SCI论文(www.lunwensci.com):
摘要:本文讨论面向服务体系架构(Service Oriented Architecture,SOA)中对于已有系统中的业务进行分析,使用服务识别方法(Service Identification Method),识别出可用系统服务,同时给出了服务质量的计算方式。结合新业务的发生,使用服务识别方法,以服务质量作为参考指标,将服务的寻找转换为使用集合匹配的方式,找到相似度高的服务。以此实现SOA中服务复用的目的。
关键词:SOA;服务识别;服务质量;集合相似度
Research on SOA Service Identification Method
ZHANG Yicheng,NI Feng
(University of Shanghai for Science and Technology,Shanghai 200093)
【Abstract】:This paper discusses the Service Oriented Architecture(SOA)in the existing system business analysis,using the service identification method,identify the available system services.At the same time,the calculation method of service quality is given.Combined with the occurrence of new business,the service identification method is used and the service quality is taken as the reference index to transform the service search into the collection matching method tofind the service with high similarity.This enables service reuse in SOA.
【Key words】:SOA;service identification;service quality;set similarity
0引言
在系统设计的层面,SOA思想与如今快速发展微服务架构成为系统架构设计的适合选择。微服务架构需要保证不同服务之间的数据一致性,引入了分布式事务和异步补偿机制,为设计和开发带来一定挑战。对于中小企业来说,微服务,云端服务架构并不适用,其系统复杂,运维困难,开发难度大。其本身业务复杂程度,选择不合适的架构只会增加实施成本和实施难度。SOA架构成本较低,实施高效,是首选。
对于新构建SOA架构的企业来说,必然涉及对遗留系统的评价和理解。遗留软件系统迁移到SOA是困难的导致它取决于许多因素,例如迁移过程的选择,服务识别方法,所生成的服务的所需质量特征。评估遗留系统识别出可用的服务是使遗留功能复用的第一步,也是搭建SOA必要的过程。
1研究现状
由于Service Identification Approaches(SIAS)的重要性及其对系统迁移成功的影响,Manel Abdellatif等人[1]研究归纳了多种用于识别遗留系统服务的方法。然而,适用于所有其他SIAS中的某些从业者的SIA的选择是困难的,并且取决于若干因素,例如可用的传统工件,分析这些传统工件的过程,可用输入,所需输出和方法的可用程度。SIAS仍处于初期阶段。这是由于四个主要的特性:(1)缺乏对真实企业级系统的验证;(2)缺乏工具支持;(3)缺乏SIAS自动化;(4)缺乏评估所确定的服务质量。Rana Yousef等人[2]使用类图和用例模型用于分析,设计面向对象系统的系统模型。提出了一种方法来识别来自一组类图和使用案列模型的服务,以便生成面向服务的模型。所生成的服务符合面向服务的架构原理。但其没有将业务流程进行中存在的顺序关系,数据流动关系,过程进行考虑。服务识别方法分为基于遗留系统的自底向上的方法,分析业务需求过程的自顶向下的方法记忆综合上述两种观点的中间相遇的方法。对于识别出的服务应当进行评价,满足低耦合性、高内聚性、粒度大小合适、可复用、可组合等[3]。
2遗留系统服务识别方法
2.1遗留系统模块
系统架构技术的发展趋势主要包括在以下三个方面:(1)软件架构技术平台轻量化。(2)软件架构技术智能化。(3)软件架构技术实时化[4]。
遗留系统具有如下特征:(1)业务逻辑复杂,维护难;(2)架构陈旧且高度耦合;(3)开发人员流动性对系统影响大;(4)系统文档缺失;(5)业务逻辑与代码逻辑较为混乱[5]。通过SOA架构的思想,考虑将遗留系统里功能或组件分成不同的模块,将遗留系统中的功能模块包装成服务,是实现可复用功能的重要步骤。
遗留系统往往具有确定的功能模块,一个功能模块可以继续分割为多个子模块,而分割的次数,为分析遗留系统的粒度。使用SOA架构进行软件开发,前提是对业务流程和服务进行建模[6],其困难点之一就是粒度的划分,如何将服务在某种粒度下划分的系统模块中进行寻找可用的功能,即是服务识别的目的。
2.2划分粒度
SOA系统的服务由粗粒度和细粒度共同组成,粗粒度服务,可以看作是若干细粒度服务依照业务逻辑组合,细粒度服务则是业务流程步骤的简单映射,若系统架构过多依赖细粒度服务,虽能保证架构的灵活性,但单个细粒度服务的功能性不强,完成复杂的业务逻辑往往需要内聚多个细粒度服务,并通过多次服务请求实现互操作。反之,单纯的粗粒度服务模型在业务能力的表达上虽优于细粒度服务,但由于自身业务封装的复杂性而难以适应需求的变化[7]。
由于对遗留系统的可查性,每个任务限定为对某一模块的某一个增删改查操作,以此可作为最小粒度下的服务划分。为SOA架构设计提供前提,以便清晰得进行服务划分,完整的表达每个任务所做的事情,也可以提高服务匹配的精确性。
2.3流程图与数据流图
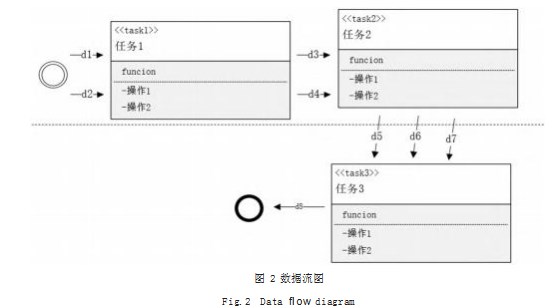
使用BPMN规范得定义由多个任务模型构成得业务流程,包括由流程开始,中止,业务运转控制,流程分支等操作。所有操作结合,则可以组成一个完成得业务流程,其单独的每一个task按照某业务的运行步骤来完成,其涵盖某个业务的前后执行,操作顺序。每一个任务之间,存在数据传递和数据运算,如图1所示。
数据流图分析关注的重点是数据,将面向控制的信息作为数据进行处理,包括了系统的所有数据,能准确的抽象系统数据的流向和处理过程,概括的描述当数据在系统流程中流动和处理的移动变换过程。
系统被严密的展开,系统的框架就展现出来了。采用数据流图进行分析,可以提高分析的可见性和可控性,更容易理解软件要完成什么功能,数据的来源,经过,输出,一目了然,为后续服务识别中的指标计算提供必要前提,如图2所示。
2.4服务划分
因为每个任务可以单独存在,也可以进行顺序组合成为更大的任务。划分规则以每一个任务为服务,再以相邻的两个或多个为服务划分得到服务S1(t1),S2(t2),S3(t3),S4(t1t2),S5(t2t3),S6(t1t2t3),每个服务中的task之间存在顺序关系,表达了一个服务中所执行的一个或多个任务组成的一个抽象任务,抽象任务中包含了每个任务所完成的事件,数据处理,且具有顺序关系。每个抽象服务存在被打包封装为一个完成功能的潜力,进而被各系统或其他功能模块调用,识别出高质量,高复用性的服务,是搭建SOA架构的核心。
2.5服务与功能模块CRUD矩阵
对于系统功能模块来说,每个任务从数据上,都会存在CURD中一个或多个操作,这些操作修改了库存信息或者新增删除了库存信息,进而完成一套完整业务,其中单个任务同样对数据信息进行了查询或处理。
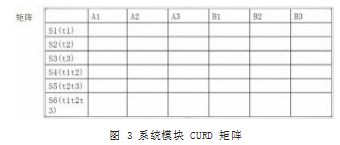
建立CRUD矩阵,行为划分的服务,其中包含具体任务,列为遗留系统中的实体模块。
如图3所示中系统A,B遗留模块分为A1,A2,A3,B1,B2,B3,抽象服务集合为{S1,S2,S3,S4,S5,S6},S1包含的任务{t1},S2包含的任务{t2},S3包含的任务{t3},S4包含{t1,t2},S5包含{t2,t3},S6包含{t1,t2,t3}。每一个任务又由操作模块及操作为一个元素构成,进而将服务继续分解为,模块+操作作为元素,构成抽象服务集合。
3服务质量与服务匹配
3.1内聚度与耦合度
数据流图分析关注的重点是数据,将面向控制的信息作为数据进行处理,包括了系统的所有数据,能准确的抽象系统数据的流向和处理过程.概括的描述当数据在系统流程中流动和处理的移动变换过程[8]。
系统完整地经历一个业务流程,要先后通过n个功能模块的数据交换来实现。定义系统中某一流程的所需功能集合Task_flow={task1,task2,……taskn},流程开展过程中某一功能taski进行数据交换,所涉及的数据的集合定义为Data(taski),相关数据集又分为输入数据集和输出数据集,分别写作Input_data(taski)和Output_data(taski),即Data(taski)=Input_data(taski)∪Output_data(taski)
系统中通过某一流程的数据内聚度Coh(S)为:
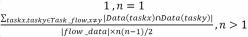
其中n为完成该流程所需功能的个数,|Data(taskx)∩Data(tasky)|表示功能taskx与功能tasky之间交换数据的数据集,|flow data|表示在执行这一流程中所用到的数据集。
根据公式,当流程中没有数据交换关系时,功能内聚度Coh(S)为0,流程中只一个功能,即当n=1时,系统的内聚度为1;当系统流程执行多个功能时,功能之间交换的数据元素个数越多,所属系统的内聚度越大。
软件的耦合度是软件中各个构件之间相互关联程度的一种度量。构件间接口的复杂性,数量,调用方式及传送数据的数量,分析过程,都与耦合的强弱有关[8]。从系统,模块,操作三个层级去评价两个任务之间耦合性,如下:操作不同系统>操作相同系统;所操作的模块:操作不同模块>操作相同模块;进行非查询操作>进行查询操作。
服务集合中的子任务属性Ti(Si:A.Mi:A1,Oi:C);Tj(Sj:A,Mj:A2,Oj:U)
Si表示任务所属系统,Mi表示任务所属模块,Oi表示对模块进行的操作,包含查询R和非查询(CUD)NR操作,无顺序关系任务之间所有操作可能的对应如表1所示:
当两个任务属于同一系统,同一模块时,耦合度低,当两个任务对同一系统的不模块操作时,耦合度低,当两个任务对不同系统的模块操作时,耦合度高,当执行只查询R操作时,耦合度低,执行CRD操作时,耦合度高。
耦合读计算逻辑如下
if Si=Sj and Mi=Mi then//系统和模块都相同coupling(TiTj)=2
else if Si=Sj and Mi!=Mj//系统相同模块不同if O(TiTj)=R_R then//都为查询操作coupling(TiTj)=3
if O(TiTj)=R_NR or O(TiTj)=NR_R then//存在1各个非查询操作
coupling(TiTj)=4
if O(TiTj)=NR_NR then//两个都是非查询操作coupling(TiTj)=5
else if Si!=Sj//系统不同
if O(TiTj)=R_R then
coupling(TiTj)=6
if O(TiTj)=R_NR or O(TiTj)=NR_R then coupling(TiTj)=7
if O(TiTj)=NR_NR then
coupling(TiTj)=8
end if
end if
end if
计算耦合度公式如下
Couping(S)=
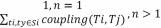
其中,n为服务S包含的对模块进行的操作数量,coupling(Ti,Ty)为可执行函数,计算Ti,Tj之间的耦合度。当n=1时,耦合度为1。N>1时,对两两操作计算耦合后相加得到服务耦合度。
以内聚度作为分子,耦合度作为分母。当内聚度越大时,服务质量越高,当耦合度越大时,服务质量越低[9]。服务的质量指标公式QS(Quality of Service)如下:
QS(S)=Coh(S)/(Couping(S)
其中Coh(S)为定义计算服务的内聚度的公式;Couping(S)为定义计算耦合度的公式。
以此作为计算服务质量的公式,当识别出系统服务后,通过计算,得到服务质量的评价。
3.2集合匹配
把服务抽象为一个集合,其中的元素为服务中包含的顺序组合的任务,而每个任务中的元素包含对系统模块的操作。服务集合:S{task1,task2,task3….},元素构成T{module(A)+operation(C/U/R/D),T{module(b)+operation(C/U/R/D)},元素由模块+操作。
相似度的概念已被广泛应用到计算机领域[10]。到系统服务的匹配上,A,B代表服务中的操作集合,分子为两服务中存在对于相同模块进行相同操作的集合子元素数量,分母为两服务的所有对于不同模块进行的不同操作的集合子元素数量,通过计算得到两个服务相似程度,相似度高的,可以被复用的可能越大。同时,对于两个相似的服务,进而对其中的功能进行整理,从功能层面出发,将业务所涉及的功能整理,达到服务复用以及优化功能的目标。
4结语
本文针对SOA架构下的服务识别方法进行了研究,并给出了划分服务的方法。服务识别在SOA架构中具有很大的意义,SOA是一种高内聚低耦合的设计思想,将功能定义为一个服务被调用。但现实中很多遗留的系统,并没有融入整个系统架构中,那么通过服务识别的方法,识别出一些高质量的服务,即高内聚、低耦合,两种属性作为服务的参考。当开展新业务时,寻找相似度高,且高质量的服务,有利于快速开发新功能,节省开发成本、人力成本等。但对于粒度的划分,包括选择粒度的计算公式,服务划分的粒度没有明确的计算方法,对于服务集合的相似度没有计算公式。这部分有待继续研究。
参考文献
[1]Abdellatif Manel,Shatnawi Anas,Mili Hafedh,et al.A Taxonomy of Service Identification Approaches for Legacy Software Systems Modernization[J].Journal of Systems and Software,2021(Mara):1-22.
[2]Rana Yousef,Omar Adwan,Mohammad A M.Abushariah.Extracting SOA Candidate Software Services from an Organization's Object Oriented Models[J].Journal of Software Engineering and Applications,2014(9):770-778.
[3]SUDHAKAR K,STEPHEN M J,REDDY P.Cloud Oriented Integrated Composite Services over SOA in Distributed Computing[J].International Journal of Engineering and Advanced Technology,2021,10(3):52-58.
[4]任丹.浅谈软件架构发展现状及其发展趋势[J].信息记录材料,2020,21(6):5-6.
[5]林平荣,施晓权,杨俊钦,等.大型遗留系统的性能与安全优化[J].计算机系统应用,2020,29(10):103-108.
[6]李志华.基于架构层级的软件架构模式划分与研究[J].电脑知识与技术,2021(23):60-61.
[7]李健龙.基于SOA的遗留系统复用框架研究[J].飞航导弹,2018(6):26-30.
[8]罗爱民.信息系统体系结构设计中系统内聚度分析方法[J].国防科技大学学报,2010(5):118-122.
[9]刘帅华,王天青.企业传统应用架构向微服务架构转型的一种流程设计[J].研究与设计,2021(10):105-107.
[10]林学民,王炜.集合和字符串的相似度查询[J].计算机学报,2011,34(10):1853-1862.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/40648.html