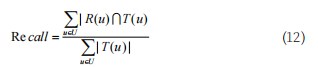SCI论文(www.lunwensci.com):
摘要:为给读者提供更加精准的推荐服务,提出了一种基于用户偏好行为数据的数字图书馆资源推荐方法。从用户对数字图书馆资源的偏好行为中提取浏览、评论、下载三种数据,结合用户资源评分,构建用户偏好行为数据推荐模型。在确定模型中参数取值以确保模型方法最优推荐精度后,与传统推荐方法进行实验比较。通过实验验证该方法模型在准确率、召回率方面均优于传统的协同过滤方法,有效解决了资源评分数据稀疏性的问题。
关键词:数字图书馆;推荐;协同过滤;用户偏好
Research on Resource Recommendation Method of Digital Library Based on User Preference Behavior Data
WANG Xiuhui1,ZHAO Zhijun2
(1.Institute of Education Science and Technology,Shanxi Datong University,Datong Shanxi 037009;2.Information Center of Datong People's Government,Datong Shanxi 037009)
【Abstract】:In order to provide readers with more accurate data recommendation services,a resource recommendation method of digital library based on user preference behavior data is proposed.Three kinds of data are extracted from users'preference behavior for digital library resources:Browsing,commenting and downloading.Combining the user preference behavior data score with the user resource score,the user preference behavior data recommendation model is constructed.After determining the parameter values in the model to ensure the optimal recommendation accuracy of the model method,the experiment is compared with the collaborative filtering method.The experimental results show that the proposed model is superior to the traditional collaborativefiltering method in terms of accuracy and recall rate,and effectively solves the problem of sparsity of resource rating data.
【Key words】:digital library;recommendation;collaborativefiltering;user preference
0引言
随着社会信息化程度的不断深化,数字图书馆资源呈几何递增,内容丰富、形式多样、数量巨大。但对于数字图书馆中的海量数据,用户却无法精准获取,致使用户接受信息数据内容出现严重失衡,服务体验质量差[1]。因此数字图书馆需提升自身服务水平,为用户推荐符合其个性化需求的资源[2],而个性化资源推荐的出现则正好解决了用户兴趣与数字图书馆资源信息过载的问题。
个性化资源推荐是通过用户对资源的行为,如浏览、评论、下载、收藏、保存等,来构建用户与资源之间联系,同时根据用户与资源之间联系的差异为其推荐不同的资源,以帮助用户从海量繁杂的数据中获取感兴趣的信息,满足不同用户的个性化需求,提高服务质量。目前,个性化资源推荐已成为数字图书馆领域重要的研究方向之一[3]。
1相关研究
随着数据信息服务进入个性化推荐时代,数字图书馆系统有必要紧跟时代要求,为用户提供精准的推荐资源服务。文献[4]提出一种面向研究人员的基于特性的模糊语言推荐系统。通过文献计量方法来量化项目和用户特性,并将测量的特性作为重新排名推荐列表的主要因素,以便向研究人员推荐其领域中最新和最好的资源。文献[5]在传统个性化推荐技术的基础上,结合用户社会关系中的感兴趣对象,提出一种基于用户社会关系的个性化推荐算法,较好的提高推荐质量。文献[6]提出一种基于高斯混合模型聚类技术的个性化推荐算法,解决数据稀疏性带来的问题,提高资源推荐结果的准确性。文献[7]为了提升个性化推荐服务质量,将序列中用户不感兴趣的资源过滤作为一个决策过程,创新性地引入一种强化学习方法作为推荐框架。此外,为克服用户获取资源行为的稀疏性问题,对于基于聚类的强化学习算法进行了改进。文献[8]挖掘目标用户历史数据获取与之相似用户以及相似借阅图书,结合图书推荐概率,提出一种基于主题模型的个性化图书推荐算法,解决了推荐精准度不高且时间复杂度较高的问题。文献[9]把标签频率与资源标注时间融合在一起,构建出用户资源评分矩阵,运用协同过滤算法,计算用户相似度完成个性化资源推荐。文献[10]把用户间相似度预先计算出来,推荐目标用户资源时会大大缩短时间、提升计算速度;同时又考虑到时间因素并赋予其权重,通过资源评分矩阵计算相似度会大大降低MAE值,解决目标用户兴趣随时间推移发生变化而导致资源推荐质量下降的问题。文献[11]在研究数字图书馆个性化资源推荐现状的基础上,提取图书馆用户画像特征数据,从而创建出用户画像模型。根据此模型设计出单用户与多用户两种个性化资源推荐模式,提高了资源精准推荐服务质量。文献[12]以数字图书馆社交网络为基础,寻找与目标用户社交密切且资源使用行为相似的用户,同时又结合资源访问时间和访问频率,提出用户近期个性化偏好因素的资源推荐机制,提高了适应用户个性化不断变化的趋势。文献[13]通过用户兴趣个性化特征来塑造用户个性化特征兴趣模型,进而提出基于用户个性化特征的图书馆书目推荐方法,并设计推荐模型,以此提高数字图书馆书目推荐的效率。文献[14]对高校图书馆用户历史数据进行数据挖掘获取用户借阅规律,并结合目标用户自身属性和其他用户需求特征选取因素,建立个性化资源推荐模型,构建以用户需求为内驱的差异化服务。文献[15]挖掘图书馆用户操作日志获取用户感兴趣资源数据,并实现量化。同时考虑到用户兴趣度会随时间变化,所以把时间函数纳入到计算公式中,最终得到自适应用户兴趣模型。其准确率、召回率等指标均高于传统的协同过滤推荐算法。文献[16]利用特征词分布、LD主题分布、引文结构网络三个维度构建资源模型,然后对用户浏览资源的兴趣度进行度量,利用度量值与资源模型相结合形成兴趣模型。通过此模型计算用户对资源的兴趣值,然后将兴趣值高的资源推荐给用户,个性化推荐效果显著。文献[17]以“国图公开课”数据资源池为背景,挖掘用户隐式兴趣信息特征且融入到个性化资源推荐服务中,改善原有用户兴趣矩阵稀疏问题引起的图书馆资源推荐不理想状况。文献[18]结合用户情境因素改进受限玻尔兹曼机算法,针对高校移动图书馆提出用户基于情境感知的资源个性化推荐模型。通过实验论证,具有较高的效率。文献[19]基于标签推荐算法与用户情感因素结合,提出一种复合情绪标签的资源推荐方法。先从复合标签和标签所处的情绪两个方面对资源进行标引,再使用先聚类、后分类计算相似度用户,最后完成个性化推荐。

综上所述,目前数字图书馆资源推荐的研究大多都是对协同过滤算法进行改进,进而完成用户个性化资源推荐。协同过滤算法主要是通过用户资源评分计算相似度,从而达到推荐的目的,其中评分是基础,决定着推荐系统的质量。但对于数字图书馆中的海量资源,用户只是对其一小部分进行了评分,大部分是没有进行评分的,这就导致了相似度计算失真、推荐资源不够精确、个性化推荐服务差的问题。本文从用户对数字图书馆资源操作的偏好行为出发(如:用户对资源的浏览、评论、下载、收藏等),构建用户偏好行为数据模型,实现对用户的资源推荐服务,以此提升推荐精度,并在一定程度上解决了用户资源评分的稀疏性与不完整性问题。
2数字图书馆用户偏好行为数据模型
基于用户偏好行为数据构建数字图书馆推荐模型,如图1所示。把数字图书馆用户偏好行为数据进行归一化与权重处理,构建用户偏好行为数据评分,同时结合用户资源评分,通过推荐引擎计算用户间相似度,然后按照Top-N规则形成推荐列表,让目标用户获取感兴趣的资源。
2.1数字图书馆用户偏好行为数据
数字图书馆用户偏好行为分为显性偏好行为和隐性偏好行为两种[20],其中显性偏好行为主要指用户在数字图书馆注册时填写的一些个人基本信息,如:姓名、性别、专业、职业、爱好与兴趣等;隐性偏好行为主要指用户在数字图书馆对需求资源所留下的隐性行为,如用户浏览、浏览时间、用户评论、下载等。显性偏好行为通常用户刻意去更改,因此不具备实时性,无法全面的、客观的反映出用户的偏好行为;而隐性偏好行为通常不是很稳定,是随着用户的兴趣爱好变化而改变,具有实时性、客观性等特点,能够全面的呈现出用户的兴趣,因此本文采用隐性偏好行为来度量用户兴趣。隐性偏好行为包含用户对数字图书馆资源的浏览、评论、下载、停留时间、收藏、分享等,其中浏览、评论、下载最能直观的体现出用户对资源的喜好,越感兴趣的资源,用户就会多次浏览、多次评论、多次下载,所以本文获取用户偏好行为包含用户浏览、用户评论和用户下载,用户偏好行为数据为:用户浏览次数、用户评论次数和用户下载次数,通过这些行为数据可以发现用户对资源的偏好规律而基于此进行推荐。当用户在浏览、评论和下载时,数字图书馆平台会自动跟踪并记录用户浏览次数、评论次数和下载次数偏好行为数据,基于偏好行为数据计算用户偏好行为数据评分。
2.2用户偏好行为数据评分
在确定浏览次数、评论次数和下载次数为用户偏好行为数据的基础上,计算用户偏好行为数据评分。浏览次数定义为B=(b11,b12,…bmn),其中bmn表示用户m对资源n的浏览次数;评论次数定义为C=(c11,c12,…cmn),其中cmn表示用户m对资源n的评论次数;下载次数定义为D=(d11,d12,…dmn),其中dmn表示用户m对资源n的下载次数。为计算用户偏好行为数据资源评分,使浏览次数、评论次数、下载次数具有可用性,使用归一化[21]方法进行数据标准化处理,如公式(1)所示:
式(1)中,X'表示评分,X表示次数,Xmin表示次数最小值,Xmax表示次数最大值,统一映射到[0,1]。进一步得到如公式(2)、公式(3)、公式(4)所示:
式(2)中,bck'表示用户c对资源k的浏览次数评分,
式(3)中,cck'表示用户c对资源k的评论次数评分,
式(4)中,dck'表示用户c对资源k的下载次数评分,最后得到用户c对资源k的用户偏好行为数据评分pck,如公式(5)所示:
通过公式(5)得到初步的用户偏好行为数据评分,但浏览次数、评论次数和下载次数对评分的贡献度是不相同的,因此需赋予不同权重,结合用户偏好行为数据权重对公式(5)进行改进,如公式(6)所示:
式(6)中,

,其中,ω1、ω2和ω3分别为浏
览次数权重、评论次数权重和下载次数权重。用户c对资源k的最终用户偏好行为数据评分pck'。
2.3用户相似度计算
推荐方法中,协同过滤方法应用最为广泛,它包括基于用户的协同过滤方法与基于项目的协同过滤方法。主要思想是根据项目评分计算用户间相似度或项目间相似度,从而根据相似用户或相似项目获取用户感兴趣的项目[22]。传统的相似度计算方法主要包括:余弦相似度、杰卡德相似度与Pearson相似度等计算方法[23]。
根据大量的相关文献研究,皮尔逊(Pearson)相似度计算方法更加准确,推荐结果更加精确[24],Pearson计算如式(7)所示:
式(7)中:Imn表示用户m与用户n共同评分资源集合,rm,i表示用户m对资源i的评分、rn,i表示用户n对资源i的评分;r表示用户m评分的平均值、r表示用户n评分的平均值;Sim(m,n)表示用户m与用户n之间的相似度,值越接近1说明用户m与用户n兴趣越相同。
根据公式(6)计算用户偏好行为数据评分,并借鉴公式(7)得出用户偏好行为数据相似度计算公式,如式(8)所示:
同时考虑用户资源评分与用户偏好行为数据评分,结合公式(7)与公式(8)获得用户相似度计算公式,如式(9)所示:其中w为参数,w∈(0,1),取值在实验中详细说明。Sim(a,b)能从整体上衡量用户之间的相似度。
3实验结果与分析
3.1实验数据集
实验选取某高校数字图书馆相关数据,并从数据集中随机选取80%评分数据作为训练集,20%作为测试集。实验分为两部分:一部分为测算公式(9)参数w在何种取值下会使得模型方法精度最高;另一部分是参数w确定取值后,与协同过滤方法实验比较。
3.2评价标准
评价推荐系统性能方法主要有平均绝对偏差MAE、均方根误差RMSE、准确率Precision和召回率Recall。它们有不同的侧重点,应用于不同的场景[25],其中MAE和RMSE主要应用于评分预测推荐场景,Precision和Recall主要应用于TOP-N推荐场景。本文参数w的取值选取平均绝对偏差MAE作为测评指标,而最终推荐结果以TOP-N列表反馈用户,通常选取准确率和召回率作为测评指标,计算公式如式(10)、式(11)、式(12)所示:
式(10)中:N表示资源集合,|xi−yi|表示预测评分与真实评分之间的绝对误差;式(11)与式(12)中R(u)表示推荐方法预测出用户u的资源集合,T(u)表示用户u在测试集中感兴趣的资源集合。
3.3 w的取值
参数w用于调节相似度计算结果的比重,如w=1则表示没有考虑用户偏好行为数据评分,即还是传统的协同过滤方法;w=0则表示没有考虑用户对资源的评分。针对w在不同取值情况下对推荐方法精度的影响,实验采用平均绝对偏差MAE作为评估标准。MAE算法其值越小,推荐质量越高[26]。该实验从数据集中选取1000、2000、4000、6000、8000个资源评分作为数据进行MAE实验,w从0开始,值每次增加0.2。如图2所示展示了w在不同的取值情况下MAE的变化。
从实验结果发现:MAE算法的精度跟随w值的变化而变化,其值过大或者过小都会使得效果不是最优,并且随着数据集的不断增大,MAE算法的值变化幅度却较小,逐渐趋于稳定。实验中当w=0.6时,MAE取值最低,模型方法推荐精度最高。
3.4实验结果对比
为验证本文模型方法的有效性,将与基于用户的协同过滤方法(UBasedCF)、基于项目的协同过滤方法(IBasedCF)进行对比实验。实验中参数w=0.6、Top-N中推荐数目N取值为{5、10、15、20、25、30、35、40}进行计算,观察准确率Precision和召回率Recall随着推荐数目N的变化而受到的影响,实验结果如图3、图4所示。
由实验结果可知:随着推荐数目N的不断变大,本文模型方法与其他两种方法在准确率方面都有所减小,而在召回率方面都有所增大。相对于UBasedCF与IBasedCF在N取值不断增大的情况下,本文模型方法的准确率下降幅度减小,召回率上升幅度增大,较上述两种方法的准确率和召回率都有所提升,说明本文提出的用户偏好行为数据模型方法要优于传统的协同过滤方法,提升了推荐精准度、提高了推荐质量,更好的满足了用户个性化推荐服务,且在一定程度上有效缓解了评分数据稀疏性的问题。
4结语
本文从用户对资源的众多偏好行为中抽取浏览、评论、下载三种并统计它们次数数据,同时实现量化。由于不同偏好行为数据对于计算用户兴趣影响程度不同,为其赋予不同的权重,进而构建用户偏好行为数据评分,且结合用户资源评分,重构相似度计算方法,按照Top-N规则形成推荐列表,形成了用户偏好行为数据模型。通过此模型实现用户资源推荐服务,让其获取感兴趣资源。为验证模型的性能,在参数定值后,与基于用户的协同过滤方法、基于项目的协同过滤方法进行实验对比,验证基于用户偏好行为数据的模型方法推荐更加精准,并且有效缓解了评分数据稀疏性的问题。然而该方法仍具有一定的改进空间:为提高相似度计算速率,偏好行为数据只包括了浏览、评论与下载三个方面,没有考虑其他用户偏好行为数据,如收藏、保存等,这使得数据信息内容不够全面。下一步将通过应用大数据技术来提升计算速率,把所有用户偏好行为数据都考虑在内,从而构建更加成熟完善的个性化推荐模型,使得推荐质量更加精确。
参考文献
[1]段尧清,刘宇明,蔡诗茜,等.数字图书馆个性化推荐用户信息采纳行为影响研究—信息采纳意向的中介效应[J].现代情报,2019,39(2):85-93.
[2]吴志强,马慧娟.协同信息推荐技术及其在数字图书馆中的应用研究述评[J].图书情报工作,2012,56(19):122-127.
[3]李春,朱珍民,叶剑,等.个性化服务研究综述[J].计算机应用研究,2009,26(11):4001-4005+4009.
[4]TEJEDA-LORENTE A,PORCEL C,BERNABE-MPRENO J,et al.REFORE:A Recommender System for Researchers Based on Bibliometrics[J].Applied Soft Computing,2015,30:778-791.
[5]FAN Yue-kun,LI Xin-e Li,GAO Meng-meng.Optimized Collaborative Filtering Recommendation Based on User's Social Relationships[J].Advanced Materials Research,2014:1044-1045.
[6]Cao Jian-hui,Guo Yan-lin,Dong Chun-xiang,et al.Personalized Recommendation for Digital Library using Gaussian Mixture Model[J].Journal of Networks,2014,9(10):2775-2781.
[7]WANG Xin-hua,WANG Yu-chen,GUO Lei,et al.Exploring Clustering-Based Reinforcement Learning for Personalized Book Recommendation in Digital Library[J].Information,2021,12(5):198.
[8]郑祥云,陈志刚,黄瑞,等.基于主题模型的个性化图书推荐算法[J].计算机应用,2015,35(09):2569-2573.
[9]曾子明,金鹏.基于用户兴趣变化的数字图书馆知识推荐服务研究[J].图书馆论坛,2016,36(01):94-99.
[10]朱白.数字图书馆推荐系统协同过滤算法改进及实证分析[J].图书情报工作,2017,61(09):130-134.
[11]王庆,赵发珍.基于“用户画像”的图书馆资源推荐模式设计与分析[J].现代情报,2018,38(03):105-109+137.
[12]王刚,郭雪梅.社交网络环境下基于用户行为分析的个性化推荐服务研究[J].情报理论与实践,2018,41(08):102-107.
[13]李萍,彭小华.基于读者个性化特征的图书馆书目推荐[J].现代电子技术,2018,41(17):182-186.
[14]赵雨薇.基于数据挖掘感知读者需求的高校图书馆差异化服务研究[J].图书馆工作与研究,2018(07):68-73.
[15]王刚.自适应用户兴趣偏好的电子资源协同过滤推荐研究[J].情报探索,2018(09):18-22.
[16]丁梦晓,毕强,许鹏程,等.基于用户兴趣度量的知识发现服务精准推荐[J].图书情报工作,2019,63(03):21-29.
[17]张华,魏大威.面向“国图公开课”的数字图书馆个性化信息推荐服务研究[J].图书馆学研究,2019(17):54-61.
[18]张潇璐,赵学敏,刘璇.基于情境感知的高校移动图书馆知识资源推荐研究[J].情报科学,2020,38(01):48-52+92.
[19]马晓悦,马昊.考虑标签情绪信息的图书资源个性化推荐方法研究[J].情报理论与实践,2020,43(09):115-124.
[20]熊拥军.数字图书馆个性化服务资源推荐模式分析[J].图书馆,2014(02):132-134.
[21]齐晶,刘瀛,刘艳霞,等.基于标签的协同过滤推荐方法研究[J].北京联合大学学报,2021,35(02):47-52.
[22]CACHEDA F,CARNEIRO V,FERNANDEZ D,et al.Comparison of Collaborative Filtering Algorthms:Limitations of Current Techniques and Proposals for Scalable,High-performance Recommender Systems[J].ACM Transactions ontheWeb,2011,5(01):3-35.
[23]王余斌,王成良,文俊浩.基于用户评论评分与信任度的协同过滤算法[J].计算机应用研究,2018,35(05):1368-1371+1402.
[24]孙华艳,李业丽,字云飞,等.协同过滤推荐算法的改进与研究[J].计算机技术与发展,2018,28(10):44-48.
[25]郭秋君.基于用户行为反馈的推荐算法的研究[D].北京:北京交通大学,2019.
[26]谢辉,李广建.移动社交网络推荐技术研究进展[J].情报科学,2017,35(10):3-6+67.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/41091.html