SCI论文(www.lunwensci.com):
摘 要: 随着国内近几年就业形势的愈发严峻, 国内招聘市场的网络趋势化也较为明显, 深度挖掘和充分利用数据背后 隐藏的价值能够给人们未来的职业规划做出指导。本文以智联招聘网站为例,使用基于 Python 的爬虫技术以及 Selenium 框 架,设计一种自动化采集数据的程序,并对采集的数据使用 Pyecharts 对公司概况、城市分布和薪资水平等关键信息进行可视 化分析。最后,基于数据及分析结果,对大数据相关专业毕业生的职业规划提出建议。
关键词:大数据 ;就业指导 ;Python 语言 ;网络爬虫 ;Selenium 框架 ;数据分析 ;Pyecharts
Crawling and Analysis of Zhilian Recruitment Data Based on Python and Selenium
ZHANG Jiawei, GUAN Chengbin
(Neusoft Institute Guangdong of Information Management and Engineering School, Foshan Guangdong 440605)
【Abstract】:With the increasingly severe employment situation in China in recent years, the network trend of the domestic recruitment market is also more obvious. Deep mining and making full use of the value hidden behind the data can guide people's future career planning. Taking Zhilian recruitment website as an example, this paper uses Python based crawler technology and Selenium framework to design an automatic data collection program, and uses Pyecharts to visually analyze the collected data on key information such as company profile, city distribution and salary level. Finally, based on the data and analysis results, this paper puts forward suggestions on the career planning of big data related professionals.
【Key words】: big data;employment guidance;Python language;web crawler;Selenium framework;data analysis; Pyecharts
0引言
互联网信息技术的高速发展促使人类社会的数据种类和规模以前所未有的速度增长,越来越多人开始重视数据背后隐藏的巨大价值[1]。2022年高校毕业生数量相对增多,也是就业形势非常严峻的一年,促使国内网络招聘的迅猛发展。然而现有的招聘网站发布的信息数量庞大且复杂,求职者难以从中找到心仪的工作,企业也难以在众多应聘者中找到相关岗位的人才。如何从多样化的数据中准确收集到有效的信息,如何在海量数据中挖掘蕴藏的重要价值[2]。本文针对该问题,设计出一个基于Python语言的Selenium自动化网络爬虫,以智联招聘网站为例,获取大量招聘数据,并对这些数据进行预处理和可视化分析,即可为求职者提供具有参考价值的指导信息,也可为企业在众多求职者中挖掘更多的人才[3]。
1相关技术分析
1.1Python语言简介和优势
Python是一种开源免费的计算机程序设计语言,近年来逐渐成为非常受欢迎的程序设计语言。这门语言简洁易学、灵活开放、用途广泛,支持调用庞大的第三方库,能够处理海量数据,例如用途广泛的自动化工具Selenium库、高性能的数据处理库Numpy和绘图速度快、交互设计优秀的数据可视化库Pyecharts等。
1.2网络爬虫原理
网络爬虫,就像在网络上爬行的蜘蛛,能够按照设定好的规则,自动抓取万维网数据信息的程序[4]。在大数据时代下,网络爬虫技术越来越成熟,在各个网站中都有非常深入的应用,对数据的分析有着至关重要的作用。通过爬虫技术实现数据获取,在海量的数据中精准获取所需要的信息,对数据进行分析和可视化,从而挖掘出数据背后隐藏的价值。
1.3Selenium框架
Selenium是早期常用于Web自动化测试的框架,是一种能够在网络爬虫中模拟真正用户操作的自动化技术[5]。不同于使用Requests库中的Get方法,使用Selenium框架进行爬虫有易于实现、方便简单的优势,还能够大大降低被服务器发现的可能[6]。
2爬取招聘数据
2.1Selenium爬虫设计
本文通过Selenium框架,对智联招聘网站进行数据的采集。首先,通过Selenium打开目标URL并登录,通过Xpath方法定位包含招聘信息的Html元素并提取目标数据,采集完一页数据后通过Selenium点击下一页,接下来开始循环遍历,最后采集完预先设定的页数后,将获取的数据写入并保存在CSV文件中,数据采集结束。设计流程如图1所示。

2.2具体操作步骤
2.2.1创建实例并访问URL
实例化Driver,通过Webdriver启动Chromedriver程序直接访问目标网站,并添加隐式等待,等页面元素稳定后进行下一步操作。
2.2.2定位并获取招聘数据
通过Xpath方法定位并获取招聘数据,其中包含岗位薪酬范围、学历经验要求和公司具体信息等数据,将获取的数据放在提前创建好的字典中,再写入CSV文件中,继续使用Driver自动点击下一页,调用for循环语句,循环采集数据和翻页操作。由于可能会因为网速等原因导致程序发生错误,因此在进行采集和翻页操作时,都需要用到try...except结构预防错误的产生。
2.2.3保存数据
最后将采集的4891条包含20个城市的数据在CSV中保存,并进行浏览器的销毁操作。部分数据如图2所示。

3数据预处理
3.1数据清洗
在进行数据分析之前,首先要进行数据清洗。数据中可能会出现重复数据、缺失值或者异常值,会影响后续的可视化分析。数据处理主要包括以下步骤:
3.1.1数据去重
使用drop_duplicates函数删除重复记录:
df.drop_duplicates(inplace=True)
3.1.2空值处理
数据中可能包含空缺值Nan,使用fillna函数用“无”等字符替换Nan,或者直接删除包含Nan的行数据:
df['address']=df['address'].fillna("['无']")
df.dropna(axis=0,how='any')
3.1.3异常数据处理
数据中可能包含异常数据,采用上四分位法将数据从小到大排列并分成四等份,检测并剔除掉离群值。部分代码如下所示:
sal_low=df['avg_salary'].quantile(q=0.25)
sal_high=df['avg_salary'].quantile(q=0.75)
sal_interval=sal_low-sal_high
3.2数据规范化
数据中可能包含影响数据可视化的中文字符或者其他字符,为了保证数据的规范化从而进行有效的可视化分析,需要将数据拆分并优化。例如:薪酬数据包含“千”“万”和“-”等符号,需要统一处理成阿拉伯数字,并统计平均工资、最高工资和最低工资。代码如下所示:
foriinrange(0,df.shape[0]):
t=df.loc[[i],['薪酬范围']].values.tolist()[0][0]ifre.search('(.*)-(.*)',t):
a=re.search('(.*)-(.*)',t).group(1)
ifa[-1]=='千':
a=eval(a[0:-1])*1000
elifa[-1]=='万':
a=eval(a[0:-1])*10000
b=re.search('(.*)-(.*)',t).group(2)
ifb[-1]=='千':
b=eval(b[0:-1])*1000
elifb[-1]=='万':
b=eval(b[0:-1])*10000
avg_salary=(a+b)/2
min_salary=a
max_salary=b
df.loc[[i],['平均薪资']]=avg_salary
df.loc[[i],['最低薪资']]=min_salary
df.loc[[i],['最高薪资']]=max_salary
4数据可视化
4.1一线城市分析
对北上广深四大一线城市的招聘数量具体分布情况进行分析,可视化结果如图3所示。
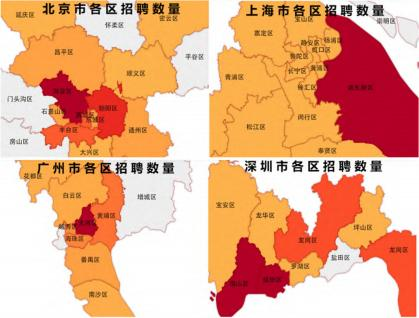
图3一线城市数量分布图
Fig.3Numberdistributionoffirst-tiercities

(1)北京市。北京市拥有着全国最多的大数据企业。2021年北京大数据企业共3531家,主要集中在北京市中心的海淀、朝阳和西城等区域,其中海淀区拥有优质企业1640家,占比近北京市优质企业的一半。数据分析结果显示,这三个地区对于大数据人才的招聘需求较大,特别是海淀区占比最大,这得益于北京大部分优秀互联网企业及院校主要集中在海淀区,有着较为扎实的技术基础和学术氛围。因此,大数据毕业生的就业规划可以将北京市海淀区作为首选。
(2)上海市。上海市是全国大数据产业发展的领先省份。上海市大数据的高速发展离不开市政府的高度重视,主要体现在市政府颁布的促进城市数字化转型和推动大数据应用发展等政策。2021年上海市大数据企业共1651家,主要分布在浦东新区、杨浦区和闵行区,其中浦东新区拥有优质企业417家。数据显示上海市对人才的需求主要集中在浦东新区,其他地区的需求量较为平均。因此,大数据毕业生未来的就业规划可以着重考虑在上海市浦东新区发展。
(3)深圳市。2021年深圳市共拥有大数据优质企业1346家,仅次于上海市,是我国数字经济发展的高地。2021年全年深圳数字经济核心产业增加值占GDP比重约30%,深圳数字经济规模和质量均位居全国大中城市首位。数据分析结果显示龙岗区招聘数量最多,其次是南山区和福田区,其中深圳龙岗区是广东省大数据综合试验区、深圳市数字经济强区。因此,大数据毕业生在未来就业选择时可以考虑在深圳市龙岗区发展。
(4)广州市。广州市正全面布局人工智能与数字经济“新赛道”,奋力迈向世界一流的数字经济示范区。2021年广州市共拥有大数据优质企业1051家,仅次于深圳市,广州市和深圳市都有较好的互联网发展基础,吸引着大量优秀大数据企业。数据分析结果显示天河区人才需求最多,而且第十次代表大会明确,天河区要打造人工智能和数字经济高地、产城深度融合典范。因此,大数据毕业生可以选择在广州市天河区发展。
4.2其他主要城市分析
数据分析得到招聘数量排名前10的城市(不包含北上广深四大城市)如图4所示,在各个城市的招聘需求中,杭州、成都和南京招聘数量位居前三甲,西安和武汉等城市次之。可以看出杭州、成都和南京三个城市对大数据相关专业人才需求量相对较大,在严峻的就业形式下也可以考虑在这三个城市寻找职位。
4.3岗位分析
数据分析得到各个岗位需求占比如图5所示,大数据开发工程师的需求占比最大,为63.9%,大数据分析师排在第二,占比为18.59%。大数据开发工程师岗位的需求远远大于其他岗位,因此从事大数据开发岗位的专业人才相对于其他岗位更容易找到工作。


4.4经验分析
数据分析得到经验要求占比如图6所示,大多数公司要求具备3~5年工作经验,占比46.66%,其次是1~3年工作经验,占比22.64%。相对于从事过相关岗位1~3年的专业人才,有3~5年经验的求职者更容易找到工作。
4.5薪资分析
数据分析得到平均薪资排名前10的城市如图7所示,北上广深的平均薪资水平都名列前茅,其中,北京的平均薪资最高。除了北上广深四大城市以外,南京和杭州的平均薪资也相对较高,对于薪资水平要求较高的大数据专业毕业生,可以重点考虑在北上广深四大城市寻找相关岗位,对于南京和杭州也是一个不错的选择。

4总结与建议
大数据时代已经到来,在具有大规模和复杂度的数据中精准挖掘其中蕴含的价值,能够带给个人宝贵的机遇。大数据的发展导致某些岗位必将被取代,但同时它也创造更多新的岗位[7]。大数据专业主要分为大数据管理与应用和数据科学与大数据技术,前者属于管理类专业,研究整体数据的管控和流程,毕业生需要掌握大数据分析方法以及相关前沿理论知识,该专业匹配数据分析师和商业智能分析师等岗位;而后者属于计算机类专业,研究底层技术及其实现,毕业生需要具备数据挖掘算法研究和大数据系统开发等能力,主要从事大数据开发、算法和研究类型等岗位。在当今大数据产业迅猛发展的时期,大数据学生要紧跟时代潮流,成为企业需要的大数据人才,才能在未来不被淘汰。大数据人才需求最多的地方集中在一线城市,二、三线城市的需求量也在逐年增多,大数据毕业生在一线城市更容易找到工作,也可以考虑在二、三线城市就业。同时,企业作为吸纳人才就业的主体,要将企业的需求精准对接就业市场,建立企业用人标准的模型,达到精准招聘大数据人才的目的[8]。在疫情防控期间,网络招聘也体现出较大的优势,能够尽量减少人员的流动,最大程度降低应聘者和企业工作人员感染疾病的风险[9]。本文通过对招聘数据的深入挖掘和大数据专业的分析,在当前严峻的就业形势下,为求职者和企业提供决策信息。尽管这些决策存在一定的可靠性和实用性,但总体上来说,数据分析结果还有很大的进步空间。期望本文的介绍能给大数据的同行学者和企业提供一定的参考。
参考文献
[1]王利明.数据共享与个人信息保护[J].现代法学,2019,41(1):45-57.
[2]孟宪颖,毛应爽.基于Python爬虫技术的商品信息采集与分析[J].软件,2021,42(11):128-130.
[3]龙卫球.再论企业数据保护的财产权化路径[J].东方法学,2018(3):50-63.
[4]潘晓英,陈柳,余慧敏,等.主题爬虫技术研究综述[J].计算机应用研究,2020,37(4):961-965+972.
[5]樊涛,赵征,刘敏娟.基于Selenium的网络爬虫分析与实现[J].电脑编程技巧与维护,2019(9):155-156+170.
[6]花君林.基于Selenium的Python网络爬虫的实现[J].电脑编程技巧与维护,2017(15):30-31+36.
[7]胡琼月.2018大数据人才就业热门职位和专业[J].大数据时代,2018(2):27-31.
[8]石云生,宗胜旺.构建大学生精准就业服务体系思考[J].合作经济与科技,2017(2):136-137.
[9]王伟玲,吴志刚.新冠肺炎疫情影响下数字经济发展研究[J].经济纵横,2020(3):16-22.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/45522.html






