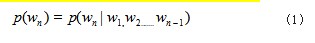SCI论文(www.lunwensci.com)
摘 要:在不同的电商平台中,部分用户购买商品后会发表评论信息,以此来反馈购买商品的态度。对用户的商品评论数 据进行挖掘与分析,有利于商户与生产企业预估商品销量、改进商品品质而言具有潜在的应用价值。因此本文主要工作是采用 改进的 Word2Vec 词嵌入模型,将整个情感词典进行扩展分析,以改进情感词典的电商平台适用性,确定用户真实的情感倾 向,再将其与情感词极性分类算法有效结合,最终提升整体算法的情感分类性能,实验结果表明,所提 Conv1d-Word2Vec 模 型相较于传统模型具有更优的情感识别效果。
关键词:词嵌入,情感分类,一维卷积,词极性算法
Research on Emotion Classification of Product Reviews Based on Word Polarity Algorithm and One-dimensional Convolution Word Vector Technology
LI Xinhao
(University of Shanghai for Science and Technology, Shanghai 200093)
【Abstract】: In different e-commerce platforms, some users will post comments after purchasing products to feedback their attitude towards the products. Mining and analyzing product review data of users has good practical value for enterprises. In this context, the main work of this paper is to use the improved Word2Vec word embedding model, to expand and analyze the entire sentiment dictionary, building a good sentiment dictionary of e-commerce business platform, and determining users' real emotional tendencies, it is combined with word polarity algorithm effectively. Finally, the emotion analysis and improvement of the whole algorithm are carried out. The experimental results that Conv1d-Word2Vec model has better effect on emotion recognition than traditional model.
【Key words】: Word2Vec;sentiment classification;conv1d;word polarity algorithm
0 引言
信息时代促进了互联网的高速发展,相继出现的大 型网络电商平台提升了消费者购物的便利性,如果能使 用机器学习方法对商品评价文本进行有效的情感分类, 就能提升整体电子商务的生态质量,可见情感分类是当 前人工智能自然语言处理领域中的研究热点。
现有情感分类方法主要为 3 类 :半监督分类、有监 督分类和无监督的分类方法。其中无监督分类主要采用 固定句法模式 [1] 或者预制情感词典 [2] 来分析商品的评论 数据集,例如 Turney 等学者通过评论语句之中的词性 来完成固定句法模式的挖掘,但是相似句法的识别准确率还不够理想 [3],Ohaha 等学者采用了 SentiWordNet 情感词典,该词典具有包含了一系列将常识推理、语言 学和机器学习相结合的情感分析工具,但受限于无监督 分类的特点,分析精度还有欠缺 [4]。
相比于无监督法,有监督分类处理的准确率普遍较 高,原因在于其使用的机器学习分类器是带有标签的训 练样本优化生成的,所以具有完整的情感分类指向。有 监督的情感分类处理算法通常在操作的初始会利用向量 空间模型、将已标注的词语作为模型的输入训练,通过 特征函数选取最具区分性的特征等方法来将评论文本转 化为标准向量,然后训练机器学习的分类模型完成具体评论向量的分类,徐琳宏等人将文本特征划定为情感倾 向强烈的词语,从而提升了数据的识别分辨率 [5]。可见 有监督分类方法主要难点在于测试样本特征的提取难度 较高,导致算法的跨行业迁移应用较难。半监督分类介 于有、无监督方法之间,理论上能吸收两种算法各自的 优势,但是融合难度较高,不利于实际应用。
综上分析,有监督学习还存在如下诸多问题 :首先 情感词的特征极性不明显 ;其次机器学习分类器对上下 文的关联性还有不足,即不能充分考虑情感词的原极 性,从而会导致算法迁移扩展性较差。针对上述问题, 本文提出一种基于融入 Conv1d 的 Word2Vec 词嵌入 情感分类处理模型,构建适应网络电商评论的情感词 典,并进一步在扩充情感词典基础上,利用改进词极性 算法 [6] 来分析真实商品评论的情感性。
1 词嵌入情感分类方法
1.1 基本词嵌入网络结构
词嵌入是一种重要的使用方式,每一个词语都可以 作为一个实数向量来进行分析,例如评论文本中经常出 现的“一般、喜欢、不喜欢”进行向量空间的映射,此 时可以将不喜欢的词语映射为(-0.1 -0.2 -0.3),喜欢的 词语映射为(0.1 0.2 0.3), 一般的词语映射为 (0.2 0.4 0.6),后续不同的词语转化为各自的向量空间。
在 NLP 中存在多种神经网络的词向量计算方法, 例如 NNLM、Word2vec 等,其中被广泛运用在词向 量中的 Word2vec 是由 Miko-lov 在 2013 年提出的 [7]。
在整个词嵌入模型分析之中, 常用的模型为 Word 2vec,此模型由谷歌公司进行编码完成,主要通过深度 学习与分析的思想来进行训练,能够将整个不同的词表 进行实数值量的高效转化,通过这样的处理之后,文本 数据信息能够处理为高维空间的向量运算,同时文本语 义的相似度就转化为向量空间的相似度来进行表示。
Word2vec 词嵌入技术包含 2 种词向量计算模型, 分别是 Skip-gram 模型和 CBOW(Continuous Bag- of-Words)模型。Skip-gram 模型的预测次数较多,训 练时间较长,比较适合计算数据较少的词向量,而对于 文本量较大的数据, Skip-gram 模型计算时复杂度较高。 相反,此情况适用于 CBOW 模型,该模型具有较高较 准确的计算精度,其主要思想是根据上下文内容来预测 句中文字出现的位置 [8]。
Word2vec 技术主要是依据句中词语间的相互作 用,得出语句中第 n 个单词的出现概率,以及受之前 n-1 个单词的影响情况,具体如公式(1)所示 :
1.2 Word2Vec 模型原理
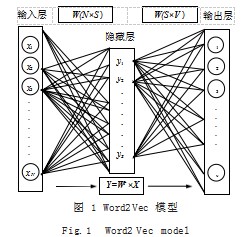
根据上下文单词出现的频率,继而组成的词向量 矩阵,可以计算出词典中两个词之间的相似度,得 到一个相似矩阵是由相似度为 0-1 间的一个值组成。 Word2Vec 模型输入层是把 N 个上下文的词, 经过嵌 入层将结果沿着输出层达到目标词所在的节点,最终得 出与目标词之间的相似性,将相似性保留在词向量中。 如图 1 所示即为该模型。
在 Word2Vec 模型中,其中输入层是一个 one-hot 向量(考虑一个词表 N,里面的每一个词,都有一个编 号 i ∈ {1....,|N|}, 那么例如词 i 的 one-hot 即表示就 是一个维度为 |N| 的向量,其中第 i 个元素值非零,其 余元素全为 0.即为[0.1. 0..., 0]T ),而隐藏层是一个 S 维 稠密向量,输出层是一个 V 维稠密向量, W 表示词典 的向量化矩阵,也是输入到隐藏层以及隐藏层到输出的 权重参数 ;因此输入层到隐藏层表示对上下文词进行向 量化,而隐藏层到输出层,表示计算上下文词与词典的 每个目标词进行点乘计算,例如输入的向量 X 是 [0. 0. 2.0.0.0],W 矩阵是 [2.1.3], 则 W 的转置乘上 X 得到 [4.2.6] 即作为隐藏层的值。
隐藏层到输出层也有一个权重矩阵 W,因此,输 出层向量 y 的每一个值,其实就是隐藏层的向量点乘权 重向量 W 的每一列,比如权重矩阵列向量为 [1. 0. 1], 最终输出就是向量 [4.2.6] 和列向量 [1.0.1] 点乘 之后的结果为 10 ;最终的输出经过 Softmax 函数,将 输出向量中的每一个元素归一化到 0-1 之间的概率,概 率最大的,就是预测的词。
Word2Vec 模型在对词向量矩阵进行处理时主要采用 连续词袋进行, 后续通过处理共现矩阵来获取平均上下文 的词向量,但是 Word2Vec 模型也存在不足,例如其无法 对结果进行动态优化,以及 Word2Vec 模型解决词类转换 是一对一的关系,对多义词的样本没有办法更好的解决。针对上述问题,在此提出在原有模型结构的隐藏层中融 入 Conv1d 一维卷积层加固化过滤器进行改进优化。
1.3 Conv1d 一维卷积层原理
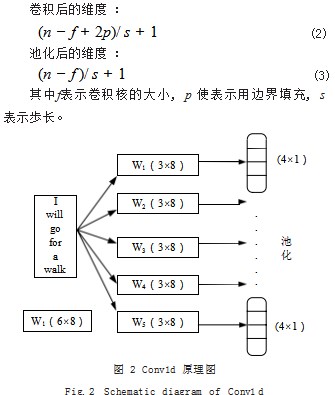
如图 2 结构举例所示,对于一个样本而言,假如句 子长度为“I will go for a walk”6 个词, 词向量的维 度为 8.filters=5.kernel_size=3. 所以卷积核的维度 为(3×8), 那么输入(6×8) 的矩阵经过(3×8) 的 卷积核卷积后得到的是(4×1) 的一个向量, 又因为有 5 个过滤器,所以最终是得到 5 个(4×1)的向量。具 体运算公式如公式 (2) 和公式 (3) 所示 :
1.4 情感分类具体工作过程
其中具体步骤所需文本数据预处理和预训练模型 (预训练模型是一个已经训练好的保存下来的网络, 该 网络之前在一个大型的数据集上进行了训练,其作用可 以将预训练模型当特征提取装置使用,用于迁移学习, 当其学习到的特征容易泛化的时候,迁移学习才能得到 有效的使用,现使用较多的例如 Bert 模型等)。
在分类过程中需要用到机器学习较为常见的分类器 :
(1) 线性回归 :根据给出的数据拟合出一条直线或曲 线,反应数据的分布 ;评判的准则或损失函数 :统计所有 预测值以及对应实际值y 之间的距离之和,使其最小化。
(2) 逻辑 (Logistic) 回归 :可以把输出的值映射到 0-1 之间表示概率问题,如果中间设定某一阈值(比如 0.5), 大于 0.5 表示正类,小于 0.5 表示分类,即二分类问题。
(3) Softmax 回归 :跟逻辑回归一样, 只不过 Softmax 针对的是多分类。
(4) SVM 支持向量机 :定义在特征空间上的线性 分类器,是一种二分类模型。
在本文多分类任务中,将最终的网络输出多个值, 分别代表不同种类的值,再将神经网络的输出值转化为 对应每种类别的概率,此时我们需要一个 Softmax 激活函数公式如公式(4)所示 :
整个流程是通过预处理的数据放入 Word2Vec 训 练文本向量,紧接着对模型的预训练最终经过 Softmax 实现文本情感的分类。
2 商品评论情感分析模型改进
2.1 词嵌入模型改进
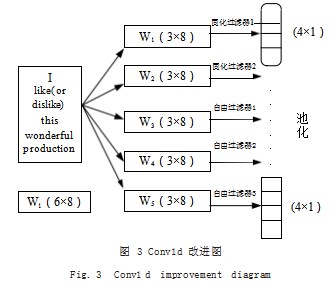
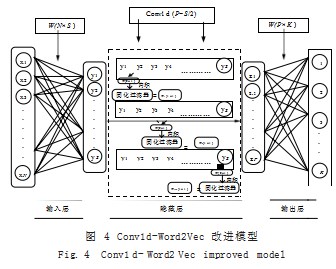
如图 3 所示, 在原有的一维卷积层中加入固化过滤 器,因为有些过滤器文字是固定化含义,例如“我喜 欢,很快”“不喜欢,没作用,不咋地”等,加入固化 过滤器后,可以准确过滤出所需要的情感词向量,同时 对比原有过滤器得出词向量后,明显节约筛选特征词 时间并提升抓取词语特证效率,将加入固化过滤器的 Conv1d 原理融入 Word2Vec 模型中如图 4 所示。
将加入固化过滤器的 Conv1d 原理融入隐藏层中, 由图 4 可知,在输入层中得出的所有 y 向量经过在隐藏层中利用 Conv1d 一维卷积作用,将两两向量组合与一 个(2×1) 的矩阵内积, 经过固化过滤器的过滤之后得 到一个(1×1)的向量,再将(2×1)的小矩阵移动到 3. 4 节点,往后依次类推得到多个由(1×1)的向量 拼接成的矩阵 Z,向量长度则恰好是 Y 长度的一半,最 终再将 Z 中(2×1)的矩阵和其中的(1×2)的分块 矩阵内积得到由多个(1×1)的向量数组成的(1×K) 的矩阵,最终的输出经过 Softmax 函数,得出预测词。
由图 4 可知,加入一维卷积层可以从宏观数据压缩 变为局部重点数据压缩,其优点是对输入样本进行了特征 提取,对噪声特征有一定的过滤作用,同时对样本进行了 重采样,有助于解决样本不平衡问题,即减少了大样本数 量,达到再次降维的效果,训练速度也得到了明显的提 升,同时再加入固化过滤器后,如果被固化为电子商务高 频用语,即可最终过滤得出高效率的情感特征词向量。
2.2 改进情感处理模型及其分类过程
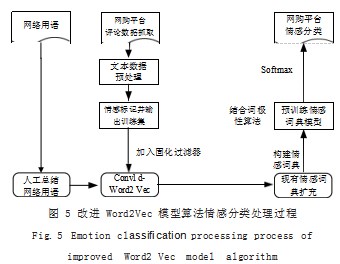
如图 5 所示整个算法分析中基准词的选择可以通过商 品属性、常用网络词语、商品名称来进行,通过文本数据 的预处理后,构建业务平台的情感词典,主要包括两个步 骤 :(1)在改进并加入过滤器的 Word2Vec 中完成基准 词与候选词间的相似度 ;(2)需要分析候选词的极性值与 褒贬倾向。目前自然语言的处理中,对情感极性进行分析 与计算主要结合情感词典与预料库两种方式进行,而通过 情感词典进行分析与处理时,主要核心点有两个方面,首 先是能找到适合处理领域的情感词典 ;其次是确定情感词 典中不同业务词语的褒贬词。由于催生了新的网络语,需 要将原有情感词典进行扩充, 随后对情感词典模型进行预 训练,最终通过 Softmax 实现网购平台的情感分类。
情感分析主要需要结合情感词典进行,其关键处理 点是对情感词、程度词、否定词、感叹句等处理,对于 程度词的处理,情感的强烈程度主要通过程度副词进行,需要对不同程度词语进行权值的设置,同时需要对 相邻的情感词进行修饰程度词的判断 ;在情感词的分析 后,根据需要设置不同的方法,其中最简单的方法为初 始化能够设置贬义设置的词语数值为 -1.褒义设置词语 的设置数值为 +1 ;针对感叹词要结合此不同词语进行 强烈情感的分析与设置 ;对于否定词的分析,需要对其 中否定词的数字进行统计,判断人们的情感是否存在反 转,若统计的次数为基数,此时情感数值为 -1.若统计 的次数为偶数,此时设定情感数值为 +1 ;针对一条评 论进行分析确定时候,需要对其中的分句来进行统计相 加,完成整个评论的语句分析。
3 实验数据处理及结果分析
3.1 实验环境
在整个电商平台的评论数据信息进行分析时,主要的 算法运行操作系统为 Win7 系统,实验环境为 Inter-Core i7-8700@2.50 GHz 硬件配置为 100G 硬盘,4G 内存的台 式机,整个算法采用的编程语言为 Python,编程工具 为 JetBrains PyCharm。
3.2 实验数据获取
所提取的评论文本来自中国最大的电商平台,采集的 评论条目总量达 6 万余条,涉及 14 大类商品,信息采集 范围主要包括商品的名称、价格、属性、评论等数据, 文 本信息中含有大量的情感词,采用所研究的方法对评论文 本进行提取分析。对于整个商品评论数据进行分析时, 需 要爬虫获取某电商平台的洗护类商品的评论数据,主要爬 虫的商品为电商平台排名在前 10 名的热门商品,对这 10 种商品爬虫获取 2000 条评论数据信息,完成整个语料电 商平台情感词典的构建, 后续选择部分评论数据信息进行 标注处理, 其中正向评论与负向评论分别标注的数量为 100 条,选择中性评论的数量为 100 条,总共算法测试分 析的数量为 500 条。部分样本处理结果如表 1 所示。
3.3 参数设置
本文实验涉及到许多参数的设置,需要训练的语料 库 text8 为语料库文件名,取参数为 1 的 CBOW 表示使 用 CBOW 模型,设定词向量维数 size200 维,训练过程 中截取上下文的 Window 大小, 默认为 8.Negative 为 0 表示未采取负采样,sample 为默认值 e-4.threads 线程数目默认为 20.训练的迭代次数 iter 为 19 次。
3.4 实验结果分析
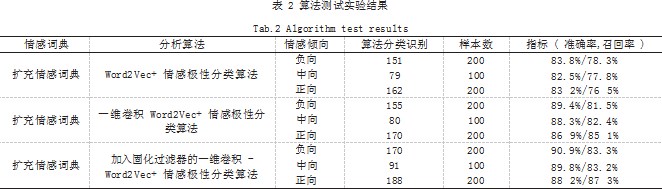
在整个算法测试分析之中,通过加入的固化过滤器 的一维卷积 Word2Vec 词嵌入模型来对网购平台的电 商情感词典进行扩充,结合情感极性算法,对整个中性 评论、正向与负向的评论进行分析与处理,主要的评价 指标采用召回率与准确率来进行对比分析。具体算法测 试结果如表 2 所示。
对比分析,虽然加入一维卷积 Word2Vec 的情感 极性分类算法在效果上有明显的改善提升,但加入固化 过滤器后的一维卷积 Word2Vec 的情感极性分类算法 结果明确展示召回率与准确率的处理结果最好,同时此 情感极性算法在整个中性评论数据上的错误率低于 4%。 综合结论能够看出,此算法在整个情感倾向的识别与判 断中具备良好的处理效率。
4 结语
本篇问题主要对电商平台中的评论数据进行了挖掘 与分析,完成对用户情感倾向的分析,主要提出并采 用的方法是基于改进 Word2Vec 模型的情感分类方法, 此方法对于爬虫获取的评论数据集进行了充分挖掘,完 成电商业务平台情感相关词典的构建,提出相关的情感 词极性分析算法,进行实验分析相比之下,各个处理效 果有良好的改进,具体处理结果内容如下所示 :
结合改进 Word2Vec 词嵌入模型,即加入固化过滤 器的一维卷积 Word2Vec 与情感极性算法的结合,能够 较好的还原整个商品评论之中出现的各类情感词语, 包 括程度副词、上下文之间的关联词等,有效避免以往统 计学之中出现的不可靠问题。在整个算法的处理之中, 使用的扩充情感词典能够对网络用语进行处理,有效降 低了系统之中的网络语言对整个算法倾向性分析的影响。
参考文献
[1] 梁娜,耿国华,周明全. 自然语言处理中的语义关系与句法模 式互发现[J].计算机应用研究,2008(8):2295-2298+2308.
[2] 宗宇,方朝阳,吴波.面向在线评论的领域情感词典的自动构 建[J].现代计算机,2021(18):79-84.
[3] TURNEY P D.Thumbs up or Thumbs Down:Semantic Orientation Applied to Unsupervised Classification of Reviews[C]//Meeting on Association for Computational Linguistics,2017.
[4] Bruno Ohana,Brendan Tierney.Sentiment Classification of Reviews Using SentiWordNet[C]//9th.IT & T Conference, 2018.
[5] 徐琳宏,丁堃,林原,等.基于机器学习算法的引文情感自动识 别研究— 以自然语言处理领域为例[J].现代情报,2020.40(1): 35-40+48.
[6] 聂卉,首欢容.基于修正点互信息的特征级情感词极性自动 研判[J].图书情报工作,2020.64(5):114-123.
[7] 周顺先,蒋励,林霜巧,等.基于Word2vector的文本特征化表 示方法[J].重庆邮电大学学报(自然科学版),2018.30(2):272-279.
[8] 杨河彬,贺樑,杨静.一种融入用户点击模型Word2Vec查询 词聚类[J].小型微型计算机系统,2016.37(4):676-681.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/53814.html