SCI论文(www.lunwensci.com)
摘 要:基于可视化需求的背景下, 提出了结合 Flask 框架技术和 Neo4j 图数据库的方法, 对社交网络的真实用户数据 集进行处理,以可视化图的形式提供社交网络关系与相关信息,构建数据可视化模型,主要包含 4 个模型,即: 基础信息模 型、节点模型、Circle 模型和路径搜索模型。通过试验验证表明,该可视化模型方法可以应用于相关数据的可视化。
关键词:社交网络,Flask 框架,Neo4j 图数据库,数据可视化
Research on Social Network Data Set Processing and Visualization Model
XUE Yibo
(Chongqing Jiaotong University, Chongqing 400074)
【Abstract】:Based on the background of visualization requirements, this paper proposes a method combining the Flask framework technology and Neo4j diagram database to process the real user data set of social networks, provide social network relationships and related information in the form of visualization diagrams, and build a data visualization model, which mainly includes four models, namely: Basic information model, node model, circle model, and path search model. The experimental results show that the visualization model method can be applied to the visualization of related data.
【Key words】:social networking;Flask framework;Neo4j diagram database;data visualization
0 引言
现代信息化在逐渐发展的过程中对数据分析提出新 的要求,信息化对数据可视化的需求日益增长。数据网 络是庞大的、连续的和不断发展的 [1] ,在社会学媒体大 众领域,其目的是通过可视化研究社会群体的共同特征 以及用户的社区聚集属性,帮助降低用户数据理解门 槛,有助于社交行为研究以及分析决策的制定。
根据感知心理学研究表明,视觉数据比文本信息更 容易理解。Finch & Flenner[2] 认为一张图片值一千个 单词,图片可以更有效地讲述故事并传达一组数据。视 觉数据表示比基于数字的表示更具说服力, Arleo A[3] 等介绍了 VAIM,是一种可视化分析系统,支持用户分 析、评估和比较由不同 IM 算法确定的信息传播过程。 Cui Di[4] 等针对高维数据选择若干个视图,在多个角度 下生成不同的可视化结果。如何通过感知层面的图形、 文字等可视化元素设计为数据可视化提供更好的服务, 是数据可视化急需解决的关键问题之一 [5]。
在国外,数据可视化无论从规模还是模式都有明显 的成熟化趋势,采用可视化方法对数据的传播有促进作 用,从而更好地表达自身观点。由于我国目前针对社交 网络的可视化方向研究相对较少,随着网络社交的发 展,社交网络规模会逐渐增大,社交网络相关研究问题 将会得到越来越多的重视。本文基于可视化需求的背景 下,对社交网络数据集进行数据处理,运用现阶段科学 技术,构建数据可视化模型,以帮助用户更好地理解社 交网络、找寻个体特征和探究潜在规律等。
1 需求分析
本文设计了一款以图网络的表现形式来展示社交网络 的数据可视化交互系统,通过以图论为基础的网络图来展 示真实的社交数据,使用户能够更便捷地了解社交方式、 社交规模等总体情况。使用 Python 开发语言、Neo4j 图 数据库、Flask 框架技术、图计算插件工具 Graph Data Science 等,对斯坦福大学研究自我学习社交网络分类 的 Google+ 数据集 [6] 进行处理并搭建可视化平台。
论文对于系统功能的分析与设计来自于用户的数据 可视化需求,其中包括:数据集简介、数据集基础数据、 节点社交网络可视化、节点信息展示与朋友圈可视化 等。因此,系统可视化模型的构建包括基础信息模型、 节点模型、Circle 模型和路径搜索模型 4 个部分,每一 个子模型之间是层层递进的关系,在构建完成上一个模 型的基础上,平台递进到下一个模型的构建和展示。
2 系统总体设计及数据集处理
系统以 Web 作为数据可视化开发方向, 采用 B/S 模式 [7] ,保证功能的完整性、交互的直观性和运行的流 畅性。以 Web、数据库、服务器为 3 个子系统端构成 系统总体,各子系统实现其功能的同时与其他子系统之 间相互协同,构成良好的网络数据运作体系。Pyhton 通过 Noe4j 包以及 Py2neo 包搭建与 Neo4j 数据库的 链接。Py2neo 是一个客户端库和综合工具包,用于从 Python 应用程序和命令行中使用 Neo4j。总体系统框 架如图 1 所示。
2.1 原始数据
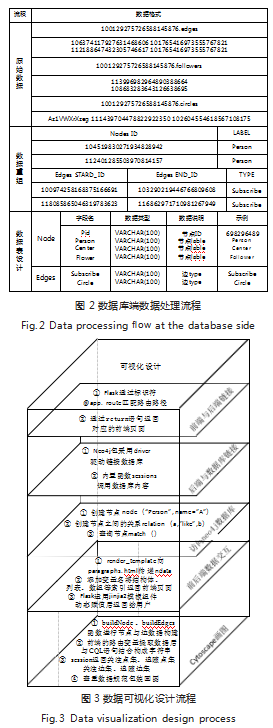
本文数据为 Google+ 的社交网络数据,数据集包 括节点特征(配置文件)、圆圈和自我网络,包含了用 户的属性、索引、基于不同用户个体的自我社交网络与 Google+ 独特的数据模式朋友圈(Circle),数据在官 方发布时已完成了脱敏作业。系统设计以数据集的可视 化为主要目的,数据库端的主要职能为:对计算结果以 及原有数据进行存取。由于 Neo4j 数据库平台包含一个 不断增长的开放式高性能图形算法库,在其对数据的存 取过程中,可通过图算法来减少冗杂信息出现,提高数 据处理效率,为服务器端处理数据减少压力。
数据库的原始数据包括单向关注 -Edges、单向追 随 -Followers 和朋友圈 Circles,关注数据和追随数据 分别表示双节点的单向关注和单向追随关系,节点关系 并不显示于文件中,而是表示在文件名称中,文件中所 有节点都为文件名称所示节点的关注者(追随者)。原始数据格式如图 2 所示的示例文件, Egdes 文件中包含 双节点之间的单向关注关系,以行作为分界,数据集第 一列为关注关系的起始节点,第二列为关注关系的结束 节点,节点之间形成单向关注,在 Edges 文件中不包 含文件名 ID 的个体,对于每个文件下的所有节点,都 被文件名 ID 所关注;Follower 文件中包含 ID 为文件 名所指个体的全部追随着,按行隔开;Circle 文件中包 含关于 ID 为文件名节点的全部朋友圈成员与社交圈编 号,中心节点存在于文件名中,数据有 n 行,每行代表 一个社交朋友圈,第一个数据为社交圈 ID,之后的每 一个个体都为该圈子中的成员。
2.2 数据重组
由于原始数据集数量级的缘故,对数据集的数据导 入前,需要将上述原始文件中的数据信息进行提取重 组,达到导入目的。Neo4j 数据库的数据结构分为节点 Node 和边 Edges。节点数据文件包含 ID 与 Lable,因 为文件中不包含文件名所示节点, 需将文件夹中所有文件 的文件名进行遍历存储;非中心节点的节点信息保存于中 心节点的边关系文件中,需将数据集中所有的文件进行遍 历,保存所有节点信息;对所有节点信息进行查重存入 Node.csv 中, 并添加 Lable 属性。ID 自增长,Lable 为 自定义,可以拓展属性在节点中。
以节点为名称的边文件中,节点与文件中的所有节 点都为 Subscribe 关系,需将文件中所有节点信息遍 历,过滤重复节点,与文件名节点 ID 拼接构成新的数据 格式。边关系位于节点关系创建之后,对节点唯一标识 有顺序要求,暨有向关系的初始节点与结束节点的顺序。 边需要初始节点 ID、结束节点 ID 和关系属性 Lable。 重组后的数据格式如图 2 所示。
Circle 文件内容与其他的 Edges 文件格式不同, Circle 的逻辑模型为圈,但是并不能展示出中心节点,而 Neo4j 关系数据库不支持无向关系,因此需将文件名 ID 与同行内的所有结点形成单向关系,并保存于 CSV 中。
本可视化模型共使用 107614 个节点数据和 13673453 条关系数据,本数量级的数据集使用 Python-import 导入 方式最为恰当,具体流程需将 CSV 文件导入数据库目录的 Import 文件夹下,打开数据库的命令终端 Terminal, 输 入指令并规范节点文件和边文件,补充指令忽略坏数 据、排除空白数据和筛选不存在的数据索引等。具体节 点和边的数据表设计如图 2 所示。
3 可视化系统实现
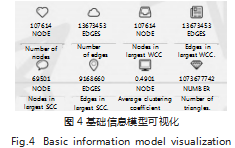
系统运用 Cytoscape.js 组件完成社交网络的可视 化,在系统前端对节点及其相关系网络完成可视设计, 设计流程包括: 前段与后端链接、后端与数据库链接、访问 Neo4j 数据库、前后端数据交互和 Cytoscape 画 图,如图 3 所示。
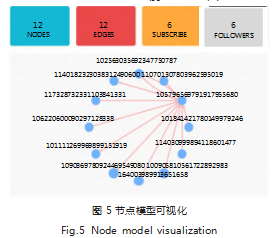
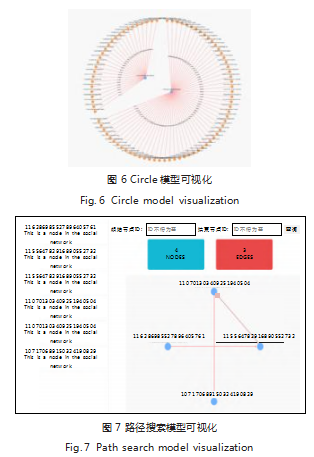
根据前文的分析,社交网络数据可视化模型的实 现, 包括:基础信息模型、节点模型、Circle 模型和路 径搜索模型。基础信息模型实现数据集基础属性的可视化,通过节点数与边数确定数据集的规模,通过平均聚 类系数可直观反映数据集中节点关系稠密程度等,其中 直径定义为网络中任意两个节点距离的最大值,该网络 为社交网络数据集,最大直径为 6.基础信息模型可视 化效果如图 4 所示。节点模型包括中心节点所关注的个体节点、追随中 心节点的个体节点、边关系的可视化等,可通过左栏查 看本网络中的节点个体信息如年龄分布、个体社交主要 关系类别等;每个节点都存在自己的属性信息,本文以 图表的方式对节点属性进行输出展示,并提供搜索栏供 用户搜寻节点信息。具体节点模型效果如图 5 所示。
本数据集由于项目需求特点,形成较为独特的朋友 圈概念数据,可以通过 Circle 模型可视化获知中心节 点朋友圈的规模和数量,对用户的隐私保护、社交分类 提供便捷,同时可对用户的社交分类提取共性特征来对 社会学、心理学等提供重要参考,具体 Circle 模型可 视化效果如图 6 所示。从图 6 中可以看出,该中心节点 在平台中划分了 2 个主要的朋友圈, 网络规模为 85 个 个体,一个节点的连接关系越多,就越有可能建立新的 联系,这导致了不均匀的集中度和中心。
路径搜索模型在左方栏目中对路径中的节点信息进 行展示,并在可视化路径上方显示该路径的具体边数以 及点数。该模型具体可视化效果如图 7 所示,通过路径可视化可以观测节点间关系,并发现具体路径和具体的 节点信息,通过当前搜索下的最短路径,可反映社交关 系和社交信息传播路径、传染病蔓延方式、计算机病毒 的扩散等。排除孤立节点以及在本数据集中不存在路径 的始终节点之外,所有的路径长度均小于等于 6.是对 六度分隔原理 [8] 的一种证明。
4 结论
论文以可视化图的形式提供社交网络关系与相关信 息,帮助降低用户数据理解门槛,实现对于相当稀疏 而又复杂数据集的深入洞察。以 B/S 模式设计并研发 Google+ 社交网络数据集数据可视化系统, 主要完成工 作如下。
4.1 数据处理
将原 Google+ 数据集中节点信息以及边信息进行 整理与筛选,突出本数据集中的特殊数据信息朋友圈的 划分,在数据录入数据库前进行初步处理。在数据库方 面,采用 Neo4j 图关系数据库对数据进行存储。由于数 据集的数量级问题,采用 Import 方式导入,需对 CSV 文件数据进行规范化处理。在社交网络信息录入后,采 用 Py2neo 包与 Python 语言对数据进行进一步的筛选处理,来完成系统浏览器端的数据显示功能。
4.2 系统框架搭建
可视化系统运用 Neo4j 数据库平台,以 Google+ 数 据集为数据基础,前端采用 HTML、CSS、JS 等技术 设计与搭建, 运用 Flask 轻型框架配合 Python 语言完 成对系统框架的搭建。数据展示方法采用 Cytoscape.js 画图组件实现社交网络可视化。
4.3 可视化模型设计与实现
对可视化模型的设计按照功能需求进行划分,在基础 信息模型,展示节点基础信息;在节点模型,展示中心节 点网络中的关注度、追随度、总边数、总节点数以及网络 相关节点等信息;Circle 模型突出数据集特点,可对节点 的朋友圈信息可视化以方便数据分析与分类;路径搜索模 型为用户提供指定节点数据的路径搜索, 为用户对社交网 络的特性进行分析提供帮助。在可视化方面, 采用静态 图表与动态画图结合的方式对数据结果进行可视化映射 展示,以满足用户多方面的数据分析需求,最终完成了 对 Google+ 社交网络数据集的可视化系统开发。
参考文献
[1]TABASSUM S,GAMA J,AZEVEDO P J,et al .SocialNetwork Analytics and Visualization:Dynamic Topic- based Influence Analysis in Evolving Micro-blogs[J].Expert Systems,e13195.
[2] FINCH J L,FLENNER A R.Using Data Visualization to Examine an Academic Library Collection[J].College & Research Libraries,2017.77(6):765.
[3]ARLEO A,DIDIMO W,LIOTTA G,et al .InfluenceMaximization With Visual Analytics[J].IEEE Transactionson Visualization and Computer Graphics,2022.28(10): 3428-3440.
[4] CUI D,GUO X Y,CHEN W.Challenges and Recent Progress in Big Data Visualization[J].Journal of Computer Applications,2017.37(7):2044.
[5] 陆菁,刘渊,张晓婷,等.基于用户体验的数据可视化模型研究 [J].包装工程,2016.37(2):52-56.
[6]LESKOVEC J,MCAULEY J.Learning to Discover SocialCircles in Ego Networks[J].Annual Conference on NeuralInformation Processing Systems,2012:539-547.
[7] 李佳俊,何玥,钱嵩橙,等. “互联网+”背景下基于B/S的云教 育系统设计[J].软件,2022.43(10):173-177.
[8] SHU W,CHUANG Y H.The Perceived Benefits of Six- degree-separation Social Networks[J].Internet Research, 2011.21(1):26-45.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/56040.html