SCI论文(www.lunwensci.com)
摘 要:为兼顾车道线检测的准确性与实时性,本文提出一种基于改进的 DeeplabV3+ 模型的车道线检测方法。首先通 过水平翻转、改变图像的亮度、饱和度等方法对车道线图像进行数据增广,加强模型对于眩光、车道线破损情况下长直型、大 曲率车道线的泛化能力。其次将模型的主干网络更换为轻量级的 MobilenetV2 网络,提高模型训练速度,并依据车道线图像 特点改进 ASPP 结构, 合理设计组合多采样率空洞卷积, 提高模型对边缘车道线及远处车道线的预测效果,利用深度可分离卷 积,减少模型参数量。最后本文依据车道线图像特点提出了双注意力机制 DAMM 结构,通过合理分配注意力资源,提高模型 分割能力。实验表明,改进的 DeeplabV3+ 模型像素精度为 99.35%,平均交并比为 86.08%,单图预测时间为 22.62ms,说 明改进 DeeplabV3+ 模型兼顾准确性和实时性。
关键词:车道线检测,DeeplabV3+,ASPP,注意力机制,数据增广
Lane Line Detection Method Based on Improved DeeplabV3+ Model
LI Jingang, MA Chenxu, HAN Yonghua, DING Yifan, SUN Ziang, CUI Yuxin, YU Jianchu
(School of Information Science and Engineering, Zhejiang Sci-Tech University, Hangzhou Zhejiang 310018)
【Abstract】: In order to balance the recognition accuracy and real-time performance of lane detection, this paper proposes a lane detection method based on the improved DeeplabV3+ model. Firstly, the lane line images are expanded by horizontal flip and the brightness and saturation of the images are changed to enhance the generalization ability of the model for both long straight and large curvature lane lines under glare and lane line breakage. Secondly, the backbone network of the model is replaced with a lightweight MobilenetV2 network to improve the training speed of the model, and the ASPP structure is improved according to the characteristics of the lane line images, and the multi-sampling rate null convolution is reasonably designed to improve the prediction effect of the model on the edge lane lines and the distant lane lines. Finally, the dual-attention mechanism DAMM is fused according to the characteristics of lane line images, and the attention resources are reasonably allocated to improve the model segmentation capability. Experiments show that the accuracy of the improved DeeplabV3+ model is 99.35%, the mIoU is 86.08%, and the single-image prediction time is 22.62ms, which indicates that the improved DeeplabV3+ model takes into account both accuracy and real-time performance.
【Key words】: lane detection;DeeplabV3+;ASPP;attentional mechanisms;data augmentation
0 引言
2015 年以来, 我国陆续印发了《中国制造 2025》、 《中国智能网联汽车技术发展路线图》等文件以鼓励自 动驾驶行业有序发展。车道线检测作为自动驾驶中环境感知技术的核心部分,对无人驾驶安全、高效地参与交 通起到至关重要的作用。
在深度学习被大规模运用之前,人们主要通过提取 直观特征为主的传统方法让计算机理解“车道线”的存在。传统方法主要包括基于特征的方法和基于模型的方 法。基于特征的算法通过提取车道线的纹理、颜色和 形状等高阶特征,从而对图中的像素点进行分类 [1] ;基 于模型的算法通过特征提取,匹配预先设定好的数学模 型,然后确定模型的参数,从而拟合车道线 [2]。传统方 法面临诸多难题 :(1)因光照、天气易改变同一场景成像 后的像素值, 使得基于像素值操作的这些传统方法性能易 受光照、天气干扰 [3]。(2)在基于模型的方法中, 选取不 合适的模型会导致求解模型的速度缓慢,且可能由于车 道线形状与假设的模型不相符而导致检测效果较差 [4]。
基于深度学习的车道线检测方法,通过设计并训练 神经网络,可以使网络自主学习到更为准确的车道线特 征,较传统方法更鲁棒、更优越。目前大多数主流的图 像分割模型均是基于 Long 等提出的全卷积神经网络模 型,该模型采用编解码结构,可以接收任意尺寸的输 入图像 [5]。首先使用卷积操作提取目标物体的特征,然 后使用转置卷积对最后一个卷积层输出的特征图进行上 采样,使其逐步恢复至原图大小,最后采用跳层连接结 构,实现了较高精度的语义分割。随后,基于编解码结 构,Segnet 模 型 [6]、PSPnet 模 型 [7] 和 DeeplabV3+ 模 型 [8] 应运而生。后人陆续对这些网络模型进行改进,应 用于车道线检测中。Salma Moujtahid 等提出 Spatial- UNet 模型,在 U-Net 模型的基础上结合车道线的位置 先验信息,有效检测了由鱼眼相机拍摄的车道线图像 [9]。 Zequn Qin 等基于 Resnet-18 模型, 提出了一种推理速 度高达 300+FPS 的车道线检测算法,且分割性能接近 SOTA 水平 [10]。Fan 等提出了基于改进的 U-SegNet 模 型的多通道检测方法,设计了多对多的算法结构,有效 地解决了单帧算法下阴影遮挡和褪色的问题 [11]。Wang 等基于 CNN 模型,设计出用于车道线检测的 LaneNet 模型,并将车道线检测任务分为两类,分别使用了车道 边缘检测网络进行像素级车道边缘分类,以及车道线定 位网络根据车道边缘建议检测车道线,在实际交通场景 发挥了出色的性能 [12]。
上述模型取得了较好的检测效果,但准确性与实时 性的兼顾性弱,欠缺对复杂车道线检测的全面考量。本 文提出一种基于改进的 DeeplabV3+ 模型,该模型以轻 量级的 MobilenetV2 作为主干网络,均衡准确性与实 时性的前提下,充分考虑车道线的实际特征并提取。本 文选用百度无人车大赛数据集作为研究对象,在训练之 前,通过水平翻转增广车道线数据集中的大曲率车道线 图像,在训练过程中随机改变扩充后数据集的亮度、饱 和度,增强模型鲁棒性。改进 ASPP 结构中的卷积结构,组合不同采样率的并行空洞卷积层,提高模型对 边缘和远处车道线的识别能力,又利用深度可分离卷 积,减少模型参数量。在 ASPP 结构的空洞卷积层后添 加 DAMM 双注意力机制,调整通道、空间两方面的注 意力资源,使图像通道、空间上表征能力强的特征信息 被充分利用。为解决车道线数据集正负样本失衡问题, 损失函数采用二分类交叉熵损失与Dice loss 的加和,提 高模型的分割精度。实验结果表明,本文提出的改进 DeeplabV3+ 模型能够兼顾准确性和实时性,对车道线 的检测效果良好。
1 数据集选取与预处理
1.1 百度无人车数据集概述
本文采用的数据集选取自百度提供的无人车车道线 挑战赛“Road02”路段的数据集。每张图像大小均为 3384×1710 像素, 共 10972 张图像。除天气良好的平 直路面外,此路段还包含了眩光、车道线破损情况下的 长直型车道线和大曲率车道线数据图片,部分图像如 图 1 所示。
1.2 图像预处理
为防止无关物体干扰检测,裁剪并保留原图像下半 部分约 2/3 区域作为感兴趣区域,大小为 3384×1020 像素,再等比例缩放至 1128×340 像素,防止训练时显 存溢出。
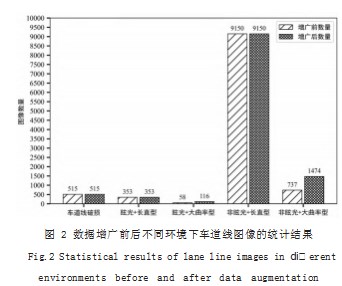
为防止模型过拟合,在训练前,使用水平翻转对数 据集中数量少的大曲率车道线进行增广,均衡样本种 类 ;在训练过程中,首先对数据集中每一批次(Batch) 内的图像进行随机裁剪、随机增加亮度、对比度和饱和 度,保持训练速度的同时模拟行驶过程中光线亮度变化 的情况。增广后的数据集共包含 11608 张图像,统计不 同环境下的车道线,得到的结果如图 2 所示。
去除数据集标签中车头、斑马线等无关标注所代表 的“交通规则信息”,降低模型学习难度,以提高检测 的准确率,故将这些类别的像素值全部赋 0.即视为背景。处理前后的标签对比图如图 3 所示。
其中,图 3(a)为处理前的标签,包含蓝、红、绿等 多种类别的标签,只保留车道线部分,即红蓝两色标签, 并赋值为 255.其余标签均赋值为 0.图 3(b)为处理 后的标签,只包含值为 0 的背景和值为 255 的车道线。
2 研究方法
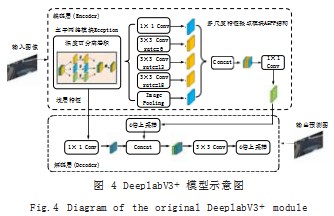
DeeplabV3+ 模型拥有较为复杂的编解码结构和较 好的网络分割能力,网络结构如图 4 所示。编码层分别 输出图像的浅层和深层特征信息, 即 2 倍下采样和 4 倍 下采样的结果。ASPP 结构汇聚不同感受野下的特征, 然后与浅层特征融合, 最后通过 3×3 卷积进一步整合, 输出预测结果图。
DeeplabV3+ 模型相较于其他模型而言,拥有更为 优异的分割性能,但仍有一定的缺陷。首先,它缺少注 意力资源的分配, ASPP 结构和深浅层特征的融合过程 将各通道的特征重要性归为一致,导致特征信息没有被 最大化利用 ;其次,DeeplabV3+ 中的 Xception 主干 网络训练困难且参数量庞大,推理时间较长,难以满足 车道线检测中兼顾准确性和实时性的要求。
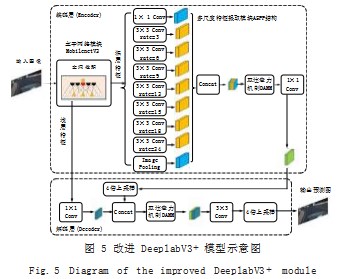
为兼顾 DeeplabV3+ 模型在车道线检测上的准确性 和实时性,本文对其进行改进,如图 5 所示。
首先,本文使用轻量化的 MobilenetV2 主干网络 代替原有的 Xception 网络,不仅大幅降低了运算成 本, 还兼顾分割精度 ;其次, 重新设计 ASPP 结构, 以 空洞深度可分离卷积为主体,进一步减少参数量,提高 检测实时性,又根据车道线检测的特点,增设更为合适 的不同采样率的并行空洞卷积层,有效提高车道线检 测的准确性。本文所提出的模型将重要的网络结构分 为 3 个模块 :以 MobilenetV2 作为主干网络模块、以 改进 ASPP 结构作为多尺度特征增强提取模块、以及 DAMM 双注意力机制模块,其功能分别为 :初步提取 车道线特征,提取更多不同感受野大小下的特征,以及 分配通道、空间两方面的注意力资源,提高模型预测 能力。
在改进 DeeplabV3+ 模型中,输入图像首先经过 MobilenetV2 网络,初步提取车道线特征。再送入多 尺度特征提取模块中提取深层信息,通过更多采样率的 空洞深度可分离卷积层提取到更为丰富的感受野下的特 征,将输出叠加再通过双注意力机制分配不同特征在空 间和通道上的注意力资源,然后通过 1×1 卷积降维,再通过 4 倍上采样恢复到浅层特征信息的尺寸。通过跳 层连接融合深层特征和浅层特征,借助浅层特征强有力 的局部特征表征能力,细化边界,解决边缘点模糊不清 的问题。在融合过程中,同样使用双注意力机制分配注 意力资源。最后使用 3×3 卷积核对预测结果进行微调, 并使用 4 倍上采样恢复特征图至输入图像大小,实现逐 像素分割。
2.1 主干网络模块
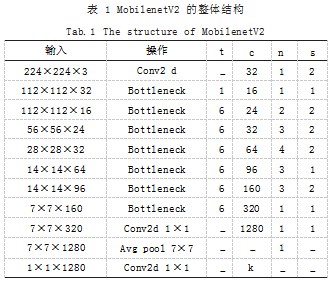
考虑到车道线检测的实时性要求,更换后的 Mo- bilenetV2 模型,其优点是轻量化、计算量少且易于训 练。它引入了倒残差块(Inverted Residual Block) 和 线性瓶颈结构(Bottleneck),MobilenetV2 结构如表 1 所示。
在倒残差块中, MobilenetV2 通过先升维,利用参 数量极少的深度可分离卷积提取特征,再降维的方式, 保证了高效的特征提取效果。此外,在反向残差块中, 用 ReLU6 激活函数代替 ReLU,限制 ReLU 的最大输 出为 6. 保证模型在数据精度较低的移动端仍有较高的 预测精度。
线性瓶颈结构,即去除非线性激活层,这是因为信 息从高维空间传递至至低维空间时,如果在低维度输出 层中使用非线性映射将会破坏信息。
表 1 中,每一行代表一个既定操作, t 为扩展因 子,用于成倍调整输入特征的通道 ;c 为输出特征的通 道数 ;n 为当前操作进行的次数 ;s 为步长,如果有多 个 Bottleneck, 则 s 只针对第一个 Bottleneck, 后面 Bottleneck 的步长均为 1.
2.2 双注意力机制模块 DAMM
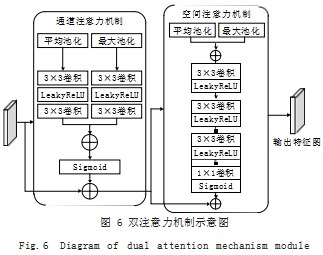
为降低注意力机制复杂度, 满足车道线检测实时性要 求,结合车道线图像的特点,本文提出了一种轻量化的双注意力机制模块 DAMM(Dual Attention Mechanism Module)、融合通道注意力机制 CAM(ChannelAttention Module) 和空间注意力机制 SAM(Spatial Attention Module),串行优化通道和空间上的注意力资源,示意 图如图 6 所示。
图 6 中通道注意力机制首先将输入的一组特征通道 分别进行平均池化和最大池化,以分别提取特征图的整 体特征及细节特征。在每一个池化后进行 3×3 卷积核 降维,再通过 LeakyReLU 替换原 CAM 中的 ReLU 激 活函数进行非线性激活,以避免反向传播过程中神经元 失活,再使用 3×3 卷积核进行升维。然后对处理后的 结果进行叠加,最后通过 Sigmoid 激活函数激活, 得 到输出权重。将输出权重和输入特征图进行相乘,达到 分配通道间注意力资源的效果。
空间注意力机制分别将输入图像进行并行的全局 平均池化和全局最大池化,以关注车道线及车道线边 缘在空间上的分布。然后考虑到车道线检测实时性需 求,用 3 个 3×3 卷积核替代原 SAM 中的 7×7 卷积 核,在不改变感受野的前提下大幅减少参数量,实现空 间各点重要性的学习。且在每一个 3×3 卷积层后增加 LeakyReLU 激活函数用以非线性映射,防止线性映射 表达特征信息不充分的问题。然后经过 1×1 卷积调整 通道数为 1.再用 Sigmoid 函数激活,得到权重矩阵。 将该矩阵与输入相乘,得到空间注意力机制的输出。
所提出的双注意力机制模块 DAMM 应用于两个位 置 :(1)放置于多尺度特征提取增强模块的通道叠加之 后 ;(2)放置于深、浅层特征信息融合之后。
2.3 多尺度特征提取增强模块
与其他检测对象相比, 车道线的形状、分布较不稳 定,长直车道线、块状分段车道线、受遮挡车道线、弯 道车道线等各种类型并存,繁杂路段的车道线分布情况大不相同。单一尺度的感受野难以捕获各类信息,结合 边缘车道线和远处车道线漏检率高的特点,本文在原 有 ASPP 结构的基础上,使用更多采样率的空洞卷积层 提取更为丰富的感受野下的特征信息。此外,采用深度 可分离卷积替换 ASPP 中的普通卷积,有效减少了参数 量,使其提升模型性能的同时,进一步满足模型检测车 道线的实时性。
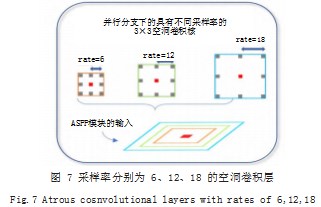
(1)更多不同采样率下的空洞卷积层。ASPP 结 构由不同采样率的空洞卷积层、1×1 卷积层和 Image Pooling 层所构成。其中实现多尺度特征提取的是空洞 卷积层。通过在普通卷积中注入空洞,形成空洞卷积 层,以此增加感受野。如图 7 所示,空洞卷积的采样率 分别为 6、12、18.
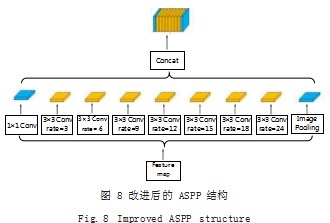
由于空洞卷积的采样率间隔过大, ASPP 结构特征 提取较为稀疏,从而丢失图像的部分局部信息。为此, 在原有采样率的基础上增加采样率分别为 3、9、15 的 空洞卷积,减少图像中边缘信息及小目标物体信息的丢 失率。如图 8 所示表示改进后的 ASPP 结构在不同尺度 的空洞卷积下的感受野大小。
(2)空洞深度可分离卷积。深度可分离卷积在保持 原有特征提取感受野的基础上极大地减少参数量,减少 了网络的训练量。它将卷积过程分为逐通道卷积和逐点卷积两部分,逐通道卷积的卷积核与输入图像的通道 一一对应。经过逐通道卷积后,特征图的通道数仍与输 入前的通道数一致。由于不同通道的相同位置具有联 系,故使用 1×1 的逐点卷积调整通道数,建立不同通 道间的联系。深度可分离卷积的示意图如图 9 所示。
3 实验与分析
3.1 实验环境配置
本次实验所用的操作系统是 ubuntu20.04.CPU 为 Intel(R) Xeon(R) Platinum 8358P CPU @ 2.60GHz, GPU 为 RTX 3090. 内存为 90GB, 硬盘空间为 50GB。 深度学习框架为 PyTorch 1.10.0.CUDA 版本为 11.3.
3.2 实验过程与细节
3.2.1 实验过程
实验采用 Step 的学习率衰减策略,并使用 Adam 优化器。将扩充后的数据集按照 8.5:1:0.5 的比例划分 为训练集、验证集和测试集。实验设置的初始学习率为 0.0005. 最小学习率为 5e-6.batch_size 为 24.分别 采用二分类交叉熵损失函数、二分类交叉熵损失函数和 Dice loss 的加和进行实验。实验共训练 100 轮, 在训练 过程中,记录每轮的训练损失函数值和验证损失值。此 外,每 5 轮进行一次模型评估,并保存评价指标mIoU 最优的权重。
本文设计的实验如下 :
(1)针对设计好的不同模块,采用消融实验的方法 验证每个模块的必要性 ;
(2)在改进的 DeeplabV3+ 模型中分别使用两种不 同的损失函数,以确定适合该数据集的最优损失函数 ;
(3)将改进的 DeeplabV3+ 模型与主流深度学习模 型,如与 Unet、PSPnet 进行对比,验证本文模型兼具 准确性和实时性。
3.2.2 损失函数
交叉熵损失函数可以在训练初期较快地更新权重, 故选用其作为基础损失函数。此外,考虑到数据集的正 负样本不均衡,如果直接使用交叉熵损失函数进行训 练,会导致模型趋向于学习到图像中占比较大的特征信息,而忽视了车道线或某类车道线特征信息,所以引 入Dice loss。Dice loss对于样本不均衡的场景性能较优, 训练过程中更注重对前景区域的特征信息挖掘。
本文分别在改进后的 DeeplabV3+ 模型中采用两种 损失函数,依次为 :(1)二分类交叉熵损失函数 ;(2) 二分类交叉熵损失函数和Dice loss 的加和。二分类交叉 熵损失函数BCE Loss用以衡量真实概率分布与预测概率分布间的差异,计算公式如式(1)所示 :
mPA为首先计算每类预测结果为正的像素点的个数 与该类像素点总数的比值,然后再求每类的平均数,其计算公式如式(7)所示 :
其中, M 为类别数, TP 为被预测为正类但实际为 正类的像素点个数之和, TN 为被预测为负类但实际为 负类的像素点个数之和, FN 为被预测为负类但实际为 正类的像素点个数之和, FP 为被预测为正类但实际为 负类的像素点个数之和。
3.2.4 不同损失函数的对比
为探究单一的二分类交叉熵损失函数与二分类交叉 熵损失函数与Dice loss的加和的优劣,基于 DeeplabV3+模型设计实验,两种方案训练得到的IoUlane、IoUbackground、 mIoU 、Accuracy、mPA 、单图预测时间和模型参数量如 表 2 所示。
(1)方案一 :使用二分类交叉熵损失函数 ;
(2)方案二 :二分类交叉熵损失函数与Dice loss 的 加和。
从表 2 中可以看出, 方案二在各项指标的数据均优 于方案一,故选择二分类交叉熵损失函数与Dice loss 的 加和作为本文使用的损失函数。
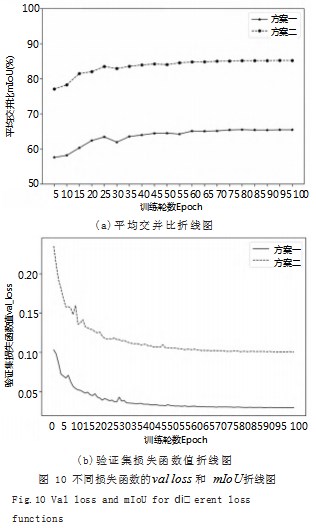
训练过程中,两种方案平均交并比mIoU 和验证集 上的损失函数值 val loss 随训练轮数变化的折线图如图 10 所示。
从图 10 可以看出,两种损失函数在训练过程中 随训练轮数的增加而 val loss 逐渐减少并趋于稳定, mIoU 也逐渐增加并趋于稳定,说明模型在验证集上的 表现良好,模型逐步学习到车道线特征。但无论是训练轮数是多少,方案二的平均交并比均高于方案一,说明 方案二所采用的损失函数最优。
3.2.5 消融实验
本文共在 DeeplabV3+ 模型的基础上更改了主干网 络模块、多尺度特征提取模块,并添加了双注意力机制 模块。为验证在 DeeplabV3+ 模型中添加上述三种模块 的必要性,设计如下的消融实验 :
(1)方案一 :在 DeeplabV3+ 模型中改进主干网络 模块,并进行训练 ;
(2) 方案二 :在方案一的基础上, 改进为多尺度特 征提取增强模块,并进行训练 ;
(3) 方案三 :在方案一的基础上, 添加双注意力机 制模块 DAMM,并进行训练。
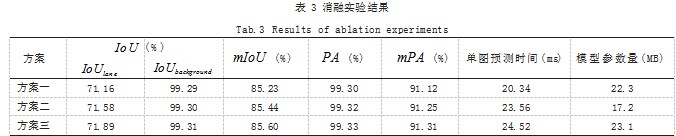
三种方案均使用二分类交叉熵损失函数和Dice loss 的加和作为损失函数。三种方案训练得到的语义分割性 能指标IoUlane 、I,oUbackground、, mIoUP,A、 mPA、单图 预测时间和模型参数量如表 3 所示。
相对于以 Xception 为主干网络的 DeeplabV3+ 模 型,方案一中改进了主干网络模块,使得主干网络的参 数量由 88M 变为了 3.4M, 模型在兼顾准确性的同时保证了实时性。以方案一中的模型为基础模型,与方案 二、三对比,验证方案二、三中添加对应模块的必要 性。方案二中改进为多尺度特征提取增强模块,即使额 外添加了多个并行的空洞卷积层,训练得到的模型整 体参数、预测时间仍小于方案一,此外,由于获得了 更为丰富的不同感受野下的特征信息,故mIoU 有所提 高 ;方案四中添加双注意力机制模块 DAMM,模型的IoUlane 和mIoU 均有所提高,说明模型可以较好地分配 空间、通道两方面的注意力资源,以达到较好的模型分 割效果。
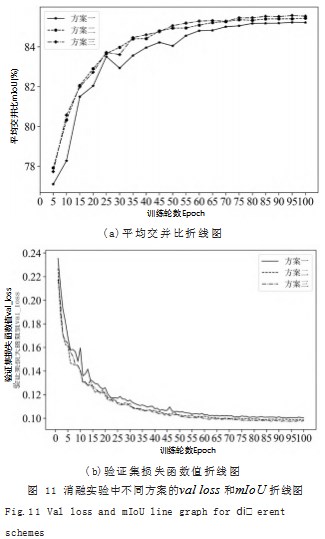
在训练过程中,各方案的val loss 和mIoU随训练轮数的变化折线图如图 11 所示。
从图 11 可以看出,随着训练轮数的增加,各方案 的val loss 逐渐减小并趋于稳定,说明各方案的模型均 基本训练完毕,而mIoU 则逐渐增大并趋于稳定,说明 各方案的模型分割能力均逐渐提高。方案一、二和三的 val loss 收敛速度基本一致,说明设计的各模块较为稳 定有效。
3.2.6 不同图像分割模型的对比
为进一步验证改进 DeeplabV3+ 模型的分割性能, 将本文提出的模型与经典的图像分割模型进行对比,设 计的实验方案如下 :
(1)方案一 :使用 DeeplabV3+ 模型进行训练 ;
(2)方案二 :使用本文所提出的改进 DeeplabV3+ 模型进行训练 ;
(3) 方案三 :使用以 VGG 为主干网络的 Unet 模 型进行训练 ;
(4)方案四 :使用以 MobilenetV2 为主干网络的 PSPnet 模型进行训练。
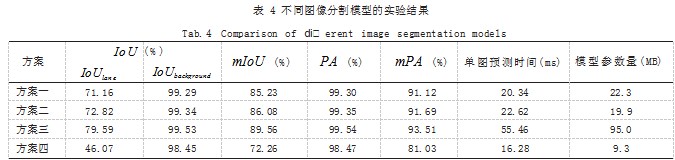
四种方案均使用二分类交叉熵损失函数和Dice loss 的加和作为损失函数。四种方案训练得到的 IoUlane、 I,o,Ubackground、, m,IoU, PA,mPA、单图预测时间和模型 参数量如表 4 所示。
从表 4 中可以看出,改进 DeeplabV3+ 模型的 IoUlane 较 DeeplabV3+ 模型高出 1.66%, 在mIoU 上高 出 0.85%,单图预测精度虽然提高了 2.28ms,但模 型参数量却减少 了 2.24MB, 说 明改进 DeeplabV3+ 模型较 DeeplabV3+ 模型更适合车道线检测。改进 DeeplabV3+ 模型的单图预测时间和参数量略低于 PSPnet 模型,但 PSPnet 的高实时率和低参数量却牺 牲了预测精度,这会导致网络的预测效果不佳,干扰自 动驾驶中车辆决策系统的判断。改进 DeeplabV3+ 模 型的IoUlane 和 mIoU 略低于 Unet 模型, 但 Unet 的高 精度却牺牲了单图预测时间和参数量,其单图预测时 间和参数量分别是改进 DeeplabV3+ 模型的 2.45 倍和 4.77 倍,车道线预测的实时性较差。综上所述,改进DeeplabV3+ 可以兼顾车道线检测的准确性和实时性。
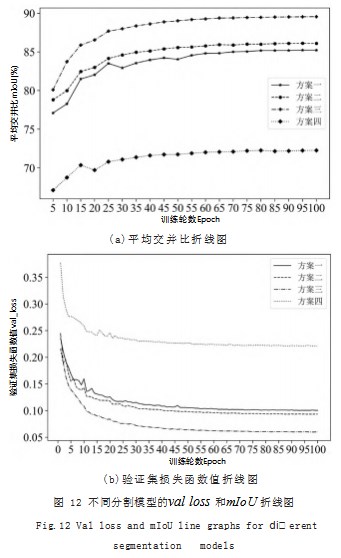
在训练过程中,各方案的 val loss 和 mIoU 随训 练轮数的变化折线图如图 12 所示。可以看出,由于 val loss 逐渐收敛并趋于稳定,各方案的模型训练完 毕。对比于方案一和方案二在每 5 轮中计算得到的 mIoU 值更高,说明本文模型的分割性能稳定、良好 ; 对比于方案三和方案四,方案二在每 5 轮中计算得到的mIoU 值更高,说明本文模型的分割性能较主流分割模 型更优。
使用四种方案中的模型对测试集中不同环境下的车 道线进行预测,得到的对比图如图 13 所示。
从图 13 可以看出,在眩光和低亮度两种不同情况 下,改进 DeeplabV3+ 也能有较好地预测效果 ;改进 DeeplabV3+ 模型的预测效果在预测边缘车道线像素点 和远端车道线像素点时, 较 DeeplabV3+、PSPnet 模 型均有一定的提升,这是由于多尺度特征增强提取模块 和双注意力机制模块联合带来的效果,但较 Unet 模型 仍有一定地进步空间。
4 结论
本文分别针对 DeeplabV3+ 模型的 Xception 主干 网络难以训练、无法合理分配空间和通道权重以及难以 兼顾准确性和实时性的问题,分别将主干网络更换为 MobilenetV2、融合双注意力机制 DAMM 以及使用空 洞深度可分离卷积,由此提出了改进 DeeplabV3+ 模 型, 有效改善了针对长直型车道线和大曲率车道线识别精 度较低的问题。经实验表明,提出的改进 DeeplabV3+ 模型检测的像素精度高达 99.35%, 平均交并比达到 86.08%,单图预测模型可以达到 22.62ms,模型参数 量为 19.9MB,兼顾准确性和实时性,在车道线检测方 面有较强的泛化能力。
参考文献
[1] 段鸿.基于混合模型的多车道线检测方法研究[D].重庆:重庆 邮电大学,2021.
[2] 胡骁,李岁劳,吴剑.基于特征颜色的车道线检测算法[J].计算 机仿真,2011.28(10):344-348.
[3] 吴一全,刘莉.基于视觉的车道线检测方法研究进展[J].仪器 仪表学报,2019.40(12):92-109.
[4] 孙鹏飞,宋聚宝,张婷,等.基于视觉的车道线检测技术综述 [J].时代汽车,2019(16):8-11.
[5] LONGJ,SHELHAMER E,DARRELL T.Fully Convolutional Networks for Semantic Segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2015:3431-3440.
[6] BADRINARAYANAN V,KENDALL A,CIPOLLA R.Segnet:A Deep Convolutional Encoder-decoderArchitecture for Image Segmentation[J].IEEE transactions on Pattern Analysis and Machine Intelligence,2017.39(12):2481-2495.
[7] ZHAO H S,SHI J P,QI X J,et al.Pyramid Scene Parsing Network[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2017:2881-2890.
[8] CHEN L C,ZHU Y,PAPANDREOU G,et al.Encoder- decoder with Atrous Separable Convolution for Semantic Image Segmentation[C]//Proceedings of the European conference on computer vision (ECCV),2018:801-818.
[9] MOUJTAHID S,BENMOKHTAR R,BREHERET A,et al. Spatial-UNet:Deep Learning-Based Lane Detection Using Fisheye Cameras for Autonomous Driving[C]//International Conference on Image Analysis and Processing.Springer, Cham,2022:576-586.
[10] QIN Z Q,WANG H Y,LI X.Ultra Fast Structure-aware Deep Lane Detection[C]//European Conference onComputer Vision.Springer,Cham,2020:276-291.
[11] Fan C,Chen F F,Song Y P.Lane Detection Based on Multi-Frame Image Input[J].International Journal of Pattern Recognition and Artificial Intelligence,2022.36 (07):2254012.
[12] WANG Z,REN W Q,QIU Q.LaneNet:Real-time Lane Detection Networks for Autonomous Driving[J].arXiv preprint arXiv:1807.01726.2018.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/53906.html