SCI论文(www.lunwensci.com):
摘 要:文章研究了聚类算法 K-means 和关联规则算法 FP-Growth,针对两种算法存在的不足,提出了对原始事务数据 库采用 K-means 凝聚层次算法按购物用户的属性特征进行聚类,并针对聚类压缩后事务数据库,利用矩阵存储数据并按支持 度计数排序,并将其应用于在线购物系统的个性化推荐中。算法的提出压缩了事务数据库,降低了生成频繁 1 项集的时间,减 少了 FP-Growth 算法扫描数据库的次数,提高了算法的执行效率。
关键词:K-means 算法 ;凝聚层次聚类 ;FP-Growth 算法
Research and Application of Improved FP-Growth Algorithm In Personalized Recommendation
LIU Yuebo, XU Tianxiang, XU Guoqing
(Jilin University of Architecture and Technology, Changchun Jilin 130114)
【Abstract】: This paper studies the clustering algorithm K-means and association rule algorithm FP-Growth. In view of the shortcomings of the two algorithms, it is proposed to cluster the original transaction database by AGglomerative NESting algorithm according to the attribute characteristics of shopping users. For the transaction database after clustering compression, the data is stored by matrix and sorted by support count, it is applied to the personalized recommendation of online shopping system. The proposed algorithm compresses the transaction database, reduces the time to generate a frequent items, reduces the number of times FP-Growth algorithm scans the database, and improves the execution efficiency of the algorithm.
【Key words】: K-means clustering;AGglomerative NESting algorithm;FP-Growth algorithm
1 关联规则
关联规则揭示了数据项间未知、隐含的依赖关系, 是数据挖掘中重要的挖掘方法之一,用于寻找给定数据 集中数据项之间有趣的关联或相关联系。利用挖掘出的 关联关系,可以根据一个数据对象的信息,推断出另一 个数据对象的信息 [1]。
1.1 关联规则的基本概念
关联规则 X → Y 的支持度为项集 X ∪ Y 的支持度 :Support(X → Y)=count(X ∪ Y)/count(D)
最小支持度 Minsup 是项集的最小支持阈值。
频繁项集是指 Support(x)>=Minsup 的项集, 否 则称为非频繁项集,长度为 k 的频繁集称为 k- 频繁集 [1]。
置信度 Confidence(X → Y) 表示 D 中包含 X 的事务 中有多少可能性也包含 Y,即表示规则确定性的强度 [1]。
Confidence(X → Y)=Support(X → Y)/Support(X) 表示关联规则 X → Y 的置信度。
最小置信度 Minconf 是由用户定义衡量置信度的 一个阈值。
强关联规则是指规则 X → Y 满足 Support(X → Y) ≥ Minsup, 同时满足 Confidence(X → Y) ≥ Minsup, 否则为弱关联规则。
1.2 FP-Growth 算法
FP-Growth 算法是由 Han 等提出的一种频繁模式 生长(frequent-pattern growth) 的分治算法 [2],该算法不使用候选集,通过 FP-tree 的构建和 FP-tree 的递归挖掘两步完成 [3]。首先进行 2 次扫描,将数据库压缩成 1 个频繁模式树 FP-tree,FP-tree 类似于前缀树,如果前缀路径相同,则可共用前缀,然后利用 FP-tree找到每个项的条件模式基,进而构建条件 FP-tree,最后在条件 FP-tree 上递归地挖掘出全部频繁项集。
(1)FP-tree 树的构建
输入 :事务数据库 DB ;最小支持度阈值 Minsup.
输出 :FP-tree 树。
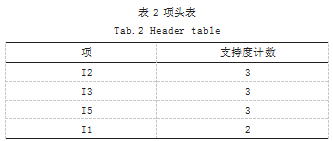
Step1 :第 1 次扫描事务 DB,汇总所有 1- 项集的支持度计数,并按支持度计数进行降序排列,进而得到项头表,形成 1- 频繁项表 L1[4]。
Step2 :创建 FP-tree 树的根结点 root,记为 null。
Step3 :第 2 次扫描事务 DB,按 L1 中项的顺序对 DB中的每个事务的项进行排序,得到频繁项集列表 T1。
Step4 :从 T1 中取出第一个元素 p,
Step4-1: 如果 FP-tree 树有孩子 N, 并且 N.name=p.name; 那么 N.count 加 1。
Step4-2: 否则,为根结点 root 创建一个新的子结点 N,并设置其计数为 1,并采用链表的方式将其链接到具有相同项名的结点。
Step4-3: 从 T1 中取出下一个元素,重复 Step4-1,
Step4-2,直到 T1 为空。
(2)基于 FP-tree 进行频繁模式挖掘
输入 :构造好的 FP-tree 树 ;事务数据库 DB ;最小支持度阈值 Minsup。
输出 :频繁模式完全集。
Step1 :针对每个项,生成其条件模式基,即从倒序取出项头表中的每个项,在 FP-tree 树中,寻找包含该项的路径。
Step2 :将条件模式基中每个模式视为一个事务,然后按 FP-tree 树的构造原则,构造一个条件 FP-tree 树。
Step3 :对每一个 FP-tree 树,
如果条件 FP-tree 树只包含单个路径 P,那么,对路径 P 中结点的每个组合 β,生成模式γ=β ∪ α(α 为后缀模式),使 Support(γ)= Minsupβ。
Step4 :否则,对于条件 FP-tree 树的项头表中的每个项 αi,
Step4-1: 生成模式 γ=αi ∪ α,其支持度 Support = αi. Support;
Step4-2: 构建 γ 的条件模式基,构建 γ 的条件 FP- tree 树 ;
Step4-3: 如果条件 FP-treeγ 树不为空, 则对模式 γ和条件 FP-treeγ 树重复 Step3 至 Step4。
2 聚类分析
2.1 K-means 聚类算法
该算法首先随机选取 K 个点,作为初始聚类中心, 通过计算各个对象到所有聚类中心的距离,以欧式距离 作为鉴定相似程度的标准,将对象归入到离它最近的那 个聚类中心所在的类,目标函数如下所示 :
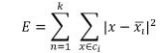
其中, E 是数据库中所有对象的平方误差总和, x 是空 间中的点,表示给定的数据对象, 是簇 ci 的平均值。
2.2 K-means 算法存在的问题
K-means 算法对于离群点和孤立点敏感 ;k 值选择 无法确定,必须首先给出 k(要生成的簇的数目),而 事先并不知道给定的数据应该被分成什么类别才是最优 的 ;初始聚类中心的选择,如果初始值选择不当,聚类 结果的有效性会受到很大的影响 ;只能发现球状簇。
3 算法改进
3.1 K-means 算法改进
针 K-means 算法的不足,对数据库中数据进行凝 聚层次聚类 (AHC),该算法属于无监督学习的一种聚类 算法,使用自底向上的策略,将对象组织到层次结构中。 凝聚层次聚类的思想是 :最初将每个对象作为一个簇, 然后按照相似性度量标准,按照数据相似度的高低,由 高到低的依次合并数据形成簇,随着簇的合并,簇间的相 似度逐渐降低,当达到给定的相似度阈值时,聚类终止。
首先将样本(e1,e2,e3,e4,e5,e6) 中每个数据视为一 个簇,然后根据相似性度量标准找到距离最短的两个簇 e2,e3 进行合并形成 E23, 则簇集合为 {e1,E23,e4,e5,e6}, 接着从当前簇集合中寻找距离最短的两个簇 e4,e5 进行 合并形成 E45, 从而得到新簇 {e1,E23,E45,e6}, 如果此 时达到给定的阈值 4,则聚类停止。
相似性度量标准采用欧式距离法 :
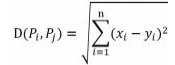
采用最短距离法(最大相似度)作为簇间距离度量 :Distmin(Ci,Cj)=min{|p-q|}(p ∈ Ci,q ∈ Cj)
算法执行实质是建立树型结构,如图 1 所示。
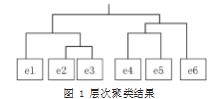
Fig.1 Hierarchical clustering results
3.2 FP-Growth 算法改进
扫描事务 DB,采用矩阵方式存储与项集关联的事 务 T,针对事务数据库中的所有 1 项集,将每个项集对 应的事务信息记录在 m×n 阶矩阵中,行代表项,列代表事务 [1],用“1”和“0”表示项 Ii 是否出现在 Ti 中, 通过计算矩阵中每一行中“1”的个数,即得到 Ii 的支 持度,根据矩阵中项的支持度计数进行降序排列,并删除不满足最小支持度计数的数据项,从而减少了扫描数 据库的次数节省了时间。
4 改进的 FP-Growth 算法在线购物系统中的应用
第一步,利用 K-means 凝聚层次聚类算法,先将 数据库中的每个对象作为一个簇,然后针对每个簇根据 某个邻近度量进行合并,通过反复聚类合并,最终所有 达到给定的相似度阈值,令所有对象满足要求,最后对 合并后的簇找出其具有代表性的数据,从而实现事务数 据库的压缩。
(1)筛选有用的用户的属性特征 :年龄、性别、职 业、学历等。(2)对数据进行正规化操作,即将所有属 性值映射到 [0,1] 区间。(3) 使用 K-means 凝聚层次 聚类算法,利用欧氏距离计算公式,将距离最短的两个 用户簇合并,然后再次从簇集合中寻找距离最短的两个 簇合并,循环直到有所用户都聚类完成,形成聚类树。 根据聚类树划分想要的 N 个聚类,当 cluster 数目变 化时,不用重新计算数据点的属于哪个聚类。(4)针对 每个聚类,根据商品出现的频次构造该聚类中的代表数 据,完成事务数据库的压缩。
第二步,针对聚类后得到的某一购物事务数据库 Di, 进行频繁项集挖掘, 其中 Di = {T1,T2,T3,T4 },Ti 代表 示不同顾客一次购物的集合。Di 中的 T 包含的项集 I = {I1,I2,I3,I4,I5 }, 如表 1 所示。最小支持度 Minsup=2。
(1)对事务数据库 Di,生成 5×4 矩阵。

(2)Ii 的支持度等于矩阵中每行“1”的个数,对矩 阵 M 按支持度计数降序排列,删除 Minsup<2 的项 I4。

(3)根据矩阵 M,构造项头表,如表 2 所示。
(4)构造 FP-Tree 树,并且基于 FP-Tree 树进行 频繁模式挖掘,最终得到所有需频繁项集,进而生成关 联规则。挖掘过程结果如表 3 所示。
5 结论
本文利用 K-means 凝聚层次聚类算法和改进的 FP-Growth 算法对购物数据库进行聚类分析和关联规 则挖掘,通过利用凝聚层次聚类算法对在线购物系统数 据库进行了聚类,然后针对 FP-Growth 算法存在的不 足,利用矩阵存储聚类后的事务数据库中的数据,通过 对事务数据库计算支持度,可快速求出频繁 1 项集,并 删除非频繁项,减少了扫描数据库的次数,提高了算法 的执行效率。
参考文献
[1] 刘玥波.改进的Apriori算法在个性化推荐中的应用[J].通讯 世界,2020(6):19-20.
[2] 郝志斌.应用Apriori算法和FP-tree算法挖掘关联规则的比较分析[J].中国科技博览,2011(3):49.
[3] 戴伟敏.基于Hadoop平台FP-Growth算法并行化研究与实 现[J].宁夏大学学报(自然科学版),2020(1):69-74.
[4] 石芹芹.基于FP树的极大频繁项集的挖掘方法[J].现代计算 机(专业版),2015(24):7-10.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/34276.html