SCI论文(www.lunwensci.com)
摘 要:本文利用 Python 网络爬虫技术对猎聘网上公司的招聘信息进行爬虫分析, 整合处理爬虫得到的数据。通过数据 可视化技术, 展现招聘城市分布状况, 分析研究各类招聘岗位与薪资、学历要求的关系, 直观地展示了互联网行业招聘现状, 为求职者提供相关就业信息。
关键词:Python,爬虫,招聘信息,可视化
Visualization Analysis of Recruitment Information Data Based on Python Crawler
TANG Feihong
(Shanghai University of Engineering Science, Shanghai 201620)
【Abstract】: The Python web crawler technology is used to make the crawler analysis to thecompany's online recruitment information with Liepin website. The data integration processing creeper, through data visualization technology, show for city distribution, analysis and research of various kinds of job and salary, and the relationship between academic requirements, so as to intuitively show the situation of Internet recruitment, and provide relevant employment information for fresh graduates.
【Key words】: Python;crawler;recruitment information;visualization
随着互联网的飞速发展,互联网上的数据量日趋增 大,人们通过网络获取信息的途径也越发便捷。招聘网 站的出现使得人们开始通过网络寻求招聘信息,相比线 下招聘, 网络招聘具有选择性广、局限性低的优点 [1]。 但是随着人们的求职需求越来越多、越来越杂,招聘网 站上的信息也变得越来越冗余,人们在招聘网站查找想 要的信息变得困难。随着科学技术的发展,可以通过大 数据统计分析的方法处理网页数据,利用网络爬虫技术 将网页上的数据实时爬取到本地,利用一些数据处理方 法,将冗杂的信息变得精简。
本文使用 Python 和谷歌浏览器,通过模拟人们点 击网页的操作,自动地从猎聘网上爬取招聘信息。首先 在猎聘网上爬取某公司的招聘信息并存入 CSV 文件中; 其次,整合得到的数据;最后,通过数据可视化技术直 观展示招聘现状。
1 网络爬虫
网络爬虫是一个从网页上自动抓取数据的程序。网 络爬虫通过程序模拟浏览器上网 [2] ,从一个或若干个URL 开始,抓取初始 URL 网页上的信息,在抓取网 页数据的过程中,不断地从当前页面得到新的 URL 放 入队列,不停地抓取 URL 队列中的网页数据,直到满 足一定的终止条件。爬虫的基本过程可以概括为以下 4 步: 程序通过向目标网站发动 Request 请求,等待服 务器响应;服务器响应,得到 Response,其中包含爬 取的页面内容; 解析数据,页面内容可能有多种形式, 可使用正则表达式、解析库等方法进行解析; 保存数 据,将数据保存到文件或数据库中 [3]。
2 招聘数据爬取
2.1 爬取对象
本文研究对象是招聘网站上的招聘信息,以猎聘网 上某公司(简称 A 公司)的招聘信息为例,分析互联网 公司招聘现状。爬虫采用的编程语言版本是 Python3.7.
2.2 爬取流程
2.2.1 导入第三方模块
首先导入模拟浏览器发送请求的 Requests 模块,然 后导入解析数据时使用的 Parsel 模块,最后导入 CSV库,数据解析完成后可以将数据写入 CSV 文件中。
2.2.2 分析 URL
在猎聘网上进入 A 公司的主页后,点击“热招职位” 页签后显示了招聘信息,观察 URL 发现,招聘页面的 URL 规律为 https://www.liepin.com/company-jobs/ 954482/+' 页码 ',所以通过改变不同的页码,可以提取 到猎聘网上 A 公司的所有招聘信息。其关键代码如下:
for i in range(1. 101):
url = 'https://www.liepin .com/company-jobs/ 954482/pn'+ str(i)+'/'
response= requests .get(url=url, headers= headers)
2.2.3 解析数据
首先利用 Parsel 模块将获取到的 response.text 数 据转换成 Selector 对象,再用 CSS 选择器,根据标签 的类属性提取页面中想要的内容。例如,想要获取招 聘薪资数据,分析页面发现,薪资数据在标签 内, 通过 li.css('.job-salary:: text').get() 函数就可以提取到招聘薪资数据。利用标签 信息,可以很方便地提取到招聘职位、城市、薪资、学 历要求、职位要求等数据。关键代码如下:
position = li .css(' .job-title-box div:nth-child (1)::text').get()
city = li.css('.job-dq-box .ellipsis-1::text').get() salary = li.css('.job-salary::text').get()
req _ list = li .css(' .job -labels - box . labels - tag::text').getall()
edu = req_list[0]
req = ','.join(req_list[1:])
2.3 数据保存
由 CSS 选择器解析得到数据,将每个招聘信息的 数据进行字典形式的封装, 再用 csv.writer.writerow() 将封装好的数据写入到 CSV 文件中。CSV 文件更容易 进行数据交换, 还可以通过 Excel 查看,方便对数据进 行操作。关键代码如下:
dit = {' 职位 ': position, ' 城市 ': city, ' 薪资 ': salary, ' 学历要求 ': edu, ' 职位要求 ': req }
csv writer.writerow(dit)
3 数据分析及可视化
3.1 数据预处理
对 CSV 文件中的数据进行预处理,删除异常值, 对数据进行整合,方便进行数据可视化及分析。主要操 作如下:
(1)删除异常值。本文选择 A 公司是为了分析互 联网行业招聘现状,故删除销售、管理等岗位的招聘信 息;删除薪资按小时计算的招聘信息;删除学历要求异 常的招聘信息。
(2)合并城市。例如, “北京 - 海淀区”“北京 - 丰 台区”都合并到“北京”。
(3) 对薪资进行分类,原数据中薪资标准太多。招 聘网站上的薪资范围大多过高,上限薪资绝大多数为综 合薪资,并非基础薪资,下限薪资基本为基础薪资,故 选用,例如,原数据中薪资显示为“10-15K”,处理后 薪资变成“10K”。
(4)合并学历要求。删除“学历不限”的招聘信 息,将学历要求合并为“本科”“硕士博士”“中专大专”3 大类。
通过上述预处理操作后,共得到 2220 条招聘数据。
3.2 数据可视化
3.2.1 招聘信息城市分布
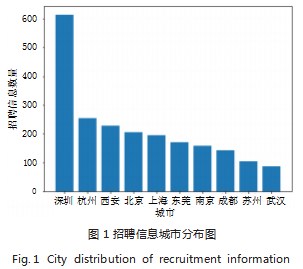
随着互联网技术的更新,全国各地互联网行业的发 展不尽相同,各地的招聘信息数量也会有所不同,往往 会产生聚集效应,在一线城市互联网行业蓬勃发展,互 联网行业的地域化差距也越来越显著。通过统计每个城 市 A 公司的招聘信息数量,绘制出招聘数量最多的 10 个城市。如图 1 所示,招聘信息最多的城市是深圳,其 次是杭州、西安、北京、上海,招聘信息集中在“一 线”城市,主要是省会城市和直辖市; 图 1 中也反映了 互联网行业的南北差异,招聘数量前十的城市中有 8 个 南方城市,北方城市只有北京、西安。
3.2.2 招聘薪资分析
求职者寻找工作时,招聘信息上显示的薪资至关重 要,求职者需要找寻达到自身心理预期的招聘信息。由于各城市经济发展水平的差异,不同城市的薪资基础水 平不同,通过统计每个城市招聘信息中给出的薪资,计 算各城市平均薪资,如图 2 所示。
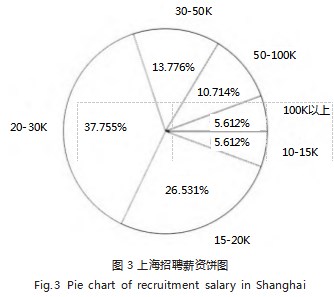
北京、上海招聘信息中的薪资水平较高,平均值在 30K 以上,其次是深圳。这是因为北京、上海经济发展状 况较好,互联网行业发展迅速,居民消费水平高,平均薪 资也高。平均薪资也只能反映城市的整体水平,为了分 析薪资分布的具体情况,选择上海、深圳、西安 3 个城 市,统计其招聘信息中薪资分布。为了方便统计,将数 据中的基础月薪分为以下 7 类:“10K 以下”“10-15K”“15- 20K”“20-30K”“30-50K”“50-100K”“100K 以上”。上海、 深圳、西安薪资分布结果如图 3、图 4、图 5 所示, “15- 20K”和“20-30K”都是 3 个城市中比重最高的两个, 加起来占 60% 左右,说明互联网行业大部分从业人员 的工资在月薪 2 万左右;3 万以上月薪的高薪岗位数量较少, 10 万月薪的岗位在深圳、西安仅占 2% 左右,在 上海这个国际化的大都市才占 5%。
对比 3 个城市的图像发现,西安“10-15K”占比较 大, 占 25.439%, 而上海和深圳“10-15K”仅仅只有 5.621% 和 7.993%, 而“50-100K”的占比却相反, 上 海、深圳均占 10% 左右,西安只有不到 2%,这说明上 海、深圳的薪资普遍高于西安。
上海、深圳、西安的薪资饼图中都不包含“10K 以 下”分类,说明统计的数据里不包含薪资在 10K 以下 的招聘信息,查找从网络上爬取的原始数据发现,猎聘 网上 A 公司的招聘信息中有月薪 10K 以下的条目,不 过这些招聘岗位大多为管理、销售、硬件测试相关工 作,在数据预处理阶段删除了。预处理后的数据集中只 有武汉、东莞等城市包含少量薪资在 10K 以下的招聘 信息,说明互联网行业的基础薪资较高,大多都在月薪10K 以上。
3.2.3 解析数据
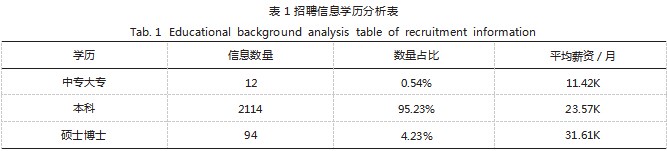
现如今大学生陷入考研热潮,越来越多的应届毕业 生选择继续攻读研究生学位。统计分析招聘信息中学历 要求与薪资的关系,如表 1 所示。
学历越高平均薪资越多,从“中专大专”到“本 科”再到“硕士博士”,平均月薪均提高 10K 左右,说 明提高学历确实可以有助于找到更好的工作。中专大专 的数据量极少,说明中专大专学历不足以满足互联网行 业岗位的基本需求,本科学历依然是招聘需求中占比最 大的。
3.2.4 职位要求分析
招聘网站提供招聘信息往往是提供该职位的要求, 一般也需要求职者掌握相关技能。通过对数据集中职位 需求进行词频分析,制作词云图,如图 6 所示。
“Java”“C 语言”“Python”3 个编程语言是职位 要求中出现较多的词目,说明掌握一门编程语言是互联 网行业从业者必备的基本技能。在众多开发相关的职位 中,后端开发的需求远远大于前端开发、框架开发,云 计算领域的职位需求量也较大。
4 结论
本文基于 Python 编程语言,爬取了猎聘网上 A 公 司的招聘信息,并完成了对数据的分析,通过数据可视 化的方式展示了招聘信息城市分布、招聘薪资分布、学历要求和职业技能要求,全面分析了互联网行业招聘现 状,为求职者提供了参考。
参考文献
[1] 甯文龙,毛红霞 .基于Python爬虫技术的51job网站内容爬 取[J].信息与电脑(理论版),2021.33(4):180-182.
[2] 于学斗,柏晓钰 .基于Python的城市天气数据爬虫程序分析 [J].办公自动化,2022.27(7):10-13+9.
[3] 蔡文乐,周晴晴,刘玉婷,等 .基于Python爬虫的豆瓣电影影 评数据可视化分析[J].现代信息科技,2021.5(18):86-89+93.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/54432.html