SCI论文(www.lunwensci.com):
摘要:Python语言具有成本低、难度低、开放化程度好以及简洁化等优势,在当下有着十分广泛的应用。依托于Python语言进行网络爬虫系统设计时,需要遵守可行性原则、避险性原则以及合理性原则,同时依照网络爬取流程设计系统调度、URL链接管理、网页下载与解析等功能模块,执行相关函数便能够实现目标网页信息的爬取。
关键词:Python语言;网络爬虫系统;开发
Research on the Development of Web Crawler System from the Perspective of Python Language
SUN ZiLi
(Hubei Land Resources Vocational College,Wuhan Hubei 430090)
【Abstract】:Python language has the advantages of low cost,low difficulty,good openness and simplicity.It is widely used at present.When designing a web crawler system based on Python language,we need to abide by the principles of feasibility,risk avoidance and rationality.At the same time,we need to design functional modules such as system scheduling,URL link management,web page download and analysis according to the network crawling process,and implement relevant functions to achieve the crawling of target web page information.
【Key words】:Python language;web crawler system;development
0引言
网络爬虫是一种可以自动抓取网页中各种数据的程序。网络爬虫只需要借助于相关网页链接地址,就可以查找相应的网页内容,同时能够直接反馈给用户需要的数据信息,不再需要人工操作浏览器来获取相关内容。爬虫在搜索引擎中占据了极其重要的地位,为搜索引擎抓取网络中的各项数据信息提供有力支持。像百度、谷歌等使用频率较高的通用搜索引擎,尽管人们习惯于使用该搜索引擎进行网络内容搜索,然而因为其通用性限制,抓取网络过程中缺乏良好的针对性,从而不能够依照抓取结果开展特殊领域的深层次分析工作,最终造成查询结果较为浅显、专业性不强;此外,在使用通用搜索引擎时,经常出现反馈结果与用户想要查找的信息关联性不强的现象,导致信息过载[1-2]。在这样的大环境下,开发出一种适宜的网络爬虫系统十分有必要,本文基于Python语言视域出发,充分发挥该语言成本低、难度低、开放化程度好以及简洁化等优势,探索了Python语言视域下网络爬虫系统设计要求以及爬虫系统工作过程中,为进一步提高网络爬虫系统工作效率与效果提供帮助。
1 Python语言概述
Python语言拥有较为强大的功能,是现阶段一种应用较为广泛的开发网址工具。近几年伴随着我国互联网产业的迅速发展,许多行业领域都急需要构建一个彰显自身特色的网址,在这样的迫切需求背景下,Python语言得到了较大范围的应用,促进了自身的快速发展。Python语言可以和当下许多种类型的操作系统相兼容。从网址开发的视域来探讨,Python是一种面向对象的编程语言,该编程语言只需要花费较少的时间就可以完成对象编程,此外Python语言也是一种解释性编程语言,依托于较为简单的语法结构以及动态输入特性,让Python语言慢慢发展成为了不同操作系统平台上应用越来越广泛的脚本语言,尤其是一些希望获得优异性能的综合应用程序开发,Python语言发挥了极其重要的作用[3]。另外,在特定情况下Python语言还能够供给互联网综合信息协议数据库,从而可以在较为有限的时间内完成对不同网络协议的抽象封装[4]。所以,程序开发人员应当要依托于科学合理的程序逻辑开展管理工作,不仅能够进一步健全Python语言模式,同时也可以在有限时间内强化整个网址的开发效率。
2 Python语言视域下网络爬虫系统设计思路
2.1 Python语言视域下网络爬虫系统的主要设计原则
为了确保基于Python语言的网络爬虫系统能够有效产出,同时使得设计完成的网络爬虫系统在具体运用过程中拥有良好的稳定性与合法性,程序开发人员在开展设计工作时应当要严格遵守以下几项设计原则。
(1)可行性原则。随着现代互联网的大范围普及与运用,网络上的数据信息规模越来越庞大,在海量互联网数据信息面前,假使程序开发人员使用全网爬虫的系统设计模式,不仅会导致信息爬取速度较慢,浪费掉大量的时间,同时也会增加爬取成本。为此,程序开发在实际开展相关设计工作之前,应当要充分领悟与把握网络爬虫系统的核心应用目标以及关键爬行对象,从而进一步明确网络爬虫系统的爬取主体以及动作范畴等,使得设计的网络爬虫系统能够满足实际应用需求,具有良好的切实可行性[5]。此外,还应当要进一步完善URL链接过滤体系以及相关评价体系等,不断提高网络爬虫系统开发和实现的针对性。
(2)避险性原则。现阶段为了提高网络信息的安全性,一些网站在设计过程中就融入了“反爬取”体系,当网络爬虫系统遇见这种类型的网站时,往往会导致自身程序运行不正常,既不能够获得需要的相关数据信息,并且会对网络爬虫系统自身的爬取有效性造成不良影响。比如说,为了确保自身网站数据信息的安全性,部分网页在创建过程中便引入动态技术创设“爬虫陷阱”。网络爬虫系统在进入到该类型网页进行信息爬取时,网页中的URL链接地址日历会不断变化新地址,从而造成网络爬虫系统持续不断的进入到相同地址,对该网页进行重复抓取并陷入到恶性循环之中。为此,在依托于Python语言进行网络爬虫系统开发过程中,程序开发人员应当要严格落实避险性原则,事先做好反爬取系统的应对方案,做好相应的预防工作。比如说,程序开发人员能够设置网络爬虫系统在相同网页的最高爬取次数,当达到设定的爬取次数之后,便会自主结束对该网页信息的爬取,从而跳离爬虫陷阱,并继续开展URL队伍中下一个链接的信息爬取。
(3)合理性原则。网络爬虫系统在实际运用过程中,往往会牵涉到“robots”安全协议,这种协议会对网络爬行产生较大的限制。网络爬虫系统在进行网页信息爬取时,第一步会访问robots.txt文本,了解到这个网站明令禁止采集的信息内容。紧接着网络爬虫系统依托于该协议内容,逐步开展规范化、限制性的信息爬取行为。当网络爬虫系统在某个网页没有范围到robots.txt文本,说明该网站对网络爬虫行为没有明确的约束,可以依照自身意愿爬取任意网页信息。事实上可以将robots看作是网页与爬行系统的协议,不是一种强制性的规定。为此,程序开发人员在进行网络爬虫系统开发时,应当要将robots.txt文本访问和限制体系考虑到其中,确保网络爬虫系统使用过程的合理性与规范性[6]。
2.2 Python语言视域下网络爬虫系统的模块结构设计
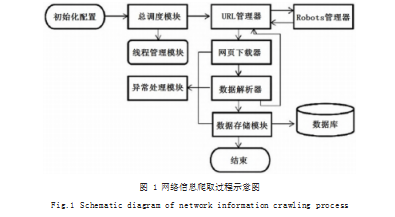
在实际开展网络爬虫系统开发与设计过程中,程序开发人员可以依照如图1所示的网络信息爬取过程,开展网络爬虫系统整体架构的开发与设计。通常情况下,网络爬虫系统的模块结构涵盖了系统调度、URL链接管理、网页下载与解析、数据存储、Root与线程管理、风险预防与处理等。
(1)系统调度模块。该模块可以看作是网络爬虫系统的“中央处理器”,其工作职责是控制其他功能模块,并向其发送各项管理指令。网络爬虫系统在实际运行时,系统调度模块必须要和其他模块创设稳定的反馈连接关系,当某一个模块的任务完成以后,系统调度模块可以及时向下一个模块下达任务指令,从而促使网络爬虫系统各项流程的有序开展,当达到了预设程序的全部要求之后,则结束此次爬行任务[7]。
(2)URL链接模块。该模块的主要职责是整理好网络爬虫系统中所有的URL链接,比如说待爬取或者已爬取URL链接等。
(3)网页下载模块。该模式是网络爬虫系统从网页得到相关信息的重要方式。在网络爬虫系统访问目标网页时,会自主开启网页下载功能,将网页中各种类型的数据下载爬取下来,比如说XTML、JSON数据等。
(4)网页解析模块。网络下载模块在获取到大量数据信息之后,就需要利用网络解析模块对其进行处理,对庞大数据进行去噪处理,进而将其中的冗余性文件排除出去,留下有应用价值的数据信息。
(5)数据存储模块。网络爬虫系统在获取并完成海量数据的处理工作之后,便会将数据传输到存储模块,储存模块依照数据类型的不同将其保持到各自位置。当判断数据拥有结构化特征时,那么就将其储存到数据库中;当判断数据拥有非结构化特征时,那么就将其存储到计算机硬盘中。之后依托于简单的检索体制,就能够快速便捷的查找已爬取数据。
(6)Root管理模块。该模块的主要职能是获取待爬取网页的robots.txt文本内容,同时准确探知到该网页允许与禁止访问的目录,从而确保网络爬虫系统使用过程的合理性与规范性。
(7)线程管理模块。该模块通常出现在多线程网络爬虫系统中,程序开发人员在开展设计工作时,应当要尽可能的提高系统线程的灵活性,确保使用者能够依照实际URL链接数量科学分配线程,从而提高网络爬虫系统工作效率。
(8)风险处理模块。该模块主要功能是防止网络爬虫系统进入到爬虫陷阱中而设计的。在实际进行网络爬虫系统开发与设计过程中,程序开发人员应当要提前规划好多种风险防范与应急方法,同时将其充分融入到Python语言的代码结构当中。
3 Python语言视域下网络爬虫系统的实现
依托于实现任意新闻网站的爬虫,同时将网页存储到计算机硬盘,从而达到简单的网络爬虫实现。怎样进行网页的URL地址爬取,具体实现方法如下:
(1)构建Tieba Spider类,同时要求类中涵盖main、_init_(self,tieba_name)以及run(self)等多个不同类型的函数。
(2)对_init_(self,tieba_name)函数进行定义,依托于地址列表self.url_list[]、新闻网站名称变量self.tieba_name等,通过循环语句得到全部的URL地址,同时将其添加到待爬取列表当中。
(3)对parse_url(self,url)函数进行定义,依托于程序response=requests.get(urs,headers=self.headers)来下达相关请求,同时得到响应。假使请求成功,那么回到responses值,假使请求失败,查看有无到达最后一页,当是最后一页,则退回到“error”,当不是最后一页,则退回到“None”。
(4)对save_html(self,html,page_num)函数进行定义,实现相关网页地址的存储。
(5)对run(self)函数进行定义,实现全部设计的逻辑思路整理。
(6)运行main函数,并将需要抓取的网页输入到其中,从而实现对相关网页内容的抓取。
4结语
综上所述,网络爬虫技术拥有强大的功能,可以在极短时间内获取到各种需要的信息数据,从而获取更多有价值的信息。同时Python语言功能也同样优秀,可以为各种形式的软件工具提供良好支持。最后,Python技术在特定情况下还可以有效提取不同Web信息。
参考文献
[1]姜杉彪,黄凯林,卢昱江,等.基于Python的专业网络爬虫的设计与实现[J].企业科技与发展,2016(8):17-19.
[2]杨国志,江业峰.基于Python的聚焦网络爬虫数据采集系统设计与实现[J].科学技术创新,2018(27):73-74.
[3]钟机灵.基于Python网络爬虫技术的数据采集系统研究[J].信息通信,2020(4):96-98.
[4]郭锋锋.基于Python的网络爬虫研究[J].佳木斯大学学报(自然科学版),2020,38(2):62-65.
[5]苏国新,苏聿.基于Python的可配置网络爬虫[J].宁德师范学院学报(自然科学版),2018,30(4):364-368.
[6]王金峰,李世良,王明,等.基于Python的关于Flickr图片网站的爬虫[J].中小企业管理与科技(中旬刊),2019(1):182-183.
[7]陈猛.基于Python的新浪新闻爬虫系统的设计与实现[J].现代信息科技,2018,2(7):111-112.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/37828.html