SCI论文(www.lunwensci.com):
摘要:传统的车辆检测方法速度慢且准确率低,基于YOLOv4的算法准确率有所提高,但由于其计算参数量大和网络层数深,存在检测速度慢、对硬件要求高的问题。鉴于此,本文提出了一种改进YOLOv4的车辆检测方法。通过在网络中引入深度可分离卷积和Resblock结构,减少了YOLOv4冗余的参数量和网络层数,同时保持原来的梯度信息传递。实验结果表明,改进模型在保证高准确率的前提下,检测帧数提升72.5%。实际测试中mAP减少了3.2%,FPS提升了30.9%,对小目标的检测效果良好。改进的YOLOv4车辆检测算法有效改善了传统方法存在的检测速度慢和准确率低的问题,可满足对实时性要求较高的场景。
关键词:车辆检测;YOLOv4算法;深度可分离卷积;Resblock结构
Research of Vehicle Detection Application Based on Improved YOLOv4
ZHAO Libo,SHAN Jianfeng
(College of Electronic and Optical Engineering and College of Microelectronics,Nanjing University of Posts and Telecommunications,Nanjing Jiangsu 210023)
【Abstract】:The traditional vehicle detection method is slow and has low accuracy.Accuracy of the algorithm based on YOLOv4 is higher.However,due to its large amount of calculation parameters and deep network layers,it has the problems of slow detection speed and high hardware requirements.Considering this,this paper proposes an improved method of YOLOv4.By introducing deep separable convolution and Resblock structure into the network,the amount of redundant parameters and network layers of YOLOv4 are reduced,while maintaining the original gradient information transmission.The experimental results show that the improved model improves the number of detection frames by 72.5%on the premise of ensuring high accuracy.In the actual test,mAP is reduced by 3.2%,FPS is increased by 30.9%,and the detection effect of small targets is good.The improved YOLOv4 vehicle detection algorithm effectively improves the problems of slow detection speed and low accuracy of traditional methods,and can meet the scenes with high real-time requirements.
【Key words】:vehicle detection;YOLOv4 algorithm;depth separable convolution;Resblock structure
0引言
随着人工智能和辅助驾驶技术的快速发展,人们对行车安全的重视程度越来越高。借助车辆检测应用,计算机可以辅助驾驶员检测到出现在视野中的行人和车辆,甚至可以检测到视野盲区的小目标,这无疑提高了驾驶员的行车安全。车辆检测在智能交通领域也发挥着巨大作用,可以起到车辆追踪和交通流量监控的作用。近年来目标检测尤其是车辆检测的应用越来越广泛,也涌现出了多种改进的检测算法[1-2]。
目标检测算法经历了从人工特征提取到深度学习的发展,也从两阶段检测演变到一阶段检测,准确率和检测速度不断提升[3]。R-CNN[4]是第一个公开采取深度卷积神经网络解决目标检测问题的方法,是这一系列方法[5,6]的基础。该方法采用启发式搜索[7]技术提取图像中所有可能是目标的候选区域。然后用卷积神经网络提取这些候选区域的特征。最后用支持向量机对区域进行分类。一阶段的方法主要有SSD[8](Single Shot MultiBox Detector)和YOLO[9,10](You Only Look Once)系列。SSD采用了网格划分的思想,直接用一个卷积神经网络进行目标位置的预测和分类。YOLO算法去掉了R-CNN系列的提取候选区域步骤,直接得到目标的类别和矩形,在速度上达到了实时。整个框架只使用一个网络,同时完成目标位置的预测和分类。与基于滑动窗口、候选框的方法相比,对整张图像进行处理带来的一个好处是利用更大范围的图像语义信息,从而提高检测精度。
复杂的卷积神经网络模型层数深,存在计算参数量大的问题。很多高精度的检测模型依赖于高性能的图形处理器,检测帧数低于30FPS,难以达到实时处理图像的要求。本文基于YOLOv4[11]网络模型,在CSPDarknet53主干网络的基础上,用深度可分离卷积替代标准卷积并引入Resblock结构。改进模型的参数量大幅减少,在保持较高检测准确度的同时,极大地提高了检测速度。
1 YOLOv4算法
YOLOv4是对YOLOv3[12]的继承与发展,结合了最新的目标检测的技术。YOLOv4在损失函数、优化策略、数据处理、主干网络、训练方法和激活函数等多个方面作了优化。YOLOv4可以分为Backbone、Neck、Head三个部分,主要的改进也集中在这三部分。为了降低训练成本,YOLOv4也有改进,比如Mosaic数据增强;使用遗传算法优化超参数;类标签平滑;随机形状训练等。
1.1 Backbone
Backbone是主干网络部分。YOLOv3模型的主干特征提取网络使用Darknet53,而YOLOv4算法对Darknet53做了改进,借鉴了跨阶段局部网络[13](Cross Stage Partial Networks,CSPNet),形成了CSPDarknet-53的网络结构。很多深度卷积神经网络存在梯度信息重复计算的问题,CSP网络将梯度的变化集成到了特征图中,减少了网络的参数量,同时增强卷积神经网络的学习能力。这个结构从VGG模型的经典结构演化而来。YOLOv3引入了ResNet的Residual残差结构,将主干网络从19层加深到53层形成了Darknet-53网络。由于采用了残差结构,避免了深度网络梯度消失的问题,也减少了训练难度。
融合了CSP技术的YOLOv4主干网络的结构如图1所示。
1.2 Neck
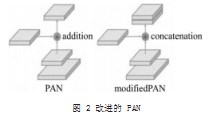
Neck作用是对特征进行融合或组合,将特征传递到检测网络层。Neck部分经常使用的结构有FPN[14](Feature Pyramid Networks),PANet[15](Path Aggregation Net),EfficientNet[16]。YOLOv4使用了PANet代替原来的FPN进行参数聚合,这样可以将不同尺寸的检测头用于检测。如图2所示YOLOv4算法将简单相加的融合方法改为concatenation,增强了模型的学习能力。
1.3 Head
Head是网络的检测部分,作用是生成边界框和进行检测。常用到的检测方法有R-CNN、Fast R-CNN等。YOLOv4的检测原理和YOLOv3一致,都是将输入图像划分为S×S个网格。以输入图像尺寸[416,416,3]为例,经过一系列卷积操作得到三个检测头,分别用以检测大中小三种尺寸的目标。三个检测头的维度分别为(52,52,3,K),(26,26,3,K),(13,13,3,K)。其中前两个维度是YOLO算法将输入图像划分成若干个网格的结果。维度“3”是指检测头在每个网格中都会生成3个先验框。维度“K”的计算过程如式(1)所示:
K=1+4+C(1)
(1)每个先验框会先判断出所在网格是否存在目标,返回1个参数;
(2)先验框会基于存在的目标大小调整自己的位置,返回(left,op,bottom,right)这4个参数;
(3)“C”的值代表需要检测的类别数为C个。先验框对每一类目标计算置信度,相当于判断为某类目标的概率大小,返回C个值。
2相关工作
2.1深度可分离卷积
标准卷积的卷积核是针对图片的所有通道设计的,每要求增加检测图片的一个属性,就要增加一个卷积核。所以对于标准卷积,参数量=属性的总数×卷积核大小。应用深度可分离卷积代替标准卷积可以减少网络参数量。深度可分离卷积可以分解为两步:逐通道卷积和逐点卷积。假设输入维度为W×H×C,卷积尺寸为WC×HC×C×N,C和N分别代表卷积核的通道数和个数。输出的特征图维度为WO×HO×N。那么标准卷积的参数量如式(2)所示:
WO×HO×N×WC×HC×C(2)
而对于深度可分离卷积,先用WC×HC×1×C的卷积进行逐通道卷积,再用1×1×C×N的卷积进行逐点卷积,参数量相加如式(3)所示:
WO×HO×1×WC×HC×C+WO×HO×N×1×1×C(3)两种卷积的参数量之比如式(4)所示:
1/(WC×HC)+1/N(4)
那么以本文输入(416,416)的三通道图片,卷积核大小3×3×3×320为例,参数量之比为:1/(3×3)+1/320。根据计算结果,应用深度可分离卷积可使参数量减少约83%。
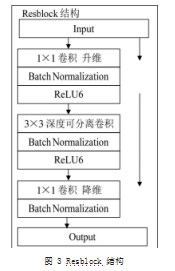
2.2 Resblock结构
Resblock的结构是对残差网络的一种改进,传统的残差网络就是直接丢弃部分网络层起到减少参数量的目的,但这种操作会带来特征信息丢失的问题,导致某些梯度信息不能传递。本文所使用的改进残差结构如图3所示。
左一路是主干部分,首先用1×1卷积进行升维,然后用3×3深度可分离卷积进行特征提取,最后用1×1卷积降维。右边是残差边部分,输入和输出直接相接。这个结构不同于简单的残差连接,可以连续传递梯度信息,不会导致提取到的信息丢失。
3基于YOLOv4的改进模型
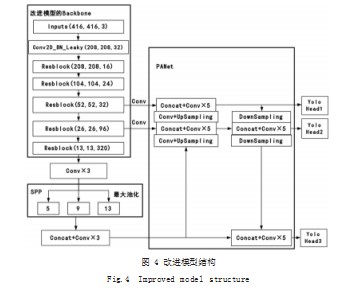
模型首先从主干网络进行改进,使用深度可分离卷积的结构使得模型参数大幅下降。改进模型的网络总层数为315层,总参数量为10,474,403。原YOLOv4模型的网络总层数为370层,总参数量为64,030,915。整体模型结构如图4所示。输入采用[416,416]的三通道图片,通过将标准卷积替换为深度可分离卷积的主干网络,得到不同维度的特征。图4中的Resblock结构块集成了深度可分离卷积、标准化以及ReLU6激活函数。DownSampling和UpSampling是下采样和上采样操作,上采样增加特征维度,下采样减小特征维度。经过上述操作不同维度的特征可以进行concatenation相连。改进前后模型的参数量和网络层数对比,如表1所示。
改进模型相较于原模型,网络层数减少了约15%,参数量减少了80%以上。
图4左上部分为模型的主干网络,由多个Resblock结构块组成。输入图像通过深度可分离卷积和Resblock结构的卷积运算输出三个特征,特征的维度分别为:
feat1:(52,52,32),
feat2:(26,26,96),
feat3:(13,13,320)。
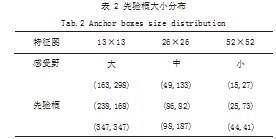
左下部分为SPP[17]结构(Space Pyramid Pooling),即空间金字塔池化网络。采用维度为5,9和13的最大池化进行初步特征融合,可以增大模型的感受野。右边部分为加强特征提取结构PANet,即路径聚合特征融合。经过这一步的操作可以得到三个用于目标检测的YOLO Head。每个YOLO Head使用三个先验框进行目标检测,先验框的生成使用K均值聚类[18]产生。代替人工设定的优点在于,针对不同数据集目标的特点产生最合理的先验框大小。YOLO Head和先验框的对应,如表2所示。
4实验
4.1实验环境和数据集
本实验基于云服务器运行,操作系统为Linux 64位系统。硬件环境为Intel(R)Xeon(R)Silver 4110 CPU 2.10GHz;内存:16GB;NVIDIA Geforce RTX2080Ti显卡,显存为11GB。软件环境为TensorFlow[19]2.3.0深度学习框架;Python 3.8;Cuda 10.1;Opencv_Python 4.2.0.34。为了充分发挥显卡的性能,调用了GPU并行训练。
实验需要检测行人及车辆类别共6类,分别为Car、Person、Motorbike、Train、Bus和Bicycle。实验基于VOC2007[20]数据集,这是一个在图像分类和计算机视觉方向常用的数据集,可以方便完成训练集、验证集和测试集的划分。实验共使用21504张图片,其中(训练集+验证集):测试集=9:1,训练集:验证集=9:1。输入图像尺寸采用[416,416,3]。首先创建三个文件夹,分别命名为Annatations、Images和ImageSets。Annatations文件夹用来存放格式为XML的标签,对应Images文件夹中存放的图片。ImageSets文件夹里分开存放测试集、验证集、训练集的图片名。训练时模型会读取标签中的矩形位置和大小信息,并调整网络的参数权重。
4.2评估指标
车辆检测任务关键的两个指标是检测准确度和检测速度,准确度用平均精准度(mean Average Precision,mAP)表示,检测速度依据每秒检测帧数(FPS)的值,是模型在1s内对样本图片可以检测的次数。本文还用到了精确率(Precision,P)指标。精确率是被分类器判定为正样本的样本中真正的正样本所占的比例,它可以反映分类器正确判定目标类别的能力。精度P定义如式(5)所示:
P=
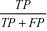
(5)
式(5)中TP是样本中正样本被分类器判定为正样本的数目,FP是负样本被判定为正样本的数目。计算mAP的步骤如下:
(1)计算单张图片中Car的精度P,本数据集默认IOU大于0.5即为分类正确。IOU定义为两个矩形的交并比,反映的是两个矩形的重叠程度,值越接近1说明检测效果越好;
(2)循环所有的测试集图片,重复(1)过程求出所有图片精度的平均值,即为类Car的AP;
(3)对剩余Motorbike、Train、Bicycle、Bus、Person5类重复(1)和(2)的过程;
(4)对6个类的AP求均值,即为实验的mAP值。
4.3模型训练
为了加快训练速度,实验的训练分为两个阶段。前一个阶段从1Epoch到50Epoch,为冻结阶段,此阶段模型的主干被冻结,特征提取网络不发生变化,仅对网络参数进行微调。后一个阶段为50Epoch到100Epoch,为解冻部分,此时模型的主干不再被冻结,特征提取网络会发生改变。解冻部分占用显存较大,网络所有的参数都会发生变化。模型的训练进程通过其损失函数变化显示。以训练原YOLOv4网络为例,如图5所示显示了整个训练过程中训练集和验证集的损失函数随训练时间的变化。
当损失函数趋于稳定,不再下降时,表示训练过程结束。训练结束可以得到一个权值文件,用该权重进行网络性能测试。
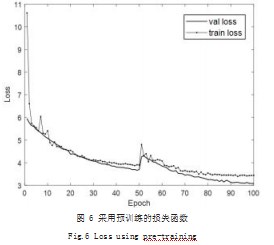
训练过程还采用了预训练[21]的方法,这也是加快训练的一种方法。首先,网络的层数越深,需要的训练样本就越大。基于VGG的网络权重数量庞大,十分消耗磁盘空间,训练速度也缓慢。其次,如果模型从零开始训练,一般权值太过于随机,特征提取效果不明显,训练效果会比较差。综上,采取预训练的方法十分必要。如图6所示为改进模型采用预训练方法的损失函数变化图。
对比图5和图6,采用预训练的模型,起初的损失函数值较小,损失函数下降较快,在很短的时间内就可以达到初步的训练效果。采用预训练可以加快模型收敛,降低训练的成本。
4.4实验结果
基于相同平台,原YOLOv4和改进模型在VOC2007数据集上进行车辆检测的性能如表3所示。
表3是改进前后的模型在测试集上的性能表现,对比了mAP、FPS和精度P的值。
为了验证实际的检测效果,用两张含有车辆和行人的图片对模型进行测试,用来模拟道路场景下的车辆检测。其中第二张测试图片验证模型对于小目标的检测能力,实际检测效果对比,如图7所示。
图7(a)、图7(c)是原YOLOv4模型的检测结果,图7(b)、图7(d)是改进模型的检测结果。图7(a)检测出10个目标,图7(b)检测出9个目标,包括Car、Person和Bicycle三类目标,改进模型几乎达到了原YOLOv4模型的效果;图7(c)、图7(d)均检测出五个车辆小目标,两个模型检测效果一致。
4.5实验分析
经过模型在测试集上的验证以及实际的检测效果对比,改进模型的mAP仅下降了3.2%,FPS提升了30.9%。精度仍维持较高水平,这说明模型的改进并未带来样本的误判。改进模型的优点十分明显,保证车辆检测的准确性前提下,检测速度提升了72.5%,训练成本也小得多。这得益于深度可分离卷积带来参数量的下降,以及Resbolck结构对梯度信息传递的保持,改进的网络在实时检测性能方面优于原来的模型,对于图像上小目标车辆和被遮挡目标也有不错的检测效果。
5结语
本文改进了基础的YOLOv4算法,并将其用于车辆检测领域。通过运用深度可分离卷积和改进残差网络的Resblock结构,大幅减少了参数量。在保持较高的检测准确度的同时,极大提高了检测速度。这种轻量化的模型在低时延和移动平台系统中具有一定的研究价值,能够满足某些场景的车辆检测需求。下一步研究将在检测头网络方面,目前主流的YOLO算法都是采用大中小三种检测头,缺少新颖有效的方法,这也是值得改进的一个切入点。
参考文献
[1]KALYAN S S,PRATYUSHA V,NISHITHA N,et al.Vehicle Detection Using Image Processing[C]//IEEE International Conference for Innovation in Technology(INOCON),2020:1-5.
[2]王周春,崔文楠,张涛.基于支持向量机的长波红外目标分类识别算法[J].红外技术,2021,43(2):153-161.
[3]雷明.《机器学习:原理、算法与应用》[J].自动化博览,2020(03):7.
[4]GIRSHICK R,DONAHUE J,DARRELL Tet al.Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[C]//IEEE Conference on Computer Vision and Pattern Recognition,2014:580-587.[5]GIRSHICK R.Fast R-CNN[C]//IEEE International Conference on Computer Vision,Santigago,Chile,2015.[6]REN S Q,HE K M,GIRSHICK R,et al.Faster R-CNN:Towards Real-time Object Detection with Region Proposal Networks[J]IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[7]UIJLINGS J R R,VANDESANDE K E A,GEVERS T,et al.Selective Search for Object Recognition[J],International Journal of Computer Vision,2013(2):154-171.
[8]LIU W,ANGUELOV D,ERHAN D,et al.SSD:Single Shot MultiBox Detector[C]//European Conference on Computer Vision.Springer,Cham,2016.
[9]REDMON J,DIVVALA S K,GIRSHICK R,et al.You Only Look Once:Unified,Real-time Object Detection[C]//Computer Vision&Pattern Recognition.IEEE,2016.
[10]REDMON J,FARHADI A.YOLO9000:Better,Faster,S tronger[C]//IEEE Conference on Computer Vision and Pattern Recognition(CVPR),2017:6517-6525.
[11]BOCHKOVSKIY A,WANG C Y,LIAO MARK H Y.YOLOv4:Optimal Speed and Accuracy of Object Detection[J].2020.
[12]REDMON J,FARHADI A.YOLOv3:An Incremental Improvement[J].2018.
[13]WANG C Y,MARK-LIAO H Y,WU Y H,et al.CSPNet:A New Backbone that Can Enhance Learning Capability of CNN[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops(CVPRW),2020:1571-1580.[14]LIN T Y,DOLLAR P,GIRSHICK R,et al.Feature Pyramid Networks for Object Detection[J].IEEE Computer Society,2017(09):21-26.
[15]LIU S,QI L,QIN H F,et al.Path Aggregation Network for Instance Segmentation[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition,2018:8759-8768.[16]TAN M X,LE Q V.EfficientNet:Rethinking Model Scaling for Convolutional Neural Networks[J].2019.
[17]HE K M,ZHANG X Y,REN S Q,et al.Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015(9):1904-1916.
[18]顾晋,罗素云.基于改进的YOLO v3车辆检测方法[J].农业装备与车辆工程,2021,59(7):98-103.
[19]韩卓.TensorFlow平台目标检测模型的设计与实现[D].北京:北京邮电大学,2019.
[20]EVERINGHAM M,ESLAMI S M,GOOL L,et al.The Pascal Visual Object Classes Challenge:A Retrospective[J].International Journal of Computer Vision,2015,111(1):98-136.
[21]庄福振,罗平,何清,等.迁移学习研究进展[J].软件学报,2015,26(1):26-39.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/40992.html