darrell T,et al .Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[C]//IEEE Conference on Computer Vision and Pattern Recognition.2014: 580-587.
[3] 储开斌,叶托,张继.基于改进Faster R-CNN的头盔检测算法 研究[J].国外电子测量技术,2022.41(6):86-92.
[4] LIU W,ANGUELOV D,ERHAN D.SSD:Single Shot Multibox Detector[C].European Conference on Computer Vision.Springer,Cham,2016:21-37.
[5] REDMON J,DIVVALA S,GIRSHICK R,et al.You only look once:unified,real-time Object Detection[C]/// Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.2016:779-788.
[6] 王新,冯艺楠 .基于改进SSD的骑行人员佩戴头盔检测[J]. 电 子测量技术,2022.45(21):90-97.
[7] 冉险生,陈卓,张禾 .改进YOLOv2算法的道路摩托车头盔检 测[J]. 电子测量技术,2021.44(24):105-115.
[8] 朱硕,黄剑翔,汪宗洋,等.基于深度学习的非机动车头盔佩戴 检测方法研究[J]. 电子测量技术,2022.45(22):120-127.
[9] Mahendrakar T,White R T,Wilde M,et al .Real-Time Satellite Component Recognition with yolov5[C]//Small Satellite Conference.2021.
[10] 杨锦辉,李鸿,杜芸彦,等 .基于改进YOLOv5s的轻量化目标 检测算法[J/OL]. 电光与控制:1-11.
[11] 院老虎,常玉坤,刘家夫 .基于改进YOLOv5s的雾天场景车 辆检测方法[J/OL].郑州大学学报(工学版):1-7.
[12] 王素珍,赵霖,邵明伟,等 .基于改进YOLOv5的输电线路绝 缘子识别方法[J]. 电子测量技术,2022.45(21): 181-188.
[13] 王祎,黄瑞婷,路静怡 .Kmeans++模型在电视节目分类分 析中的应用[J].广播与电视技术,2022.49(11):11-16.
[14] WANG J,YANG W,GUO H,et al.Tiny Object Detection in Aerial Images[C]//2020 25th International Conference on Pattern Recognition(ICPR).IEEE,2021:3791-3798.
[15] 张欣怡,张飞,郝斌,等 .基于改进YOLOv5的口罩佩戴检测 算法[J].计算机工程:1-14.
[16] HU J,SHEN L,SUN G . Squeeze - and- excitation networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.San Juan:IEEE, 2018:7132-7141.
[17] Woo S,Park J,Lee J Y,et al.CBAM:Convolutional Block Attention Module[J].Springer,Cham,2018:3-19.
[18] 胡欣,周运强,肖剑,等 .基于改进YOLOv5的螺纹钢表面缺 陷检测[J/OL].图学学报:1-12.
[19] HOU Q,ZHOU D,FENG J.Coordinate Attention for Efficient Mobile Network Design[J].arXiv, 2021.
[20] 马阿辉,祝双武,李丑旦,等 .改进YOLOv5的织物疵点检测 算法[J/OL].计算机工程与应用: 1-10.
[21]黄磊,杨媛,杨成煜,等 .FS-YOLOv5:轻量化红外目标检测方 法[J].计算机工程与应用:1-13.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/57607.html